
LV005-ollama简介
这一部分主要是介绍 ollama 以及怎么通过它运行大模型。
一、ollama
1. ollama 简介
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,使得机器学习不再是只有深度技术背景的开发者才能触及的领域。
Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。
2. ollama 究竟是什么
最简单的一句话来概括:Ollama,就是大模型领域的 Docker。
在没有 Docker 的时代,我们要部署一个 Web 应用,得先在服务器上装操作系统,再装数据库,再装各种依赖库,配置环境变量……一套下来,人基本就晕了,而且换台机器还得重来一遍。Docker 的出现,把应用和它所有的依赖打包成一个轻量的“容器镜像”,我们只需要一条 docker run 命令,就能在任何支持 Docker 的机器上完美运行,省去了所有繁琐的环境配置。
Ollama 做的就是完全一样的事情,只不过对象从 Web 应用换成了大语言模型。一个大模型,本身其实是一堆巨大的参数文件(我们常说的 7B、13B 就是指参数量),要让它跑起来,我们需要:
(1)模型文件本身:得从 Hugging Face 这类地方下载,动辄几个 G 甚至几十个 G。
(2)运行框架:比如 PyTorch 或 TensorFlow。
(3)底层驱动:如果用 GPU 加速,还得有正确的 CUDA 或 ROCm 驱动。
(4)加载和推理代码:我们需要写代码来加载模型、处理输入(Tokenization)、执行推理、解码输出。
这一套流程,对于新手来说,每一步都可能踩坑。而 Ollama 的伟大之处就在于它的 核心设计哲学:极致简化与整合。
整合(Bundling):Ollama 把“模型权重”、“配置参数”和“运行所需的一切”全部打包成一个单一的模型文件(在 Ollama 里通过一个叫 Modelfile 的东西来定义)。我们不需要关心模型是什么格式(比如 GGUF),也不需要关心它具体怎么加载。
简化(Simplicity):Ollama 提供了一个极其简单的命令行工具。我们想用阿里的通义千问模型?只需要一条命令:ollama run qwen。下载、配置、启动,所有复杂的工作,Ollama 在后台默默帮我们搞定。
所以,我们可以把 Ollama 理解为一个 本地大模型运行器和管理器。它在你的电脑上以后台服务的形式运行,负责管理所有模型文件,并提供了一个统一的命令行接口和 REST API 接口,让我们能轻松地与这些本地模型进行交互。
3. 硬件要求
在开始之前,我们得先了解自己的电脑有没有能力跑大模型,能跑多大的模型。虽然 Ollama 不硬件,但大模型本身是个吃内存和显存的“大胃王”。
内存(RAM):建议至少有 16GB 内存。8GB 也能跑,但只能玩一些小模型(如 3B),而且可能会比较卡。32GB 或以上则能更流畅地运行 7B、13B 甚至更大的模型。
硬盘(Storage):每个模型文件大小在 3GB 到几十 GB 不等,请确保有足够的硬盘空间。建议至少有 50GB 的可用空间。
显卡(GPU):这是强烈推荐的选项!虽然 Ollama 也支持纯 CPU 运行,但速度会非常慢,体验很差。
(1)NVIDIA 显卡:最佳选择。需要安装正确的 CUDA 驱动。Ollama 会自动检测并使用。
(2)AMD 显卡:在 Linux 上支持较好(通过 ROCm),Windows 上的支持正在逐步完善。
(3)Apple Silicon(M1/M2/M3 芯片):苹果的 M 系列芯片内置了强大的 GPU(Metal),Ollama 对其支持非常好。
4. 安装 Ollama
4.1 Ollama 服务安装
下载的话在这里:Download Ollama on Windows,我这里选择的是 windows 版本,然后按提示一路安装就可以了。安装完毕可以在命令行执行下面的命令查看是否安装成功:
ollama -vOllama 在安装后会自动在后台运行一个服务,在状态栏会出现一个小的“羊驼”图标,这就是 Ollama 的服务进程。

注意:这个进程是开机就会自动启动。
4.2 显卡
这个主要参考 ollama/docs/gpu.mdx at main · ollama/ollama,这里还有中文文档:支持的 GPU -- Ollama 中文文档|Ollama 官方文档。
我怎么知道我电脑有没有 NVIDIA 显卡?右键点击“【此电脑】” → “【属性】”→ “【设备管理器】”,展开“【显示适配器】”看看。如果有 NVIDIA GeForce/RTX/Quadro 等字样,就是 N 卡。如果只有 Intel HD Graphics 或 AMD Radeon Graphics,那可能无法使用 NVIDIA 的 GPU 加速。我自己的是这样的:

这里我的好像装完就能直接用,就没怎么折腾了。当时的显卡信息如下:
| 品牌 | NVIDIA |
| 显存大小 | 6 GB |
| 显卡名称 | NVIDIA GeForce RTX 3060 Laptop GPU |
| 驱动日期 | 2023-11-30 |
| 驱动版本 | 31.0.15.4630 |
| 名称 | NVIDIA GeForce RTX 3060 Laptop GPU |
二、本地部署大模型
1. ollama 支持哪些模型?
在这里 Ollama Search 我们可以看到大量的大模型,例如:
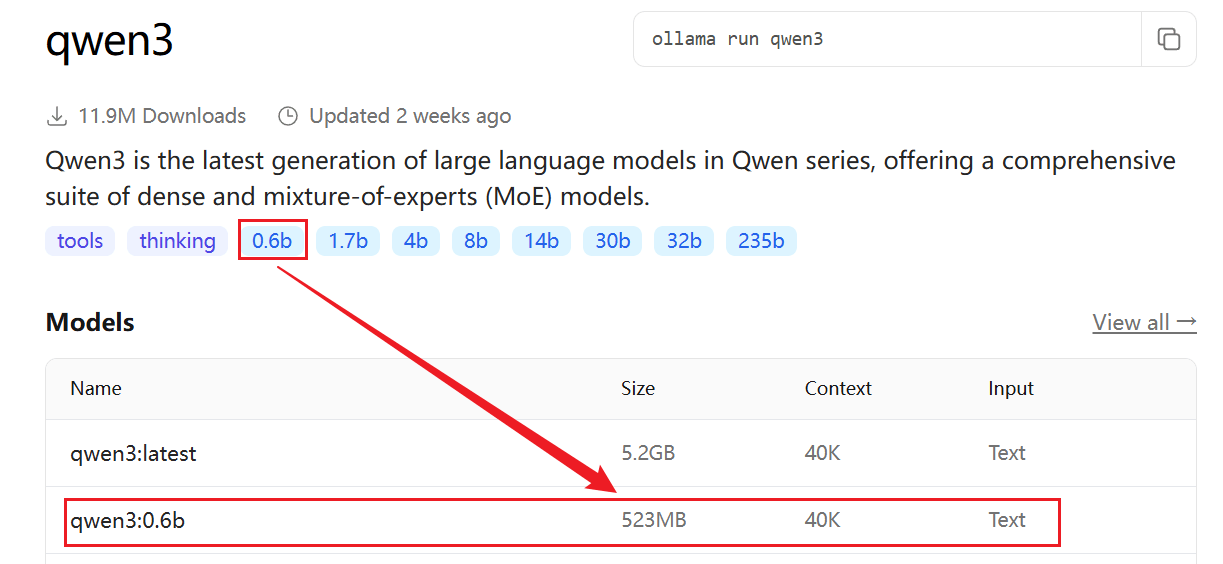
这里可以选择一个最小的千问模型来测试。
2. 基本命令
这里学习基本命令的过程中,我们下载一个 qwen3 的 0.6B 模型。
2.1 拉取模型
我们通过以下命令拉取模型:
ollama pull <model-name>【例】
ollama pull qwen3:0.6b中途会有以下提示信息:
E:\AI> ollama pull qwen3:0.6b
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling 7f4030143c1c: 100% ▕█████████████████████████████████████████████▏ 522 MB
pulling ae370d884f10: 100% ▕█████████████████████████████████████████████▏ 1.7 KB
pulling d18a5cc71b84: 100% ▕█████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕█████████████████████████████████████████████▏ 120 B
pulling b0830f4ff6a0: 100% ▕█████████████████████████████████████████████▏ 490 B
verifying sha256 digest
writing manifest
success在 windows 下,拉取的模型默认存放在 %HOMEPATH%\.ollama\models 中,目录结构是这样的:
models
├── blobs
│ ├── sha256-3e4cb14174460404e7a233e531675303b2fbf7749c02f91864fe311ab6344e4f-partial
│ ├── #...
│ └── sha256-d18a5cc71b84bc4af394a31116bd3932b42241de70c77d2b76d69a314ec8aa12
└── manifests
└── registry.ollama.ai
└── library
└── qwen3
└── 0.6b
5 directories, 23 filesTips:windows 下安装完 ollama 后,会有图形界面的,我们进入设置可以修改模型的默认路径的,因为模型一般都是很大的,这里还是不要都放到 C 盘的好
2.2 列出本地模型
查看已下载的模型列表:
ollama list【例】
E:\AI> ollama list
NAME ID SIZE MODIFIED
qwen3:0.6b 7df6b6e09427 522 MB 2 minutes ago2.3 删除模型
删除本地模型:
ollama rm <model-name>例如:
ollama rm llama22.4 运行模型
运行已下载的模型:
ollama run <model-name>例如:
ollama run llama23. 运行模型
我们上面已经下载好了 qwen3:0.6b ,我们执行下面的命令运行这个模型:
ollama run qwen3:0.6b【例】

然后我们就可以开始问答啦。

4. 退出模型
我们执行快捷键 Ctrl + d 就可以退出了。
三、API 交互
上面是直接使用 ollama 运行了大模型,我们要是想要使用 Python 或者其他脚本访问的话,该怎么办?Ollama 也提供了基于 HTTP 的 API,允许开发者通过编程方式与模型进行交互。
1. 启动 ollama 服务
在使用 API 之前,需要确保 Ollama 服务正在运行。可以通过以下命令启动服务:
ollama serve默认情况下,服务会运行在 http://localhost:11434。我们可以直接访问这个链接,下图所示就表示已经在运行了。

【例】
但是我这里报错了:
E:\AI> ollama serve
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.报错显示端口已经被占用,我们可以通过下面的命令查看端口被谁占用了:
netstat -aon|findstr 11434会得到以下信息:
E:\AI> netstat -aon | findstr 11434
TCP 127.0.0.1:11434 0.0.0.0:0 LISTENING 14280
TCP 127.0.0.1:11434 127.0.0.1:56723 ESTABLISHED 14280
TCP 127.0.0.1:11434 127.0.0.1:58716 ESTABLISHED 14280
TCP 127.0.0.1:56723 127.0.0.1:11434 ESTABLISHED 9008
TCP 127.0.0.1:58716 127.0.0.1:11434 ESTABLISHED 9008发现确实被占用了,我们再来看一下被谁占用了:
tasklist | findstr "14280"会看到以下信息:
E:\AI> tasklist | findstr "14280"
ollama.exe 14280 Console 1 68,004 K发现就是 ollama 占用的,其实我们安装完毕后它就自动启动了,要是没有自动启动的话,可以通过上面的命令启动。
2. API 端点
Ollama 提供了一些主要 API 端点来给开发者调用。
2.1 生成文本(Generate Text)
端点:
POST /api/generate功能:向模型发送提示词(prompt),并获取生成的文本。它适用于需要一次性生成文本响应的场景,如问答系统、文本创作等。
请求格式:
json{ "model": "<model-name>", // 模型名称 "prompt": "<input-text>", // 输入的提示词 "stream": false, // 是否启用流式响应(默认 false) "options": { // 可选参数 "temperature": 0.7, // 温度参数 "max_tokens": 100 // 最大 token 数 } }
请求参数通常包含模型名称(model)、提示文本(prompt)、是否启用流式输出(stream)、生成文本的最大 token 数量(max_tokens)、控制生成文本的随机性(temperature)、控制生成文本的多样性(top_p)以及生成文本的停止条件(stop)等参数。
响应格式:
json{ "response": "<generated-text>", // 生成的文本 "done": true // 是否完成 }
2.2 聊天(Chat)
端点:
POST /api/chat功能:支持多轮对话,模型会记住上下文。它允许用户与模型进行连续的对话,模型会记住上下文信息,并根据用户的后续提问或陈述继续对话。
请求格式:
json{ "model": "<model-name>", // 模型名称 "messages": [ // 消息列表 { "role": "user", // 用户角色 "content": "<input-text>" // 用户输入 } ], "stream": false, // 是否启用流式响应 "options": { // 可选参数 "temperature": 0.7, "max_tokens": 100 } }
除了模型名称和可选的控制参数外,还包含一个消息列表(messages),用于传递对话中的每条消息及其角色(如用户或助手)。
响应格式:
json{ "message": { "role": "assistant", // 助手角色 "content": "<generated-text>" // 生成的文本 }, "done": true }
2.3 列出本地模型(List Models)
端点:
GET /api/tags功能:列出本地已下载的模型。
响应格式:
json{ "models": [ { "name": "<model-name>", // 模型名称 "size": "<model-size>", // 模型大小 "modified_at": "<timestamp>" // 修改时间 } ] }
2.4 拉取模型(Pull Model)
端点:
POST /api/pull功能:从模型库中拉取模型。
请求格式:
json{ "name": "<model-name>" // 模型名称 }响应格式:
json{ "status": "downloading", // 下载状态 "digest": "<model-digest>" // 模型摘要 }
3. 使用实例
3.1 生成文本
使用 curl 发送请求:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:0.6b",
"prompt": "你好,你能帮我写一段C 语言hello world代码吗?",
"stream": false
}'这个命令在 windows 的 cmd 终端和 powershell 中支持的都不是很好,可以用其他终端尝试,这里就不做示例了,后面会学习用 Python 来调用这个大模型实现功能。
3.2 多轮对话
使用 curl 发送请求:
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:0.6b",
"messages": [
{
"role": "user",
"content": "你好,你能帮我写一段 Python 代码吗?"
}
],
"stream": false
}'3.3 列出本地模型
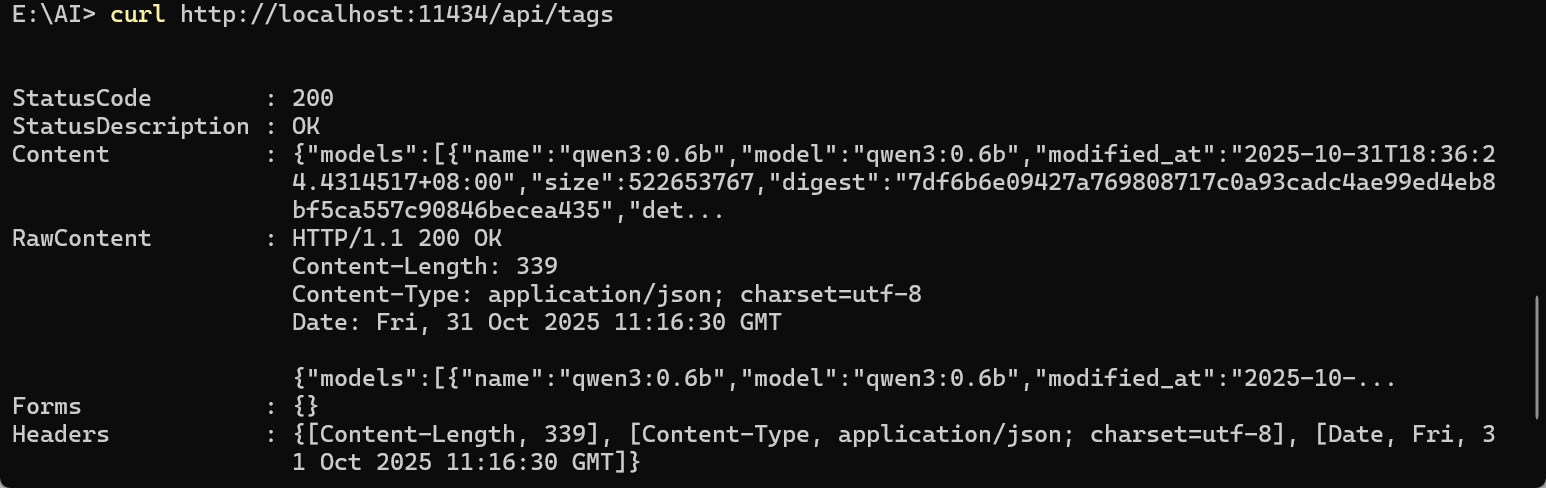
使用 curl 发送请求:
curl http://localhost:11434/api/tags【例】
四、使用 GPU
1. Python 脚本
这里我们需要写一个调用大模型处理的脚本,可以参考 [LV035-实验 1-结构化提示词与输出](/ai/application /126b0f85161f00b305caa178)
2. ollama ps
通过观察 PROCESSOR 就能看到,大模型是用的 cpu 还是 gpu,还是混合的。我们通过 ollama ps 命令:
ollama ps这个时候运行一下 Python 脚本,会看到如下信息:

可以看到默认情况下,跑的全部都是 GPU。所以我就没管了,先这样,后面有问题再补充。
参考资料:
Ollama 系列---ollama 使用 gpu 运行大模型 - jaxiid - 博客园
(3 封私信) 在 Windows 系统中设置环境变量强制让 Ollama 使用 GPU 运行,可以按照以下步骤操作 - 知乎