
LV040-Hash表
一、Hash表简介
前面介绍了三种查找方法,但是都是需要经过大量的比较。其实理想的查找方法是:对给定的 k ,不经任何比较便能获取所需的记录,其查找的时间复杂度为常数级 O(C) 。这就要求在建立记录表的时候,确定记录的 key 与其存储地址之间的关系 f ,即使 key 与记录的存放地址 H 相对应:

当我们需要查找 key = k 的记录时,通过关系 f 就可得到相应记录的地址而获取记录,从而免去了 key 的比较过程,这个关系 f 就是所谓的 Hash 函数(或称散列函数、杂凑函数),记为 H(key) 。 H(key) 实际上是一个地址映象函数,其自变量为记录的 key ,函数值为记录的存储地址(或称 Hash 地址)。
不同的 key 可能得到同一个 Hash 地址,即当 keyl != key2 时,可能有 H(key1) = H(key2) ,此时称 key1 和 key2 为 同义词。这种现象称为 冲突 或碰撞,因为 一个数据单位只可存放一条记录。选取 Hash 函数只能做到使冲突尽可能少,却不能完全避免。
根据选取的 Hash 函数 H(key) 和处理冲突的方法,将一组记录

二、Hash 函数构建
在设计哈希函数时,要尽量地避免冲突现象的发生。常用的 Hash 函数构造方法有这几种:直接定址法、数字分析法、平方取中法、折叠法、随机数法和除留余数法。
1. 直接定址法
直接定址法的 Hash 函数是一次函数:
其中 H(key) 表示关键字为 key 对应的哈希地址, a 和 b 都为常数。
例如,很多时候我们接受了服务后,都可能会对客服做评价,评价分数为 60 、 70 、 80 、 90 、 100 这几个层次,通过直接定址法建立 Hash 表:
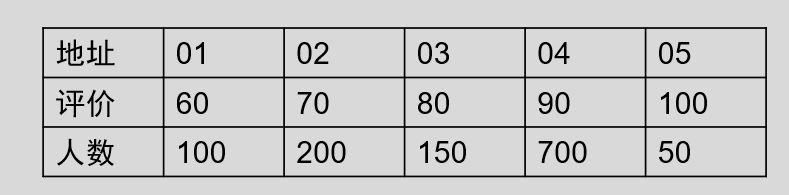
现在我们要查找 90 分的人数,那么我们带入 90 到 Hash 中,会直接得到其 Hash 地址 04 (求得的哈希地址表示该记录的位置在查找表的第 04 位)。
2. 数字分析法
如果关键字由多位字符或者数字组成,就可以考虑抽取其中的 2 位或者多位作为该关键字对应的哈希地址,在取法上尽量选择变化较多的位,避免冲突发生。
例如,下图为一组数据的部分关键字,他们都是由 10 位十进制数(全为 0-9 )组成的:
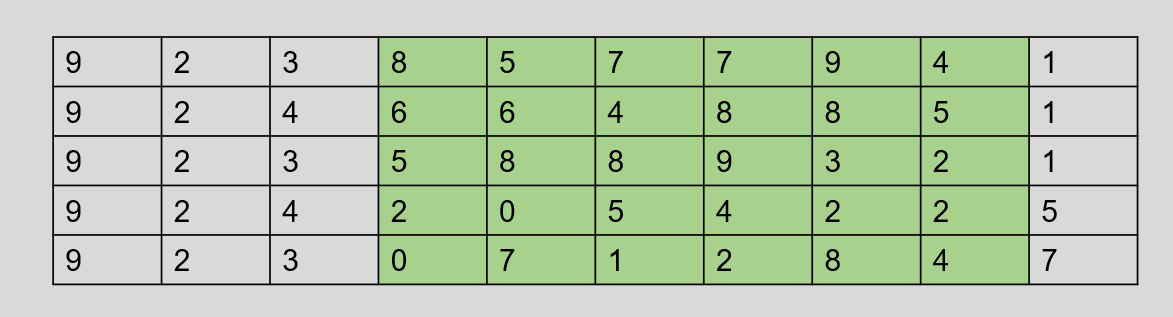
通过分析关键字的构成,很明显可以看到只有中间绿色部分取值近似随机,所以为了避免冲突,可以这一部分中任意选取 几 位作为其哈希地址。
3. 平方取中法
平方取中法就是对关键字做平方操作,取中间得几位作为哈希地址。例如,

可以看到平方后开头两位各不相同,于是可以取开头两位作为其 Hash 地址。
4. 折叠法
折叠法是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。折叠的方式有两种,一种是移位折叠,一种是间界折叠。
例如,图书馆某本书的编号为 0-520-1314-5 ,则有:

移位折叠就是将分割后的每一小部分,按照其最低位进行对齐,然后相加;间界折叠是从一端向另一端沿分割线来回折叠。
5. 随机数法
随机数法就是取关键字的一个随机函数值作为它的 Hash 地址,即: H(key)= random(key) ,此方法 适用于关键字长度不等 的情况。这里的随机函数其实是伪随机函数,随机函数是即使每次给定的 key 相同,但是 H(key) 都是不同,而伪随机函数正好相反,每个 key 都对应的是固定的 H(key) 。
6. 除留余数法
若已知整个 Hash 表的最大长度 m ,可以取一个不大于 m 的数 p ,然后对该关键字 key 做取余运算,即: H(key) = key % p 。例如,
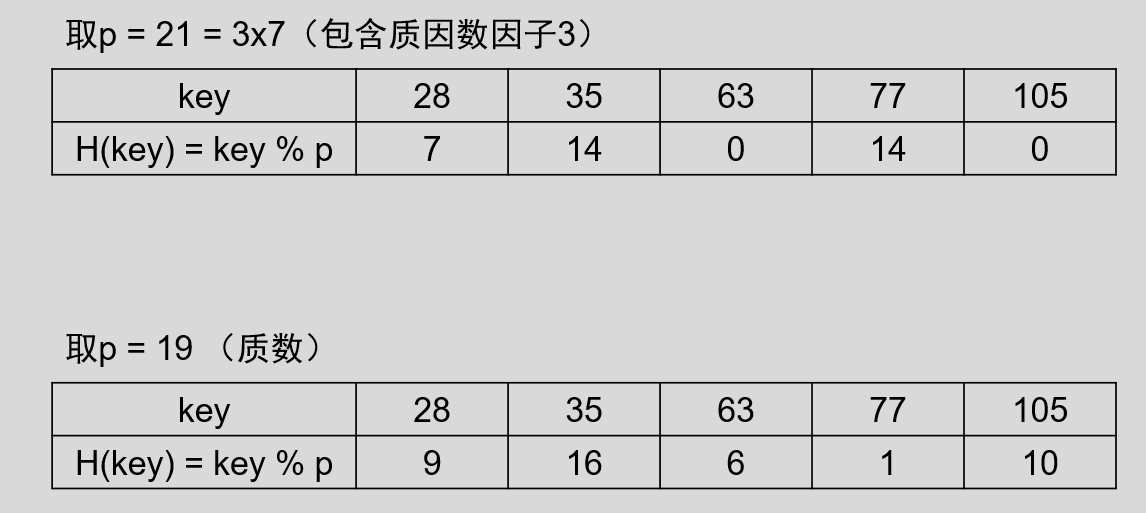
由上图可知, p = 21 时,包含质数因子 7 的 key 都可能被映象到相同的单元,冲突现象严重。当 p = 19 时, H(key) 的随机度就好多了。
【注意】对于 p 的取值非常重要,一般来说 p 可以为不大于 m 的质数或者不包含小于 20 的质因数的合数。
三、冲突处理
选取随机度好的 Hash 函数可使冲突减少,一般来讲不能完全避免冲突。设 Hash 表地址空间为 0~m-1 (表长为 m ):

表中某地址
处理冲突的方法一般为:在地址 j 的前面或后面找一个空闲单元存放冲突的记录,或将相冲突的诸记录拉成链表。在处理冲突的过程中,可能发生一连串的冲突现象,即可能得到一个地址序列
还有一个重要的因素是表的 装填因子 α , α = n / m ,其中 m 为表长, n 为表中记录个数。一般 α 在 0.7~0.8 之间,使表保持一定的空闲余量,以减少冲突和聚积现象。
1. 开放地址法
当发生冲突时,在 H(key) 的前后找一个空闲单元来存放冲突的记录,即在 H(key) 的基础上获取下一地址:
其中 m 为表长, % 运算是保证
(1)线性探测法:
(2)二次探测法:
(3)伪随机数探测法:
- 实例
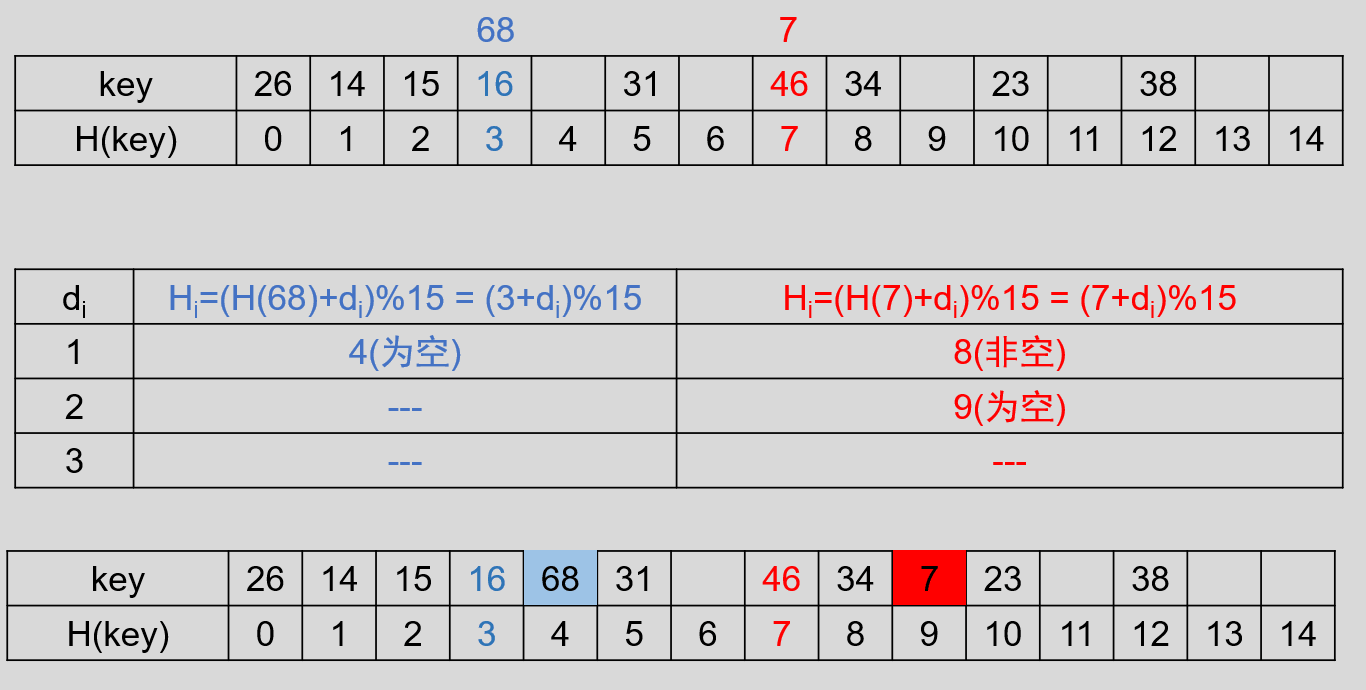
设记录的 key 集合 k = {23, 34, 14, 38, 46, 16, 68, 15, 7, 31, 26} ,记录数 n = 11 ,令装填因子 α = 0.75 ,则表长 m = [n / α] = 15 ,使用除留余数法选取 Hash 函数,取 p = 13 ,则 H(key) = key % 13 ,建立 Hash 表,则有:
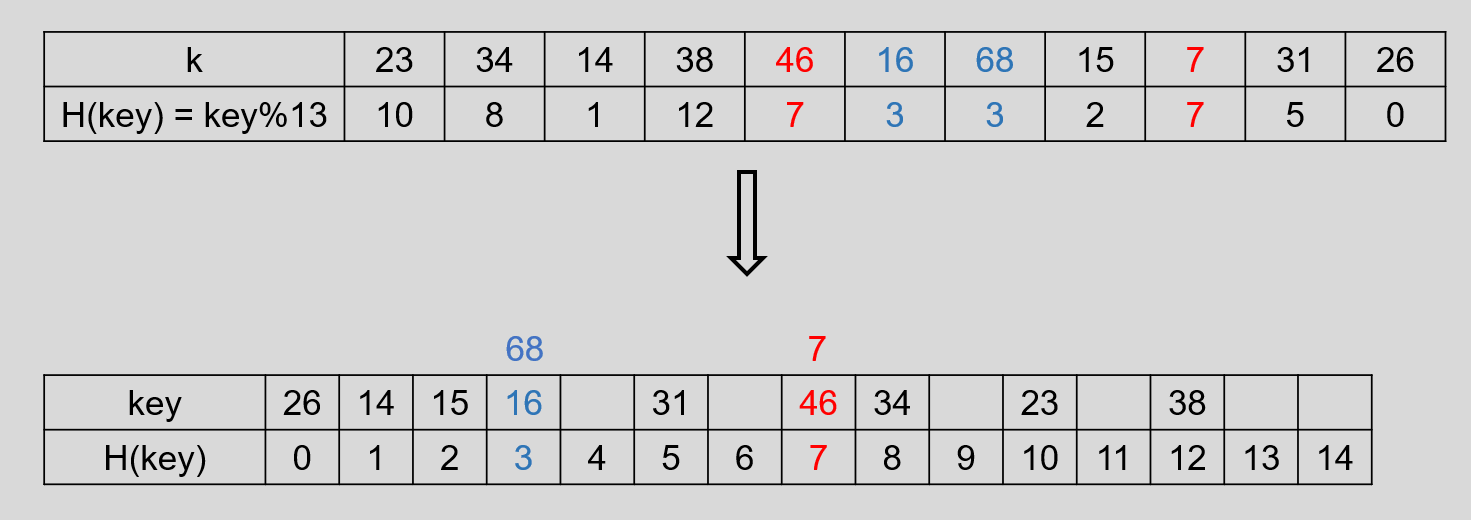
会发现有两个地方产生了冲突,下边使用开放地址法进行处理,重新放置的地址为:
所以有:
2. 链地址法
我们还可以在发生冲突时,将各冲突记录链在一起,即同义词的记录存于同一 链表。即可以设 H(key) 取值范围(值域)为 [0,m-1] ,建立头指针向量 HP [i] (0 ≤ i ≤ m-1) ,其中 HP [i] 初始值为空。
HP [i](0≤i≤m-l)初值为空。
- 实例
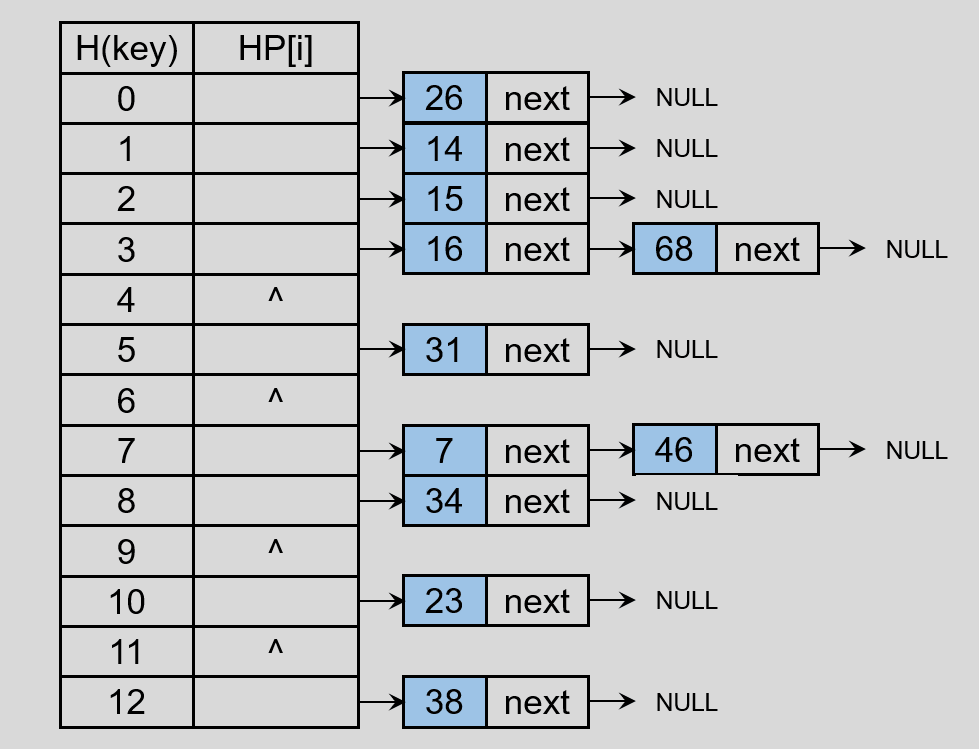
设记录的 key 集合 k = {23, 34, 14, 38, 46, 16, 68, 15, 7, 31, 26} ,则通过 Hash 函数 H(key) = key % 13 得到:

通过链地址法建立 Hash 表,则有:
链地址法解决冲突的优点:无聚积现象;删除表中记录容易实现。
四、Hash实现
1. 结构体实现
首先我们需要一个数组存储 Hash 表地址,这个其实是用于存储 key 对 p 取的余数,接着后边使用链地址法处理所有冲突,链表节点我们使用三个域表示,数据域 key 存储原始数据,数据域 value 存储余数,也就是数据在 Hash 表中的地址,最后是一个指针域,指向下一个节点。节点结构如下图:

结构体定义如下:
/* 宏定义 */
#define N 12 /* Hash 表长度 */
/* 自定义数据类型 */
typedef int data_h;
typedef struct hash_node
{
data_h key; /* 存放原始的数据 */
data_h value;/* 存放余数 */
struct hash_node * next;
}hslinkednode, * hslinkedlink;
typedef struct
{
hslinkednode data[N]; /* 地址表 */
}hash;2. Hash 表基本操作
完整源代码可点击这里下载:
| 数据结构 | 查找 (密码: b1y3) |
2.1 创建
创建一个 Hash 表数组,数组中每个元素都是 Hash 表节点类型,如下图:
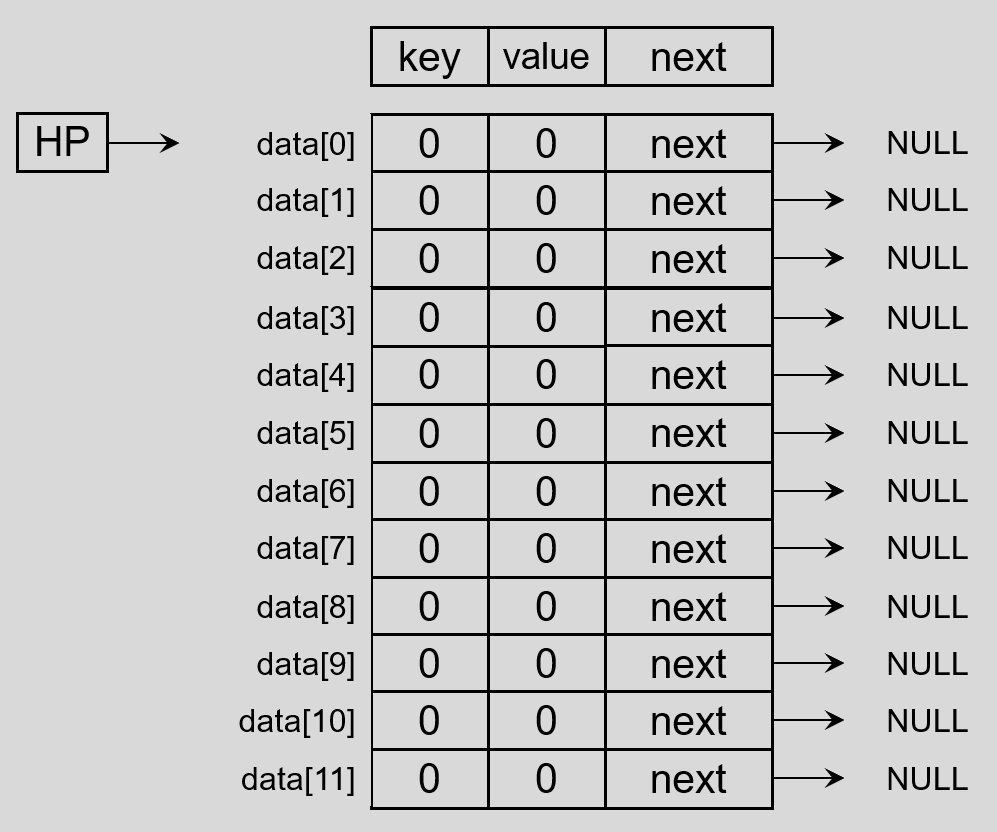
【注意】数组中的元素,后边都相当于链表头节点。
/**
* @Function: slinkedlist_create
* @Description: Hash 表创建
* @param : none
* @return : 返回一个地址
* NULL, 内存申请失败;
* HP, Hash 表地址
*
*/
hash * hashlist_create()
{
/* 定义一个 Hash 表结构体指针变量 */
hash * HP;
/* 1. 申请内存空间 */
HP = (hash *)malloc(sizeof(hash));
/* 2. 判断是否申请成功 */
if (HP == NULL)
{
printf(" hash list malloc failed!\n");
return HP;
}
/* 3. 初始化内存空间 */
memset(HP, 0, sizeof(hash));
return HP;
}2.2 插入
插入节点的过程如下图所示:
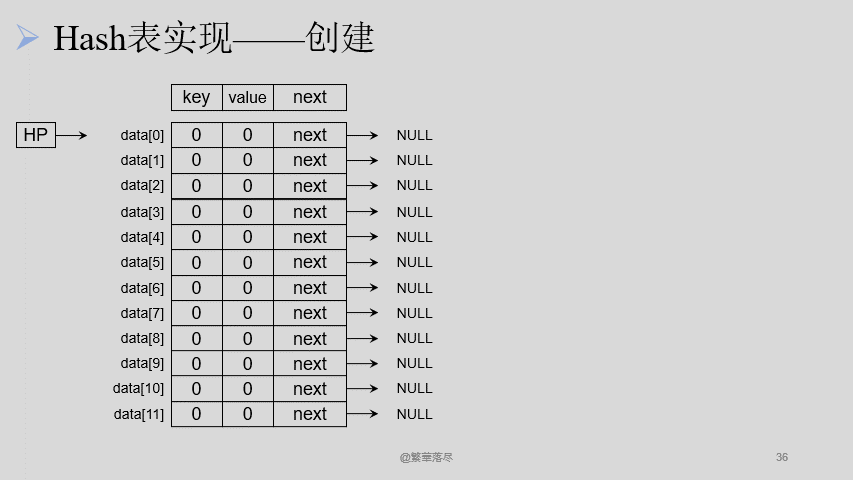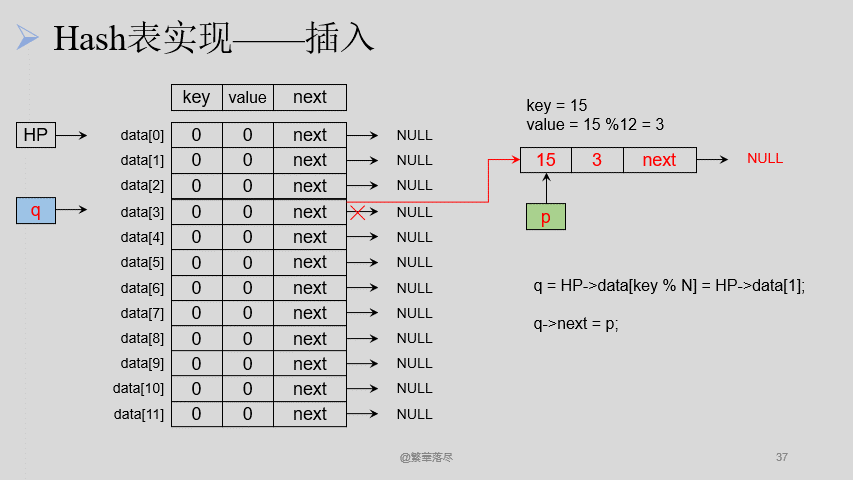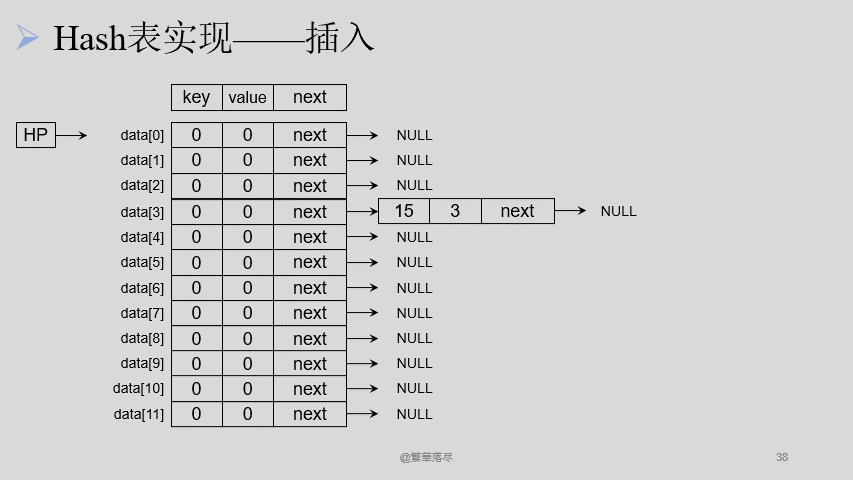
【注意】当产生冲突的时候,可以将数据通过链表相连接,在插入的时候注意 有序插入。
/**
* @Function: hashlist_insert
* @Description: Hash 表数据插入
* @param HP: Hash 表地址
* @param key: 要插入的数据
* @return : 返回一个数值
* 0, 插入成功;
* -1, Hash 表不存在或者节点内存申请失败
*
*/
int hashlist_insert(hash * HP, data_h key)
{
/* 定义两个 Hash 表节点结构体指针变量 */
hslinkedlink p;
hslinkedlink q;
/* 1. 判断 Hash 表是否存在 */
if (HP == NULL)
{
printf(" hash list is not exited!\n");
return -1;
}
/* 2. 新建节点并初始化 */
p = (hslinkedlink)malloc(sizeof(hslinkednode));
if(p == NULL)
{
printf("The new hash list node malloc failed!\n");
return -1;
}
p->key = key;
p->value = key % N;
p->next = NULL;
/* 3. 插入节点 */
q = &(HP->data[p->value]);
/* 有序插入,从小到大 */
while((q->next !=NULL) && (q->next->key < p->key))
{
q = q->next;
}
/* 4. 插入节点 */
p->next = q->next;
q->next = p;
return 0;
}2.3 查找
/**
* @Function: hashlist_search
* @Description: Hash 表数据查询
* @param HP: Hash 表地址
* @param key: 要查询的数据
* @return : 返回一个地址
* other, 数据节点地址;
* NULL, Hash 表不存在或者节点内存申请失败
*
*/
hslinkedlink hashlist_search(hash * HP, data_h key)
{
/* 定义一个 Hash 表节点结构体指针变量 */
hslinkedlink p;
/* 1. 判断 Hash 表是否存在 */
if (HP == NULL)
{
printf(" hash list is not exited!\n");
return NULL;
}
/* 2. 寻找 Hash 表 key 的存储位置的首节点 */
p = &(HP->data[key % N]);
/* 3. 查找数据 */
while ((p->next !=NULL) && (p->next->key != key))
{
p = p->next;
}
/* 4. 判断是否查询到 */
if (p->next == NULL)
{
printf("The data is not in this hash list!\n");
return NULL;
}
else
{
printf("The data is in this hash list!\n");
return p->next;
}
return 0;
}2.4 显示
/**
* @Function: hashlist_show
* @Description: Hash 表打印
* @param HP: Hash 表地址
* @param key: 要查询的数据
* @return : 返回一个地址
* 0, 显示完成;
* -1, Hash 表不存在
*
*/
int hashlist_show(hash * HP)
{
/* 定义一个 Hash 表节点结构体指针变量 */
hslinkedlink p;
int i = 0;
/* 1. 判断 Hash 表是否存在 */
if (HP == NULL)
{
printf(" hash list is not exited!\n");
return -1;
}
/* 2. 访问 Hash 表 */
for(i = 0; i < N; i++)
{
p = &(HP->data[i]);
if(p->next != NULL)
{
printf("Hash data[%d]:", i);
while(p->next != NULL)
{
printf("%d->",p->next->key);
p = p->next;
}
puts("NULL");
}
else
printf("Hash data[%d]:NULL\n", i);
}
puts("");
return 0;
}