
LV160-文件描述符的分配
一、linux 内核文件相关结构体
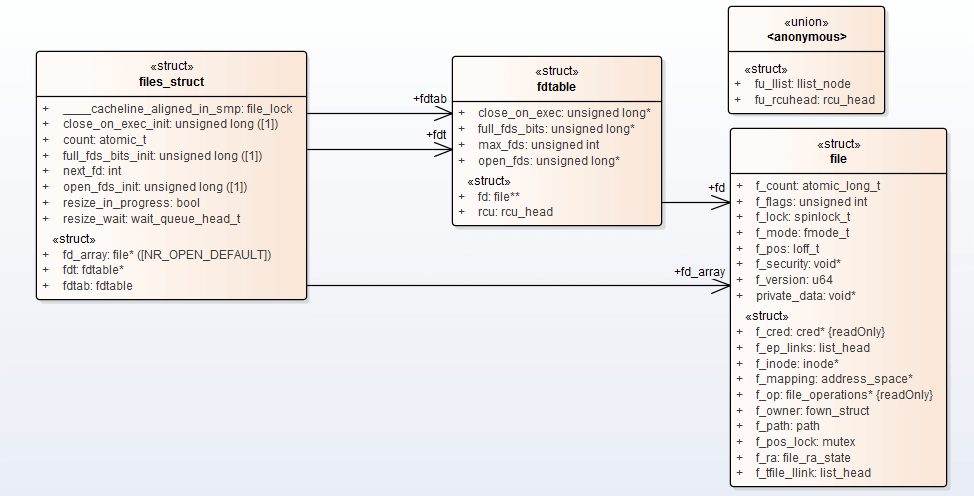
1. struct files_struct
files_struct 这个结构体定义在 fdtable.h - include/linux/fdtable.h - files_struct:
/*
* Open file table structure
*/
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};进程打开文件的表结构,next_fd 表示下一个可用进程描述符,并不一定真正可用,假如 0-10 描述符都被使用了,中间释放 3 文件描述符,再打开文件,此时将使用 3 作为新的文件描述符,内核认为 next_fd 为 4,next_fd 只是表示可能可用的下一个文件描述符,下次查找可用描述符时从 next_fd 开始查找,而不需要从头开始找。
2. struct fdtable
fdtable 定义在 fdtable.h - include/linux/fdtable.h - fdtable:
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};真正记录哪些文件描述符被使用了,哪些是空闲的,实际是一个文件描述符位图,每 1bit 表示了一个文件描述符,例如 bit 0 为 1 表示描述符 1 被使用了,bit 3 为 0 表示描述符 3 可以使用。fd 数组记录了 file 信息,数组下标就是文件描述符的值。
3. struct file
file 结构体定义在 fs.h - include/linux/fs.h - file:
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
/*
* Protects f_ep_links, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
errseq_t f_wb_err;
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
struct file_handle {
__u32 handle_bytes;
int handle_type;
/* file identifier */
unsigned char f_handle[0];
};file: 文件的真正信息,文件描述符只是个数组下标,通过下标查找 file 结构体信息,f_op 记录的是文件读写及其他操作的真正函数,不同的文件系统,读写函数不一样,申请文件描述后,内核会将文件描述符与文件结构体(file 读写函数等)关联起来。具体怎识别文件系统获取读写函数后面再学习。
二、文件描述符位图
1. fdtable
如下简要示意了下文件描述符位图结构:

前面已经提到,fdtable 定义在 fdtable.h - include/linux/fdtable.h - fdtable:
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};1.1 full_fds_bits
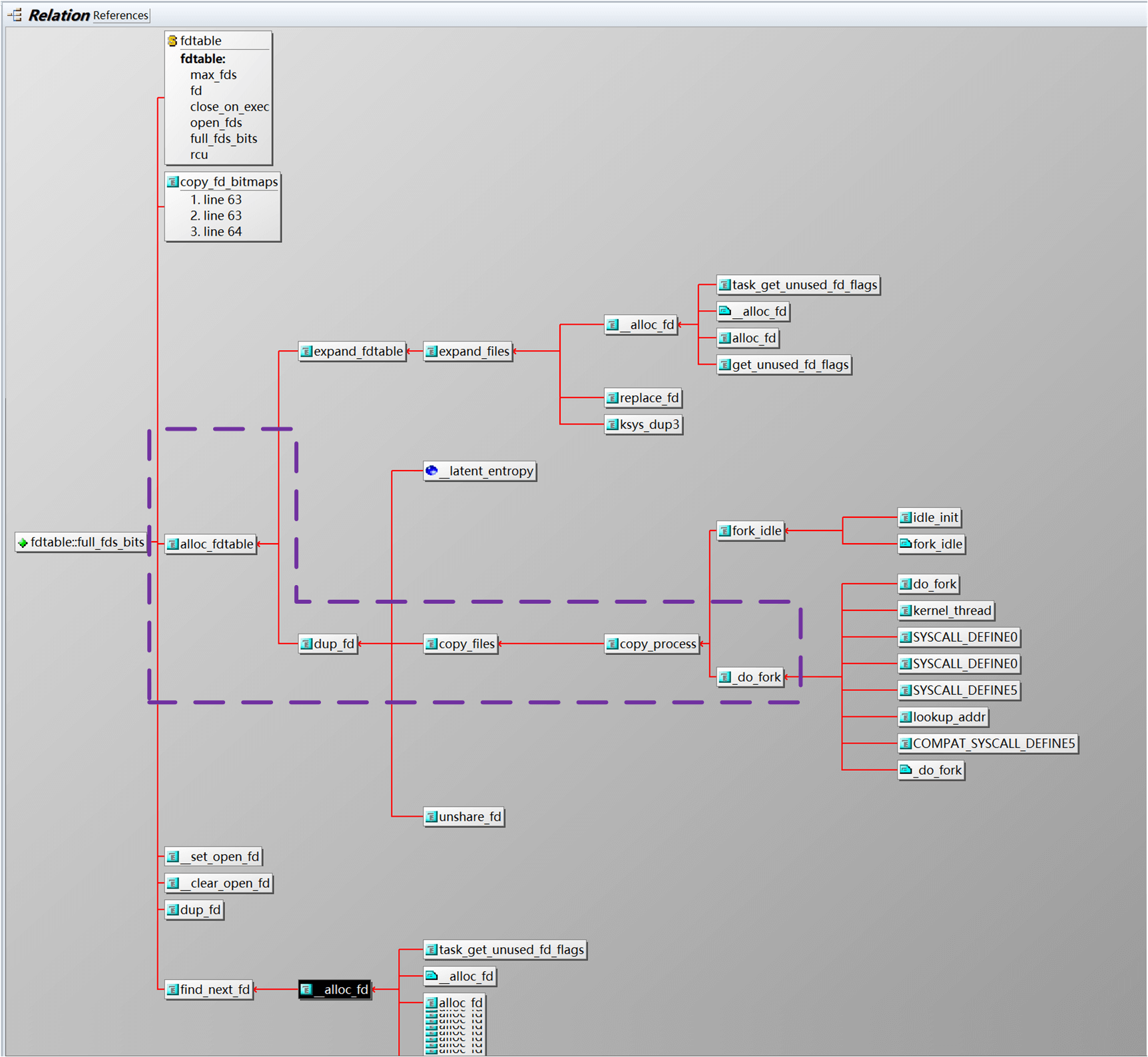
full_fds_bits 每 1bit 代表的是一个 32 位的数组,也就是说代表了 32 位描述符;上面只画了 32 位,内核中的位图是一片连续的内存空间,最低 bit 表示数值 0,下一比特表示 1,依次类推;full_fds_bits 每 1bit 只有 0 和 1 两个值,0 表示有该组有可用的文件描述符,1 表示没有可用的文件描述符,例如位图 bit 0 代表的是 0-31 共 32 个文件描述符,bit1 代表的是 32-63 共 32 个文件描述符,假如 0-31 文件描述符都被使用了,那么位图 bit0 则应该标记为 1,如果 32-63 中有一个未使用的文件描述符,则 bit1 被标记为 0,当 32-63 中的所有文件描述符都被使用的时候,才标记为 1。我们来跟踪一下 full_fds_bits 这个指针的调用关系(source insight 中),图中紫色部分应该是进程创建过程中初始化的 full_fds_bits 这个参数。
1.2 open_fds
open_fds 是真正的文件描述符位图,也是一片连续的内存空间,每 bit 代表一个文件描述符(注意 full_fds_bits 每 bit 代表的是一组文件描述符),标记为 0 的 bit 表示该文件描述符没用被使用,标记为 1 的比特表示该文件描述符已经被使用,例如从内存其实地址开始计算,第 35 比特为 1,则表示文件描述符 35 已经被使用了。
2. next zero bit 查找函数
2.1 函数说明
这个函数是查找可用文件描述符,其实我是不确定到底用的是哪个的,在 findbit.S - arch/arm/lib/findbit.S 和这 findbit.S - arch/unicore32/lib/findbit.S 两个文件中都有相关的信息,但是这里都是汇编,就没有过于深究,大概了解一下吧。函数原型如下:
int find_next_zero_bit(void *addr, unsigned int maxbit, int offset)【参数说明】
- addr 位图内存起始地址;
- maxbit 最大 bit 偏移,也就是位图最后一 bit 的偏移;
- offset 起始查找地址,
前面有介绍位图数组 full_fds_bits,通过该位图可以确定某组文件描述符里面是否有可以使用的文件描述符,另外 next_fd 也记录了下一个可能可用的文件描述符,因此查找可用文件描述符的时候,总是从可能可用的文件描述符开始查找,而不需要从头找,next_fd 在打开和关闭文件描述符的时候会计算相关的内容。
2.2 基本原理
这里以这个 findbit.S - arch/arm/lib/findbit.S - ENTRY(_find_next_zero_bit_le) 为例来分析一下:
/*
* Purpose : Find next 'zero' bit
* Prototype: int find_next_zero_bit(void *addr, unsigned int maxbit, int offset)
*/
ENTRY(_find_next_zero_bit_le)
teq r1, #0
beq 3b
ands ip, r2, #7
beq 1b @ If new byte, goto old routine
ARM( ldrb r3, [r0, r2, lsr #3] )
THUMB( lsr r3, r2, #3 )
THUMB( ldrb r3, [r0, r3] )
eor r3, r3, #0xff @ now looking for a 1 bit
movs r3, r3, lsr ip @ shift off unused bits
bne .L_found
orr r2, r2, #7 @ if zero, then no bits here
add r2, r2, #1 @ align bit pointer
b 2b @ loop for next bit
ENDPROC(_find_next_zero_bit_le)第 6 行:r1 = maxbit,如果 maxbit 为 0,是不需要比较的。
第 8 行:判断 offset 低 3 位是否为 0,查找 0bit 位的时候是以 8 位对齐查找的,3 位二进制,如果 offset 是 8 的整数倍,那么低 3 位应该是 0,跳转到 1b 处查找(从 byte 的第 0 位开始查找)
第 10 行:offset 不是 8 的整数倍,那么先从 offset % 8 开始查找,假如 offset = 18 = 15 + 3,0 -15 bit 正好是 2 个字节,我们只需要从第 3 个字节的第 3 位开始查找即可,因为计算机读的时候是以最小单位字节读取的,所以我们不能直接读取第 18bit,而是要读取 16-23bit,相当于多读了 3bit 的值而已。
第 11 行:"lsr, #3" 实际是 offset/8,获取的是 bit 对应的 byte,例如 18/8 = 2,表示 18bit 在内存的第 2 个字节里面(字节起始索引为 0)
第 13 行:"eor r3, r3, #0xff",这一行是 8bit 文件描述符进行异或操作,实际效果是各位取反,就是将 0 变 1、1 变 0,对 0 的查找变为对 1 的查找,便于代码的编写
第 14 行:"movs r3, r3, lsr ip",ip 是 offset % 8,右移文件描述符,就是将不需要比较的位移除(该函数是从指定位置开始找 0bit 位,但是并不是说指定位置之前都是 1)
第 15 行:结果不为 0,即有 bit 的值为 1(前面已经将 0 取反为 1 了),找到了为 1 的 bit 则跳转到 .L_found
第 18 行:没有找到,继续查找,后续都是 8 个 bit 的查找。
再来看一下 .L_found:
/*
* One or more bits in the LSB of r3 are assumed to be set.
*/
.L_found:
#if __LINUX_ARM_ARCH__ >= 5
rsb r0, r3, #0
and r3, r3, r0
clz r3, r3
rsb r3, r3, #31
add r0, r2, r3
#else
@ r3是前面取的8bit文件描述符,r3 & 0x0f用来判断低4位是否有1,即可用描述符是否在r3的低4位里面
tst r3, #0x0f
@ 上一条指令结果为0,表示r3低4位没有可用的文件描述符,offset = offset + 4,在第4位之后继续查找
addeq r2, r2, #4
@ tst指令执行结果不为0,表示r3低4位有1(即有可用文件描述符),将r3左移4位,移位后低4位就都为0了,注意这里offset没有变化,执行者条指令之后,可用描述符都集中的r3的高4位了,只要从第4位开始查找为1的bit就可以了。
movne r3, r3, lsl #4
@ 从第4位开始查找
@ 判断第4或者5位是否为1
tst r3, #0x30
@ 第4、5位都不为1,则为1的bit位必定在第6或7位,偏移先加2,offset = offset + 2
addeq r2, r2, #2
@ 第4或者第5位有1,则先左移2两位,这步的offset没有修改
movne r3, r3, lsl #2
@ 从第6位开始查找
@ 判断第6位是否为0
tst r3, #0x40
@ 第6位为0,则为1的bit位一定在第7位,offset = offset + 1
addeq r2, r2, #1
@ 为1(之前为0的bit取反得到的)的bit偏移位置,即可用的文件描述符,r0是函数的返回值
mov r0, r2
#endif
cmp r1, r0 @ Clamp to maxbit
movlo r0, r1
ret lr说实话,没看懂。这里举个简单的例子再解释下;例如 r3 的第 0-3bit 都为 0,第 7bit 为 1,offset 起始值为 0,需要查找到低 7bit,先让 offset = offset + 4,然后从第 4 位找为 1 的第 7bit 位,此时第 4 到第 7 位的偏移是 3,我们只需要让 offset 再加 3 即可 offset = offset + 3 = 4 + 3 = 7,也就是我们每次查找的起始位置变了;再假如 r3 的第 3bit 为 1,offset 起始值为 0,将 r3 左移 4 位,此时第 3bit 将变为第 7bit,但是 offset 还是为 0,接着我们从第 4bit 开始查找为 1 的 bit,第 4 到第 7bit 的偏移为 3,offset = offset + 3 = 0 + 3 = 3,得到的结果是正确的。
总结一句话就是,移位操作是为了使后面代码查找时的起点都是一样的。
3. __alloc_fd()
__alloc_fd()函数是文件描述符分配,该函数仅分配了一个可用的文件描述符,文件描述符与文件操作函数的关联不在这里处理。它定义在 file.c - fs/file.c - __alloc_fd:
/*
* allocate a file descriptor, mark it busy.
*/
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files); // 获取文件描述符表
fd = start;
if (fd < files->next_fd)
fd = files->next_fd; // 默认传递的起始查找文件描述不一定有效,不在有效范围时使用 next_fd 作为起始查找值
if (fd < fdt->max_fds)
fd = find_next_fd(fdt, fd); // 起始查找文件描述符小于最大文件描述符,从当前文件描述符表中查找可用的文件描述符(max_fds 表示已分配的文件描述符的数量,也就是位图总的 bit 数,后面会看到文件描述符表扩展的代码,在此先介绍下)
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
error = -EMFILE;
if (fd >= end) // 可用文件描述符超出函数参数传递的最大值,返回-EMFILE,这是个标准错误码 errno
goto out;
error = expand_files(files, fd); // 扩展文件描述符,当 fd <=max_fds时,fd在文件描述符位图可表示的范围,例如我们申请的文件描述符大小为1byte,那么文件描述符最大只能表示7,当fd大于7的时候,我们就没有对应的bit位可以标记了,因此需要重新扩展,申请更大的内存,申请的新的文件描述符表,让后将旧的值拷贝到新的文件描述符表中。只有fd> max_fds 才会真正扩展。
if (error < 0)
goto out;
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
if (error)
goto repeat;
if (start <= files->next_fd)
files->next_fd = fd + 1;
__set_open_fd(fd, fdt); // 在文件描述符表中标记 fd 已经被打开,对应 bit 位设置为 1,同时更新 fd 所在文件描述符组的值,因为 fd 改变后,可能导致该组的文件描述符都被使用了,需要将该组标记为 1,下次查找可用文件描述符时就会跳过该组,避免不必要的查找。
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt); // 打开时带有 O_CLOEXEC 标志,设置 close_on_exec 文件描述符位打开状态,大致意思是 exec 创建进程时会覆盖父进程,但是子进程继承了父进程的文件描述符,对于 exec 创建的新进程,继承的文件描述符已经没有任何意义了,创建之后需要关闭这些无意义的文件描述符,而这些文件描述符就记录在 close_on_exec 里面。
else
__clear_close_on_exec(fd, fdt);
error = fd;
#if 1
/* Sanity check */
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL); // 文件操作函数设置为 NULL,此时只分配了文件描述符,还没有真正关联到具体的文件操作函数
}
#endif
out:
spin_unlock(&files->file_lock);
return error;
}4. find_next_fd()
find_next_fd()函数是查找下一个可用的文件描述符,它定义在 file.c - fs/file.c - find_next_fd:
static unsigned int find_next_fd(struct fdtable *fdt, unsigned int start)
{
unsigned int maxfd = fdt->max_fds; // 文件描述符表最大文件描述符
unsigned int maxbit = maxfd / BITS_PER_LONG; // 最大文件描述符组(一组文件描述符包含 32 个文件描述符,例如 0-31 为一组)
unsigned int bitbit = start / BITS_PER_LONG; // 起始查找文件描述符所在组(32 个文件描述符为一组,我们要从文件描述符 33 开始查找,可知,33 文件描述符在 33/32 = 1 组,因此我们从第 1 组开始查找即可)
bitbit = find_next_zero_bit(fdt->full_fds_bits, maxbit, bitbit) * BITS_PER_LONG; // 查找下一个可用文件描述符组,结果乘以 BITS_PER_LONG,即得到该组起始文件描述符。
if (bitbit > maxfd)
return maxfd; // 可用文件描述符起始值大于最大文件描述符,直接返回最大文件描述符,表示文件描述符需要扩展。
if (bitbit > start)
start = bitbit; // 可用起始文件描述符大于参数传递的起始查找文件描述符,将开始查找的值从真正有效的值开始,避免做无效的查找。
return find_next_zero_bit(fdt->open_fds, maxfd, start); // 从文件描述符表中查找可用的文件描述符(之前是查找可用组,以 32 位为大小查找,提高效率,这次的查找范围缩小的组内了,即最多只需要查找 32 次了,这有点像找房间一样,先找楼层,再找房间,而不需要每层楼每间房间都找一遍;查找函数在前面章节已经介绍了)。
}5. expand_files()
文件描述表大小是根据需要动态增加的,不会一开始就申请很大空间,这样会浪费内存,当文件描述符表不够大时才重新分配内存空间。expand_files()函数用于扩展文件描述符表。这个函数定义在 file.c - fs/file.c - expand_files:
/*
* Expand files.
* This function will expand the file structures, if the requested size exceeds
* the current capacity and there is room for expansion.
* Return < 0 error code on error; 0 when nothing done; 1 when files were
* expanded and execution may have blocked.
* The files-> file_lock should be held on entry, and will be held on exit.
*/
static int expand_files(struct files_struct *files, unsigned int nr)
__releases(files->file_lock)
__acquires(files->file_lock)
{
struct fdtable *fdt;
int expanded = 0;
repeat:
fdt = files_fdtable(files); // 获取文件描述符表
/* Do we need to expand? */
if (nr < fdt->max_fds) // 新的文件描述符 < max_fds,旧的文件描述符表已经足够表示该文件描述符了,不需要扩展。
return expanded;
/* Can we expand? */
if (nr >= sysctl_nr_open) // 大于限制的最大文件描述符,返回错误,不运行操作系统设置的最大文件描述符
return -EMFILE;
if (unlikely(files->resize_in_progress)) { // 同一进程下的多个线程是共用一个文件描述符的,需要互斥访问
spin_unlock(&files->file_lock);
expanded = 1;
wait_event(files->resize_wait, !files->resize_in_progress);
spin_lock(&files->file_lock);
goto repeat;
}
/* All good, so we try */
files->resize_in_progress = true;
expanded = expand_fdtable(files, nr); // 扩展文件描述符表
files->resize_in_progress = false;
wake_up_all(&files->resize_wait);
return expanded;
}第 38 行,调用 expand_fdtable()函数进行文件描述符表的扩展。
5.1 expand_fdtable()
expand_fdtable()函数用于文件描述符表的扩展,它定义在 file.c - fs/file.c - expand_fdtable:
/*
* Expand the file descriptor table.
* This function will allocate a new fdtable and both fd array and fdset, of
* the given size.
* Return < 0 error code on error; 1 on successful completion.
* The files-> file_lock should be held on entry, and will be held on exit.
*/
static int expand_fdtable(struct files_struct *files, unsigned int nr)
__releases(files->file_lock)
__acquires(files->file_lock)
{
struct fdtable *new_fdt, *cur_fdt;
spin_unlock(&files->file_lock);
new_fdt = alloc_fdtable(nr); // 申请足以表示 nr 文件描述符的内存空间
// ......
copy_fdtable(new_fdt, cur_fdt); // 文件描述符信息拷贝
rcu_assign_pointer(files->fdt, new_fdt); // 文件描述符表指针更新
if (cur_fdt != &files->fdtab)
call_rcu(&cur_fdt->rcu, free_fdtable_rcu);
/* coupled with smp_rmb() in __fd_install() */
smp_wmb();
return 1;
}第 15 行,通过调用 alloc_fdtable()函数来申请足以表示 nr 文件描述符的内存空间。
5.2 alloc_fdtable()
alloc_fdtable()函数定义在 file.c - fs/file.c - alloc_fdtable:
static struct fdtable * alloc_fdtable(unsigned int nr)
{
struct fdtable *fdt;
void *data;
/*
* Figure out how many fds we actually want to support in this fdtable.
* Allocation steps are keyed to the size of the fdarray, since it
* grows far faster than any of the other dynamic data. We try to fit
* the fdarray into comfortable page-tuned chunks: starting at 1024B
* and growing in powers of two from there on.
*/
nr /= (1024 / sizeof(struct file *));
nr = roundup_pow_of_two(nr + 1);
nr *= (1024 / sizeof(struct file *)); // nr 大小不确定,这之前的步骤就是为了调整 nr 大小,具体含义看英文说明
/*
* Note that this can drive nr *below* what we had passed if sysctl_nr_open
* had been set lower between the check in expand_files() and here. Deal
* with that in caller, it's cheaper that way.
*
* We make sure that nr remains a multiple of BITS_PER_LONG - otherwise
* bitmaps handling below becomes unpleasant, to put it mildly...
*/
if (unlikely(nr > sysctl_nr_open)) // nr 大于系统设置的文件描述符上限,需要调整不超过系统设置的上限
nr = ((sysctl_nr_open - 1) | (BITS_PER_LONG - 1)) + 1;
fdt = kmalloc(sizeof(struct fdtable), GFP_KERNEL_ACCOUNT); // 申请内存空间
if (!fdt)
goto out;
fdt->max_fds = nr; // 最大文件描述符
data = kvmalloc_array(nr, sizeof(struct file *), GFP_KERNEL_ACCOUNT);
if (!data)
goto out_fdt;
fdt->fd = data;
data = kvmalloc(max_t(size_t,
2 * nr / BITS_PER_BYTE + BITBIT_SIZE(nr), L1_CACHE_BYTES),
GFP_KERNEL_ACCOUNT);
if (!data)
goto out_arr;
fdt->open_fds = data; // 文件描述符位图(每一位代表一个文件描述符)
data += nr / BITS_PER_BYTE;
fdt->close_on_exec = data; // close_on_exec 文件描述符位图(用于在 exec 创建替换父进程时,确定哪些文件描述符需要关闭)
data += nr / BITS_PER_BYTE;
fdt->full_fds_bits = data; // 文件描述符组位图(每一位代表一个文件描述符组,一组文件描述符有 32 个文件描述符,当该组文件描述符都被使用了的时候,将该组对应的 bit 位设置为 1,表示该组已经没有可用文件描述符了)
return fdt;
out_arr:
kvfree(fdt->fd);
out_fdt:
kfree(fdt);
out:
return NULL;
}6. __put_unused_fd()
为了加速文件描述符查找,文件描述符分配/释放的时候都会更新 next_fd,用来标志下一个可能可用的文件描述符,例如:我们刚申请到了文件描述符 3,那么就代表 3 之前的文件描述符都被使用了(分配文件描述符是从小到大分配的),下一个可能可用的文件描述符应该大于等于 4,当然文件描述符 4 有可能已经被使用了,但是我们不必查找文件描述符 4 之前的文件描述符,这样就提高了效率。另外,例如:0-9 文件描述符都被使用了,next_fd = 10,现在 close 文件描述符 3,3 < 10,因此我们更新 next_fd 为 3,这样我们就能保证 next_fd 始终是最小可能可用的文件描述符,不会造成查找时跳过可用文件描述符的情况。
实现上述功能的函数为__put_unused_fd(),它定义在 file.c - fs/file.c - __put_unused_fd:
static void __put_unused_fd(struct files_struct *files, unsigned int fd)
{
struct fdtable *fdt = files_fdtable(files);
__clear_open_fd(fd, fdt); // 清除文件描述符使用标记,同时清除该文件描述符所在组的标记,释放了一个文件描述符,该组至少有一个文件描述符可使用
if (fd < files->next_fd)
files->next_fd = fd; // 更新下一个可用的文件描述符(打开文件时会更新)
}三、文件描述符关联
linux 系统下任何设备都是文件,任何文件操作接口都是一样的,对于应用程序来说,用户只获取到文件描述符,要实现对文件操作,内核还需要知道文件描述符对应的真正设备是什么,怎么操作;ext2、ext4、socket、pipe 各种文件的操作都不一样,具体由 vfs 统一封装了。
1. do_sys_open()
这里简单看一下 do_sys_open()函数,他定义在 open.c - fs/open.c - do_sys_open:
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags); // 获取未使用的文件描述符
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op); // 打开文件,获取 file 结构体,文件操作的函数指针等,在此暂不做解释,可以参考之前 pipe 管道的文章,自己分析下 pipe 操作函数是怎么获取到的,pipe 操作比物理文件系统操作简单了很多,分析起来更容易。
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f); // 文件描述符与文件结构体(真正的文件操作函数等)关联,实际就是设置 fd 对应的数组的值为 f,在此不做详细解释。
}
}
putname(tmp);
return fd;
}后面我们再详细学习吧。
参考资料