
LV005-GPU简介
这节我们来看看什么是 GPU。
一、概述
随着大模型产业的发展,AI 训练 & 推理对算力的需求越来越大,AI 的计算也越来越离不开 GPU 的支持。
目前,用于 AI 计算的芯片可以分为:
- CPU(通用处理器);
- GPU(通用图形处理器);
- NPU / TPU(AI 专用处理器)。
二、并行的概念
| 串行(Sequential/Serial) 一个处理器按顺序处理每一个任务 |  |
| 并发(Concurrent) 指一个处理器同时处理多个任务。 | 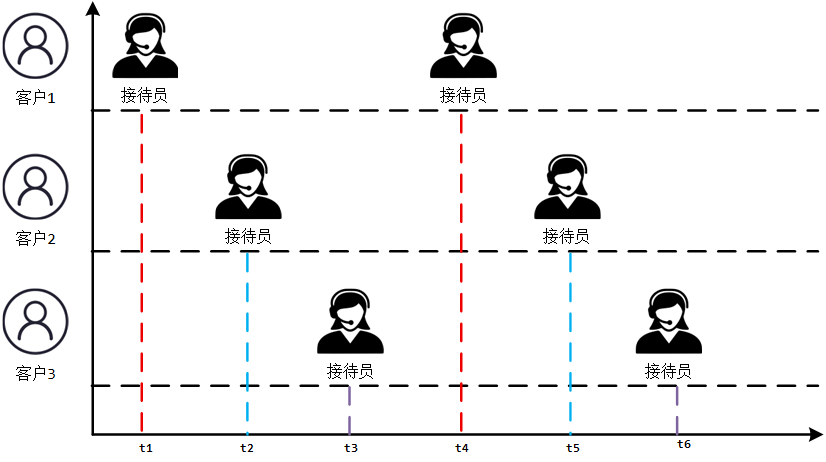 |
| 并行(Parallel) 多个处理器或者是多核的处理器同时处理多个不同的任务。 |  |
- 串行(Serial):就是只有一个处理器,每次只处理一个任务,这个任务处理完了才能处理下一个任务。
- 并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。当有多个线程在操作时, 如果系统只有一个 CPU, 则它根本不可能真正同时进行一个以上的线程, 它只能把 CPU 运行时间划分成若干个时间段, 再将时间段分配给各个线程执行, 在一个时间段的线程代码运行时, 其它线程处于挂起状态.
- 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
三、CPU 与 GPU
1. CPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。中央处理器 (CPU) 由数十亿个晶体管构成,可以拥有多个处理核心,通常被称为计算机的“大脑”。
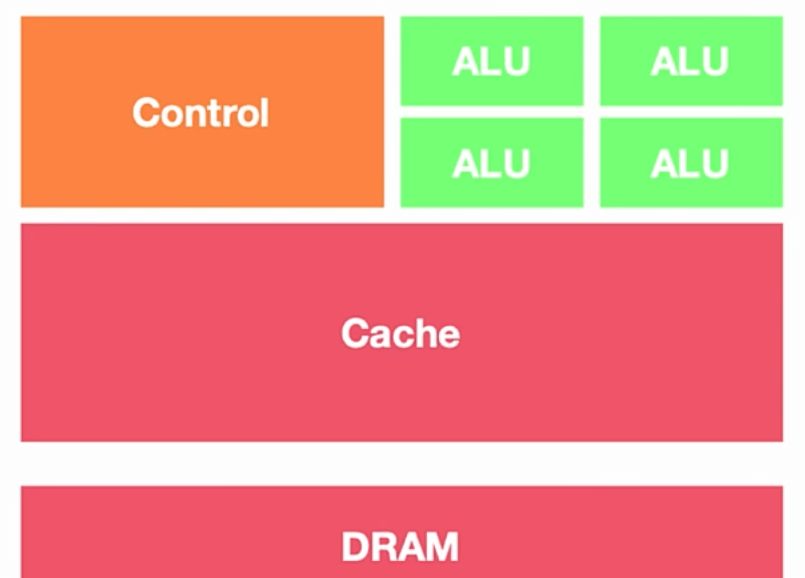
可以形象的理解为有 25%的 ALU(运算单元)、有 25%的 Control(控制单元)、50%的 Cache(缓存单元)。
2. GPU
GPU:叫做图形处理器。图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
图形处理单元 (GPU) 具有许多更小、更专业的核心。这些核心协同运行,并将处理任务同时(即并行)划分给许多核心,从而提供强劲的性能。GPU 擅长处理高度并行任务,例如在游戏过程中渲染视觉效果,在内容创作过程中操纵视频数据,以及在密集型 AI 工作负载中计算结果。
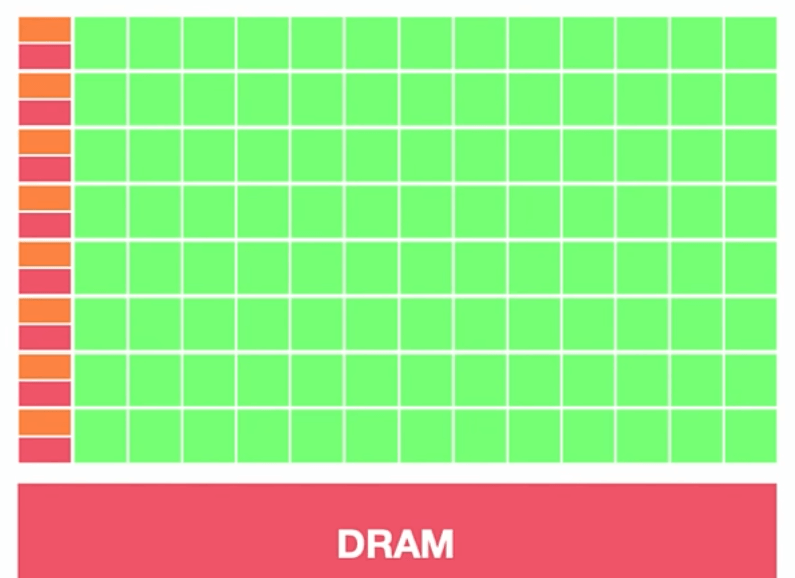
可以形象的理解为 90%的 ALU(运算单元),5%的 Control(控制单元)、5%的 Cache(缓存单元)。
3. 有什么区别
从硬件设计上来看,GPU 的 DRAM 时延(数据搬运、指令执行的延迟)远高于 CPU,但 GPU 的线程数远高于 CPU(有非常多的线程,为大量大规模任务并行而去设计的)。
- CPU:降低延迟、并发(Concurrency,能够处理多个任务的功能,但不一定是同时),可能更希望在一个线程里完成所有的工作(串行,优化线程的执行速率和效率);
- GPU:最大化吞吐量、并行度(Parallelism,同时可以执行多少任务)。利用多线程对循环进行展开,来提高硬件整体的利用率。
4. 总结
| CPU(Central Processing Unit) | GPU(Graphics Processing Unit) |
| ■ “全能战士” ■ 通用和复杂计算/逻辑处理、控制流… ■ 少量复杂核心、复杂控制单元、低延迟… | ■ “流水线工人” ■ 相对简单的大量数据并行 ■ 大量简化核心、极简控制单元、高吞吐… |
 Intel Core i7 | 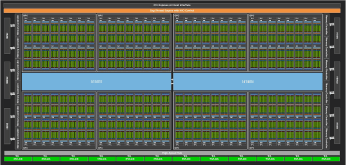 NVIDIA A100 |
四、CUDA 简介
1. CUDA 是什么?
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的一个并行计算平台和编程模型。它允许软件开发人员和研究人员利用 NVIDIA 的 GPU(图形处理单元)进行高性能计算。CUDA 提供了一系列 API 和工具,使得开发者能够编写和优化在 GPU 上运行的计算密集型任务。
2. 发展历史
GPU 最初的使命是加速图形渲染。而渲染一帧图像,本质上就是对数百万个像素点进行相似的计算,这天然就是一种大规模并行任务。
2001 年,NVIDIA 发布 GeForce 3,首次引入 可编程着色器 (Programmable Shaders)。 实质上允许开发者为 GPU 编写软件,让 GPU 的 众多并行处理单元 去同时执行,以精确控制光照和颜色如何加载到显示器上。这是朝着加速计算方向迈出的重要一步,因为它允许开发者直接为 GPU 编写软件。
一批敏锐的研究人员意识到,GPU 的本质就是一个拥有数百甚至数千个核心的大规模并行架构,其浮点运算吞吐量远超当时的 CPU。他们的核心想法是:能不能用 GPU 进行科学计算? 开始探索利用 GPU 计算科学计算问题,从而利用 GPU 的算力。这便是 GPGPU(通用计算 GPU)的萌芽。但是门槛非常高, 需要开发者同时精通图形学和科学计算。
NVIDIA敏锐地捕捉到了GPGPU的发展潜力,开始不再局限于加速图形渲染,主动拥抱GPGPU。2006年,发布了第一款为通用计算设计的统一架构GPU - GeForce 8800 GTX 显卡(G80架构)。它将GPU内部的计算单元统一起来,形成了一个庞大的、灵活的并行核心阵列,为通用计算铺平了硬件道路。
2007年,NVIDIA正式推出了CUDA平台。CUDA 的革命性在于,它提供了一套简单的编程模型,让开发者能用近似 C 语言的方式,轻松地驾驭 GPU 内部成百上千个并行核心。 开发者无需再关心复杂的图形接口,可以直接编写在数千个线程上并发执行的程序。至此终结了 GPGPU 编程的蛮荒时代,让 GPU 计算真正走下神坛,成为开发者触手可及的强大工具。
五、GPU 的架构
我们这部分参考:nvidia-ampere-architecture-whitepaper.pdf
1. GPU 的硬件单元
打开 nvidia-ampere-architecture-whitepaper.pdf 的第 20 和 22 页,有如下两张图:
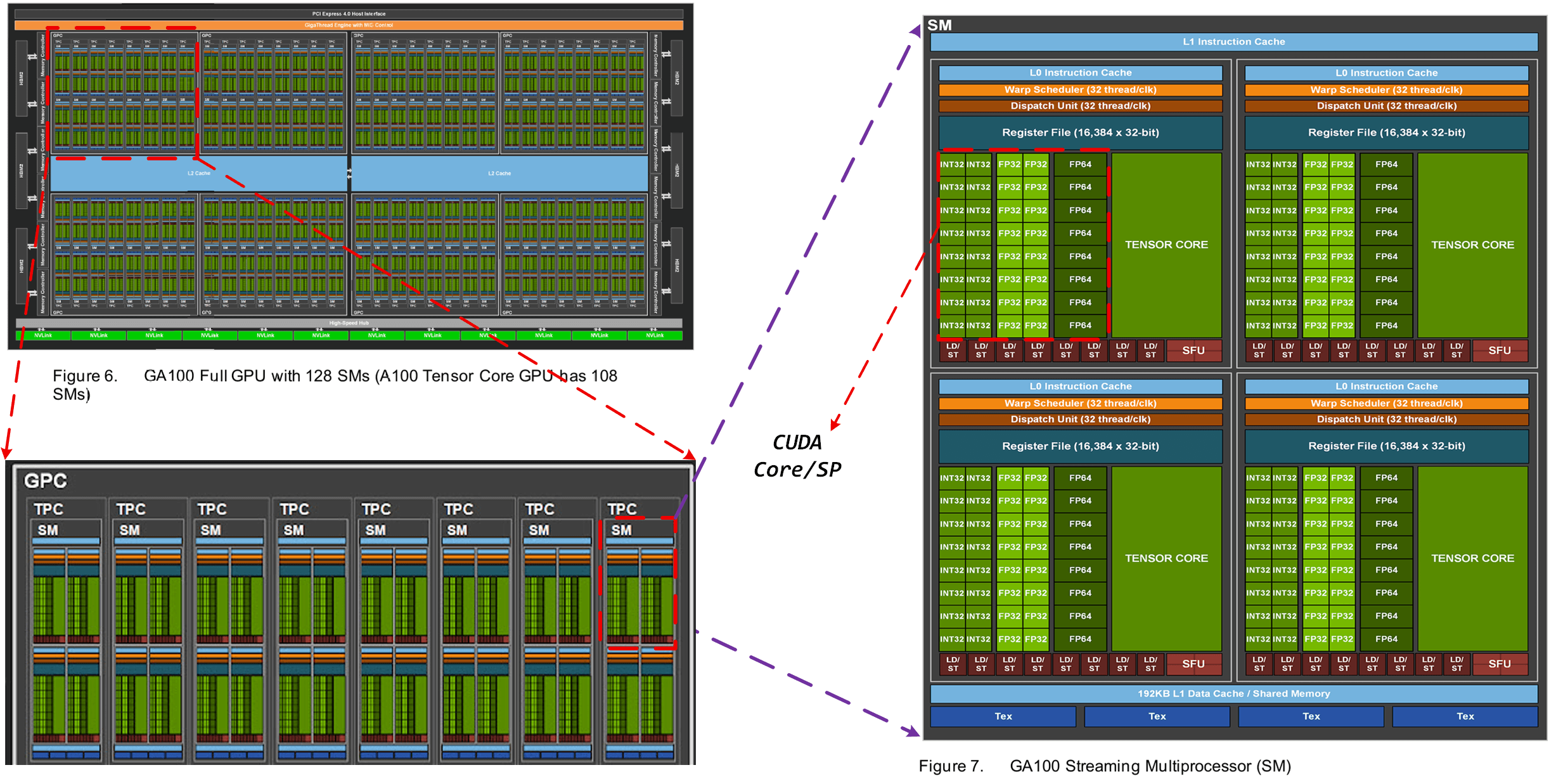
从这里,我们可以知道,在 GPU 的硬件架构中,包含以下单元:
- GPC:Graph Possessed Cluster,图像处理簇。GPC 负责处理图形渲染和计算任务。每个 GPC 包含多个 TPC,以及与其相关的专用硬件单元和缓存。
- TPC:Texture Possessed Cluster,纹理处理簇。TPC 负责执行纹理采样和滤波操作,以从纹理数据中获取采样值,并应用于图形渲染中的相应像素。
- SM:Stream Multiprocessors,流式多处理器。SM 是是 GPU 的主要计算单元,负责执行并行计算任务。每个 SM 都包含多个流多处理器(CUDA Core/Tensor Core/RT Core 等 ),可以同时执行多个线程块中的指令。SM 通过分配线程、调度指令和管理内存等操作,实现高效的并行计算。
- HBM:High Band Memory,高带宽处理器。
一个 GPC 包含多个 TPC,一个 TPC 包含多个 SM,一个 SM 包含多个 Block、Thread 以及各种 CUDA Tensor Core。
1.1 SM
SM(流式多处理器)的核心组件包括:CUDA 核心、共享内存、寄存器等,它包含许多为线程执行数学运算的 Core,是 NVIDIA 的核心,每一个 SM 都可以并发地执行数百个线程。具体地,SM 包括以下单元:
- CUDA Core:向量运行单元(FP32-FPU、FP64-DPU、INT32-ALU);包含了一个整数运算单元 ALU (Integer Arithmetic Logic Unit) 和一个浮点运算单元 FPU (Floating Point Unit) 。后来称为SP,SP就是CUDA Core的前身。
- Tensor Core:张量运算单元(FP16、BF16、INT8、INT4,专门针对 AI 的矩阵计算);Tensor Core 之所以计算效率高是因为硬件层面实现了 4x4x4 的矩阵乘法运算。
- Special Function Units:特殊函数单元,SFU,超越函数和数学函数;
- warp Scheduler:线程束调度器;
- Dispatch Unit:指令分发单元;
- Multi Level Cache:多级缓存(L0/L1 Instruction Cache、L1 Data Cache & Shared Memory);
- Register File:寄存器堆;
- Load/Store:访问存储单元(LD/ST,负责处理数据)。
后来,CUDA Core 演变为了单独的 FP32、FPU、INT32-ALU。
1.2 Tensor Core
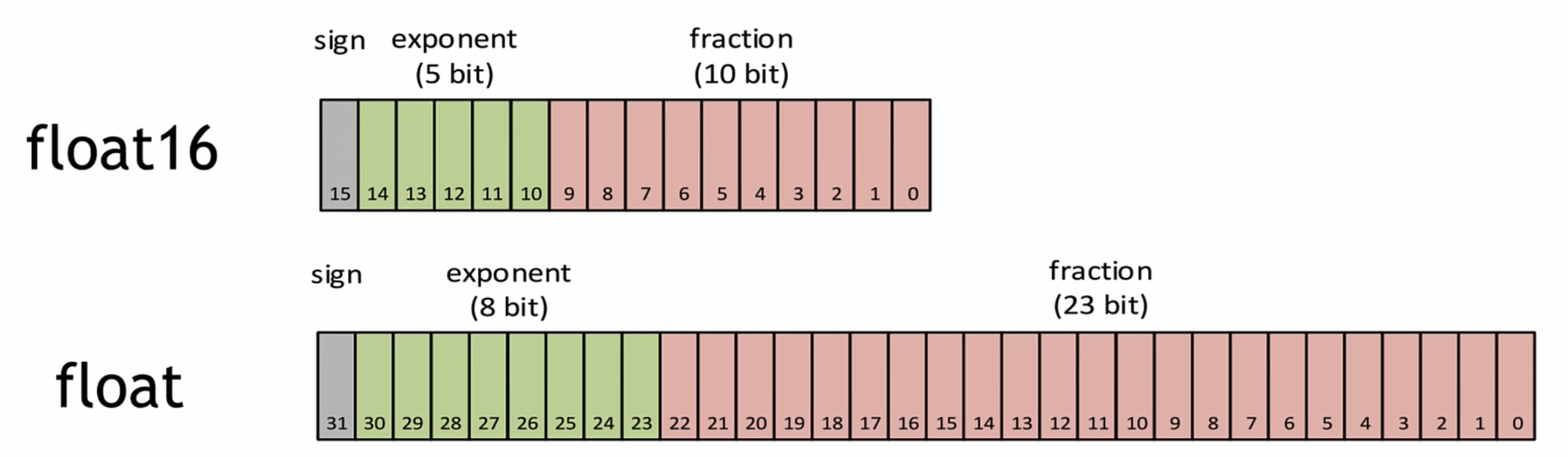
Tensor Core 可以支持混合精度运算。混合精度是指在底层硬件算子(Tensor Core)层面,使用半精度(FP16)作为输入和输出,使用全精度(FP32)进行中间结果计算从而不损失过多精度的技术。
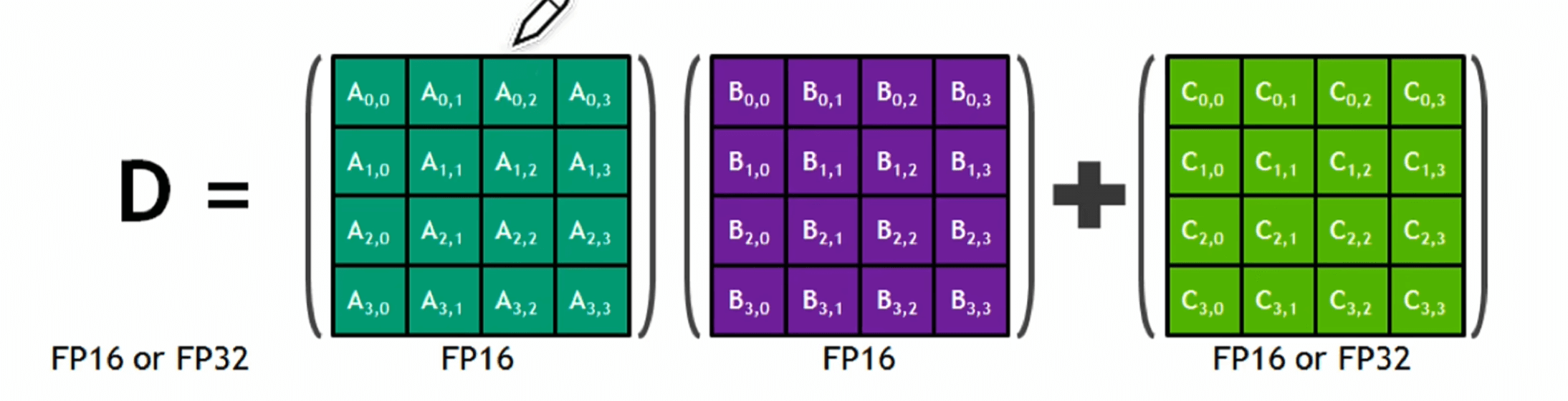
每个 Tensor Core 每周期能执行 4*4*4 GEMM,即 64 个 FMA。
Tensor Core 可以通过 Warp 把多个线程聚合起来一起进行计算和控制。最终对外提供一个 16*16*16 的 API 给到 CUDA。
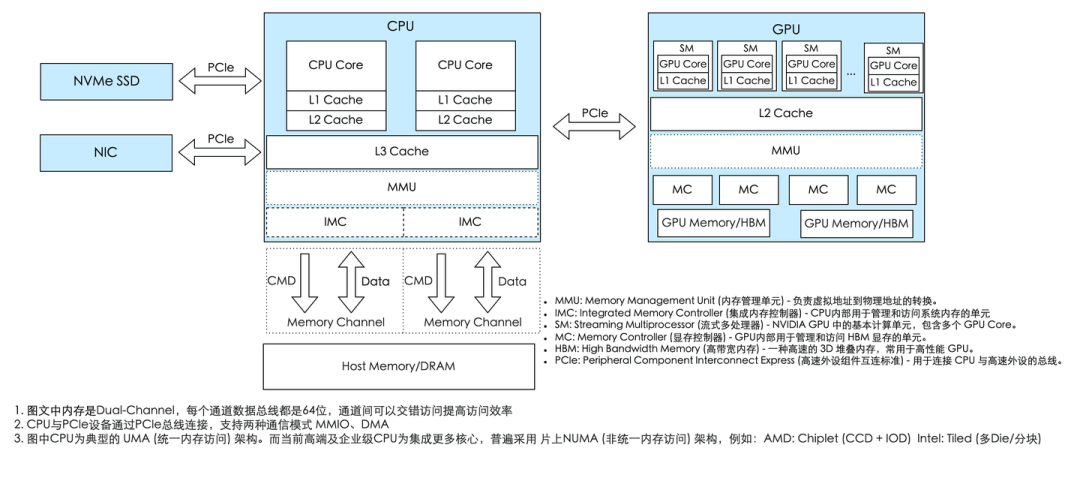
2. 与CPU的交互
CPU是整个系统的核心,是总指挥,GPU的任务指令是由CPU分配的。CPU通过PCIe总线给GPU发送指令和数据交互。而PCIe支持DMA和MMIO两种通讯模式:
- MMIO(内存映射I/O)由CPU直接控制数据读写,操作系统会把设备地址映射到CPU的虚拟空间中,适合小数据量的指令交互
- DMA(直接内存访问)则允许设备绕过CPU直接访问系统内存,专为大数据块的高效传输设计。
CPU通过IMC和Memory Channel访问内存,为了提升数据传输带宽,高端CPU通常会支持多内存通道,即多IMC和Memory Channel的组合,以满足日益增长的数据处理需求。
参考资料:
nvidia-ampere-ga-102-gpu-architecture-whitepaper-v2.1.pdf
nvidia-ampere-architecture-whitepaper.pdf
CUDA C++ Programming Guide — CUDA C++ Programming Guide
GPU Performance Background User's Guide - NVIDIA Docs
Evolution of the Graphics Processing Unit (GPU) | IEEE Journals & Magazine | IEEE Xplore
每个程序员都应该了解的 GPU 工作原理:从硬件到架构-腾讯云开发者社区-腾讯云
每个程序员都应该了解的GPU工作原理:从硬件到架构,大模型入门到精通,收藏这篇就足够了!_gpu架构与编程 赵地-CSDN博客