
LV201-open函数解析1
本文主要是 kernel——open 源码解析的相关笔记。
一、一个实例
1. 测试 demo
这里还是先以打开一个文本文件为例:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
int fd = open("/home/sumu/7Linux/test.txt", O_CREAT | O_RDWR);
close(fd);
return 0;
}2. 系统调用?
open 用的哪个系统调用?其实前面已经了解过了,这里在回顾一下吧,以这个 demo 为例:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
int fd = open("/home/sumu/7Linux/test.txt", O_RDONLY);
close(fd);
return 0;
}使用 strace 命令看一下:
gcc main.c -Wall
touch test.txt
strace -o syscall ./a.out会发现有这么一行:
openat(AT_FDCWD, "/home/sumu/7Linux/test.txt", O_RDONLY) = 3从这里可以看出,调用的是 openat 这个系统调用。
二、open 源码分析
1. 系统调用 openat()
我们前面一节已经找到了 open 的系统调用 openat,它定义在 open.c - fs/open.c - openat:
SYSCALL_DEFINE4(openat, int, dfd, const char __user *, filename, int, flags,
umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(dfd, filename, flags, mode);
}有些版本的系统调用可能直接就是 open,这个搜一下就会知道了。其实不管是 open 还是 openat,都会调用 do_sys_open()函数进行处理。根据前面的实例,这里的参数应该是这样的:
openat(AT_FDCWD, "/home/sumu/7Linux/test.txt", O_RDONLY) = 3这里的 AT_FDCWD 定义在 fcntl.h - include/uapi/linux/fcntl.h - AT_FDCWD:
#define AT_FDCWD -100 /* Special value used to indicate openat should use the curren working directory. */这个 force_o_largefile()函数应该是定义在 fcntl.h - include/linux/fcntl.h - force_o_largefile:
#ifndef force_o_largefile
#define force_o_largefile() (BITS_PER_LONG != 32)
#endif最后调用 do_sys_open 的时候参数应该是这样对应的:
/*
* dfd = -100 (AT_FDCWD)
* filename = "/home/sumu/7Linux/test.txt"
* flags = O_RDONLY | O_LARGEFILE;
* mode = 0
*/2. do_sys_open()
do_sys_open()函数定义在 open.c - fs/open.c - do_sys_open:
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}第 14 行:获取一个该进程未使用的 fd;
第 16 行:生成一个 struct file,生成这个对象的时候通过 do_filp_open()函数进行。
第 22 行:将 fd 与 struct file 进行绑定。
2.1 build_open_flags()
build_open_flags()定义在 open.c - fs/open.c - build_open_flags,这个函数主要是用来构建 flags,并返回到结构体 struct open_flags op 中。该函数定义如下:
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
int lookup_flags = 0;
int acc_mode = ACC_MODE(flags);
/*
* Clear out all open flags we don't know about so that we don't report
* them in fcntl(F_GETFD) or similar interfaces.
*/
flags &= VALID_OPEN_FLAGS;
if (flags & (O_CREAT | __O_TMPFILE)) // if 判断为 0
op->mode = (mode & S_IALLUGO) | S_IFREG;
else
op->mode = 0;
/* Must never be set by userspace */
flags &= ~FMODE_NONOTIFY & ~O_CLOEXEC;
/*
* O_SYNC is implemented as __O_SYNC|O_DSYNC. As many places only
* check for O_DSYNC if the need any syncing at all we enforce it's
* always set instead of having to deal with possibly weird behaviour
* for malicious applications setting only __O_SYNC.
*/
if (flags & __O_SYNC) // if 判断为 0
flags |= O_DSYNC;
if (flags & __O_TMPFILE) { // if 判断为 0
if ((flags & O_TMPFILE_MASK) != O_TMPFILE)
return -EINVAL;
if (!(acc_mode & MAY_WRITE))
return -EINVAL;
} else if (flags & O_PATH) {
/*
* If we have O_PATH in the open flag. Then we
* cannot have anything other than the below set of flags
*/
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH;
acc_mode = 0;
}
op->open_flag = flags;
/* O_TRUNC implies we need access checks for write permissions */
if (flags & O_TRUNC) // if 判断为 0
acc_mode |= MAY_WRITE;
/* Allow the LSM permission hook to distinguish append
access from general write access. */
if (flags & O_APPEND) // if 判断为 0
acc_mode |= MAY_APPEND;
op->acc_mode = acc_mode;
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
if (flags & O_CREAT) { // if 判断为 0
op->intent |= LOOKUP_CREATE;
if (flags & O_EXCL)
op->intent |= LOOKUP_EXCL;
}
if (flags & O_DIRECTORY) // if 判断为 0
lookup_flags |= LOOKUP_DIRECTORY;
if (!(flags & O_NOFOLLOW)) // if 判断为 1
lookup_flags |= LOOKUP_FOLLOW;
op->lookup_flags = lookup_flags;
return 0;
}最终,op 各个成员的值如下:
op->mode = 0
op->open_flag = 0x8000
op->acc_mode = 0x4
op->intent = 0x100 (LOOKUP_OPEN)
op->lookup_flags = 0x1 (LOOKUP_FOLLOW)这里分析的时候,不考虑很多特殊情况,该 build_open_flags() 函数中很多代码是不用执行的。
2.2 get_unused_fd_flags()
在 get_unused_fd_flags() 函数中,找到一个可用的文件描述符,并返回该值,这里更深入一层就会涉及到文件描述符的分配以及查找,相关的函数和结构可以看这里《01 嵌入式开发/02IMX6ULL 平台/LV05-系统镜像/LV05-03-Kernel-05-02-文件描述符分配.md》。这个函数定义如下:
int get_unused_fd_flags(unsigned flags)
{
return __alloc_fd(current->files, 0, rlimit(RLIMIT_NOFILE), flags);
}
EXPORT_SYMBOL(get_unused_fd_flags);可见它最后是调用了__alloc_fd()函数。
3. do_filp_open()
do_filp_open()函数定义在 namei.c - fs/namei.c - do_filp_open:
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}第 8 行:set_nameidata() 函数主要用来设置结构体 struct nameidata 的值,这个结构体是个非常重要的结构体,在解析和查找路径名时会经常引用到。函数定义如下:
static void set_nameidata(struct nameidata *p, int dfd, struct filename *name)
{
struct nameidata *old = current->nameidata;
p->stack = p->internal;
p->dfd = dfd;
p->name = name;
p->total_link_count = old ? old->total_link_count : 0;
p->saved = old;
current->nameidata = p;
}第 13 行:这个函数其实后面调用的是 path_openat(),后面我们继续分析。
4. path_openat()
path_openat()函数入口参数如下:
/* 函数入口参数: flags = LOOKUP_FOLLOW | LOOKUP_RCU */函数定义在 namei.c - fs/namei.c - path_openat:
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
int error;
file = alloc_empty_file(op->open_flag, current_cred());
if (IS_ERR(file))
return file;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file);
} else if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
} else {
const char *s = path_init(nd, flags);
while (!(error = link_path_walk(s, nd)) &&
(error = do_last(nd, file, op)) > 0) {
nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL);
s = trailing_symlink(nd);
}
terminate_walk(nd);
}
if (likely(!error)) {
if (likely(file->f_mode & FMODE_OPENED))
return file;
WARN_ON(1);
error = -EINVAL;
}
fput(file);
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
return ERR_PTR(error);
}第 7 行:path_openat()该函数通过 alloc_empty_file() 为该进程生成了一个 struct file。
第 16 行:path_init()函数用于初始化 struct nameidata 结构体。
第 18 行:最后由 do_last()函数完成剩下的打开步骤。
4.1 path_init()
先看其中的 path_init() 函数。在解析路径的过程中,需要遍历路径中的每个部分,而其中使用结构体 struct nameidata 来保存当前遍历的状态。path_init() 函数主要用来将该结构体初始化。函数定义如下:
/* must be paired with terminate_walk() */
static const char *path_init(struct nameidata *nd, unsigned flags)
{
/* 函数入口参数: flags = LOOKUP_FOLLOW | LOOKUP_RCU */
const char *s = nd->name->name; /* s = "/home/sumu/7Linux/test.txt" */
if (!*s) //if 判断为 0
//......
nd->last_type = LAST_ROOT; /* if there are only slashes... */
nd->flags = flags | LOOKUP_JUMPED | LOOKUP_PARENT;
nd->depth = 0;
if (flags & LOOKUP_ROOT) { // if 判断为 0
//......
}
nd->root.mnt = NULL;
nd->path.mnt = NULL;
nd->path.dentry = NULL;
nd->m_seq = read_seqbegin(&mount_lock);
if (*s == '/') { // if 判断为 1, 表示从绝对路径'/'开始解析目录
set_root(nd);
if (likely(!nd_jump_root(nd)))
return s; // 函数由此处返回
return ERR_PTR(-ECHILD);
} else if (nd->dfd == AT_FDCWD) {
//......
} else {
//......
}
}4.1.1 set_root()
下面分析一下 set_root() 函数,该函数设置 struct nameidata nd 的值,使得路径解析从根目录开始(而不是当前工作目录)。函数定义如下:
static void set_root(struct nameidata *nd)
{
struct fs_struct *fs = current->fs;
if (nd->flags & LOOKUP_RCU) {
unsigned seq;
do {
seq = read_seqcount_begin(&fs->seq);
nd->root = fs->root;
nd->root_seq = __read_seqcount_begin(&nd->root.dentry->d_seq);
} while (read_seqcount_retry(&fs->seq, seq));
} else {
get_fs_root(fs, &nd->root);
}
}4.1.2 nd_jump_root()
nd_jump_root() 函数的作用和 set_root() 函数差不多,但做的工作要更多一些。函数定义如下:
static int nd_jump_root(struct nameidata *nd)
{
if (nd->flags & LOOKUP_RCU) { // if 判断为 1
struct dentry *d;
nd->path = nd->root;
d = nd->path.dentry;
nd->inode = d->d_inode;
nd->seq = nd->root_seq;
if (unlikely(read_seqcount_retry(&d->d_seq, nd->seq))) // if 判断为 0
return -ECHILD;
} else {
path_put(&nd->path);
nd->path = nd->root;
path_get(&nd->path);
nd->inode = nd->path.dentry->d_inode;
}
nd->flags |= LOOKUP_JUMPED;
return 0;
}4.2 link_path_walk()
上面对 struct nameidata nd 结构体初始化完成之后,便进入路径解析的主要部分: link_path_walk() 函数。在这个函数里面,将路径名逐步解析,并最终找到目标文件的 struct dentry 结构体(保存在参数 struct nameidata *nd 中)。该函数很长,在这里,由于我们并不涉及链接文件以及特殊文件名(.和..)的解析问题,该函数可简化如下(忽略权限检查及错误处理):
/*
* Name resolution.
* This is the basic name resolution function, turning a pathname into
* the final dentry. We expect 'base' to be positive and a directory.
*
* Returns 0 and nd will have valid dentry and mnt on success.
* Returns error and drops reference to input namei data on failure.
*/
static int link_path_walk(const char *name, struct nameidata *nd)
{
int err;
if (IS_ERR(name))
return PTR_ERR(name);
while (*name=='/')
name++;
if (!*name) // if 判断为 0
return 0;
/* At this point we know we have a real path component. */
for(;;) {
u64 hash_len;
int type;
err = may_lookup(nd);
if (err) // if 判断为 0
return err;
hash_len = hash_name(nd->path.dentry, name);
type = LAST_NORM;
if (name[0] == '.') // if 判断为 0
// ......
if (likely(type == LAST_NORM)) { // if 判断为 1
struct dentry *parent = nd->path.dentry;
nd->flags &= ~LOOKUP_JUMPED;
if (unlikely(parent->d_flags & DCACHE_OP_HASH)) { // if 判断为 0
// ......
}
}
nd->last.hash_len = hash_len;
nd->last.name = name;
nd->last_type = type;
name += hashlen_len(hash_len);
if (!*name) // 除了路径中的最后一部分('test.txt')if 判断为 1,其他 if 判断为 0
goto OK;
/*
* If it wasn't NUL, we know it was '/'. Skip that
* slash, and continue until no more slashes.
*/
do {
name++;
} while (unlikely(*name == '/'));
if (unlikely(!*name)) { // if 判断为 0
OK:
/* pathname body, done */
if (!nd->depth)
return 0; // 解析到路径最后一部分时,该函数由此处返回
//......
} else {
/* not the last component */
err = walk_component(nd, WALK_FOLLOW | WALK_MORE); // err == 0
}
if (err < 0) // if 判断为 0
return err;
if (err) { // if 判断为 0
// ......
}
if (unlikely(!d_can_lookup(nd->path.dentry))) { // if 判断为 0
//......
}
}
// go back to for loop
}可见,该函数是在一个死循环 for(;;)里面对路径名中的每一个部分进行解析,完成解析后函数返回。解析前几个部分(home 、 sumu 和 7Linux)时,均调用 walk_component() 函数。
4.2.1 walk_component()
walk_component() 函数定义如下(以解析‘home’为例来分析该函数):
static int walk_component(struct nameidata *nd, int flags)
{
/* 函数入口参数: flags = WALK_FOLLOW | WALK_MORE */
struct path path;
struct inode *inode;
unsigned seq;
int err;
/*
* "." and ".." are special - ".." especially so because it has
* to be able to know about the current root directory and
* parent relationships.
*/
if (unlikely(nd->last_type != LAST_NORM)) { // if 判断为 0
//......
}
err = lookup_fast(nd, &path, &inode, &seq);
if (unlikely(err <= 0)) { // if 判断为 0,这里我们假设相应文件的 dentry 已经存在于系统缓存中
//......
}
return step_into(nd, &path, flags, inode, seq);
}其中我们调用了 lookup_fast() 函数,仍以解析第一部分 "home" 为例,此时该函数等价与如下:
static int lookup_fast(struct nameidata *nd,
struct path *path, struct inode **inode,
unsigned *seqp)
{
struct vfsmount *mnt = nd->path.mnt;
struct dentry *dentry, *parent = nd->path.dentry;
int status = 1;
int err;
/*
* Rename seqlock is not required here because in the off chance
* of a false negative due to a concurrent rename, the caller is
* going to fall back to non-racy lookup.
*/
if (nd->flags & LOOKUP_RCU) { // if 判断为 1
unsigned seq;
bool negative;
dentry = __d_lookup_rcu(parent, &nd->last, &seq);
if (unlikely(!dentry)) { // if 判断为 0
//......
}
/*
* This sequence count validates that the inode matches
* the dentry name information from lookup.
*/
*inode = d_backing_inode(dentry);
negative = d_is_negative(dentry);
if (unlikely(read_seqcount_retry(&dentry->d_seq, seq))) // if 判断为 0
return -ECHILD;
/*
* This sequence count validates that the parent had no
* changes while we did the lookup of the dentry above.
*
* The memory barrier in read_seqcount_begin of child is
* enough, we can use __read_seqcount_retry here.
*/
if (unlikely(__read_seqcount_retry(&parent->d_seq, nd->seq))) // if 判断为 0
return -ECHILD;
*seqp = seq;
status = d_revalidate(dentry, nd->flags);
if (likely(status > 0)) { // if 判断为 1
/*
* Note: do negative dentry check after revalidation in
* case that drops it.
*/
if (unlikely(negative)) // if 判断为 0
return -ENOENT;
path->mnt = mnt;
path->dentry = dentry;
if (likely(__follow_mount_rcu(nd, path, inode, seqp))) // if 判断为 1
return 1; // 函数从这里返回
}
//......
} else {
//......
}
//......
}其中函数 __d_lookup_rcu() 用来找到 "home" 对应的 dentry 结构体并返回其指针,具体过程此处不做分析。这里我们简单了解下 __follow_mount_rcu() 函数。该函数主要用来检查路径名是否是挂载点,如果是,则找到相应挂载的文件系统,并在挂载的文件系统下继续当前的文件解析工作(而不是在旧的文件系统下继续)。这里,仍以 "home" 为例,该函数定义:
/*
* Try to skip to top of mountpoint pile in rcuwalk mode. Fail if
* we meet a managed dentry that would need blocking.
*/
static bool __follow_mount_rcu(struct nameidata *nd, struct path *path,
struct inode **inode, unsigned *seqp)
{
for (;;) {
struct mount *mounted;
/*
* Don't forget we might have a non-mountpoint managed dentry
* that wants to block transit.
*/
switch (managed_dentry_rcu(path)) { // 跳转至 case 0:
case -ECHILD:
default:
return false;
case -EISDIR:
return true;
case 0:
break;
}
if (!d_mountpoint(path->dentry)) // if 判断为 0(对应'home'文件夹,则为 1
return !(path->dentry->d_flags & DCACHE_NEED_AUTOMOUNT);
mounted = __lookup_mnt(path->mnt, path->dentry);
if (!mounted) // if 判断为 1
break; // 结束循环
//......
}
return !read_seqretry(&mount_lock, nd->m_seq) &&
!(path->dentry->d_flags & DCACHE_NEED_AUTOMOUNT); // return 1
}其中 __lookup_mnt() 函数与 __d_lookup_rcu() 类似,只不过这里是找到挂载的文件系统,而不是 dentry。在这里,"home" 文件夹确实是一个挂载点,但在我的系统里面,并没有在该目录下挂载任何文件系统,因此, __lookup_mnt() 函数返回 0(找不到挂载在此处的文件系统)。其实相当于这个 for(;;)循环里面什么都没做,就退出了。最终该函数返回值为 1。这也合理,因为 "home" 下没有挂载任何文件系统,不需要 follow mount。
现在回到 walk_component() 函数,在这里面我们还需要分析另外一个函数: step_into() 。这个函数主要是处理符号链接的情况,在这里不涉及符号链接,该函数则很简单,定义如下:
/*
* Do we need to follow links? We _really_ want to be able
* to do this check without having to look at inode-> i_op,
* so we keep a cache of "no, this doesn't need follow_link"
* for the common case.
*/
static inline int step_into(struct nameidata *nd, struct path *path,
int flags, struct inode *inode, unsigned seq)
{
if (!(flags & WALK_MORE) && nd->depth) // if 判断为 0
put_link(nd);
if (likely(!d_is_symlink(path->dentry)) ||
!(flags & WALK_FOLLOW || nd->flags & LOOKUP_FOLLOW)) { // if 判断为 1
/* not a symlink or should not follow */
path_to_nameidata(path, nd);
nd->inode = inode;
nd->seq = seq;
return 0; // 函数由此处返回
}
//......
}其中 path_to_nameidata() 函数也很简单:
static inline void path_to_nameidata(const struct path *path,
struct nameidata *nd)
{
if (!(nd->flags & LOOKUP_RCU)) { // if 判断为 0
dput(nd->path.dentry);
if (nd->path.mnt != path->mnt)
mntput(nd->path.mnt);
}
nd->path.mnt = path->mnt;
nd->path.dentry = path->dentry;
}所以 step_into() 函数就相当于:
static inline int step_into(struct nameidata *nd, struct path *path,
int flags, struct inode *inode, unsigned seq)
{
nd->path.mnt = path->mnt;
nd->path.dentry = path->dentry;
nd->inode = inode;
return 0;
}4.3 总结
至此, walk_component() 函数分析完毕,我们返回其调用函数 link_path_walk() 。
我们发现 walk_component() 函数返回之后, link_path_walk() 函数的 for(;;)循环第一次循环执行完毕,也就表示对路径的第一部分 "home" 的解析完毕。不难想象,在第二次执行 link_path_walk() 函数的 for(;;)循环时,将会解析下一个路径,也就是 "sumu"。解析过程和 "home" 极为类似,这里不再重复分析,解析完毕之后,将解析结果同样存入 struct nameidata *nd 中,之前对 "home" 的解析结果则被覆盖。当第四次执行 for(;;)循环时,则解析最后一部分 "test.txt"。
对最后一部分的解析和前面的路径名解析稍有区别,不再调用 walk_component() 函数,而是直接返回到 path_openat() 函数,将最后解析工作留给 do_last() 函数来完成。
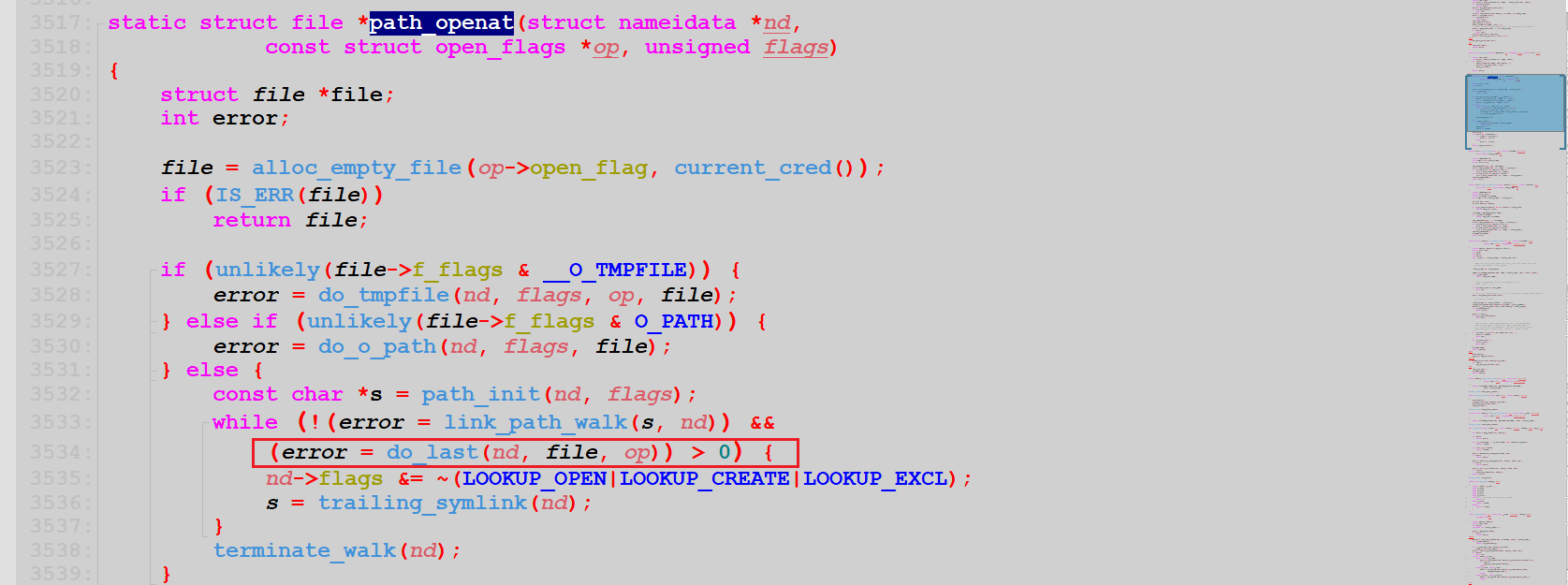
5. do_last()
do_last 函数定义在 namei.c - fs/namei.c - do_last:
/*
* Handle the last step of open()
*/
static int do_last(struct nameidata *nd,
struct file *file, const struct open_flags *op)
{
struct dentry *dir = nd->path.dentry;
int open_flag = op->open_flag;
bool will_truncate = (open_flag & O_TRUNC) != 0;
bool got_write = false;
int acc_mode = op->acc_mode;
unsigned seq;
struct inode *inode;
struct path path;
int error;
nd->flags &= ~LOOKUP_PARENT;
nd->flags |= op->intent;
if (nd->last_type != LAST_NORM) { // if 判断为 0
//......
}
if (!(open_flag & O_CREAT)) { // if 判断为 1
if (nd->last.name[nd->last.len]) // if 判断为 0
nd->flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
/* we _can_ be in RCU mode here */
error = lookup_fast(nd, &path, &inode, &seq);
if (likely(error > 0)) // if 判断为 1
goto finish_lookup; // 此处进行跳转
//......
} else {
//......
}
//......
finish_lookup:
error = step_into(nd, &path, 0, inode, seq);
if (unlikely(error))// if 判断为 0
return error;
finish_open:
/* Why this, you ask? _Now_ we might have grown LOOKUP_JUMPED... */
error = complete_walk(nd);
if (error) // if 判断为 0
return error;
audit_inode(nd->name, nd->path.dentry, 0);
if (open_flag & O_CREAT) { // 这里之前看的资料链接不太一样,这里也是直接跳过
//......
}
error = -ENOTDIR;
if ((nd->flags & LOOKUP_DIRECTORY) && !d_can_lookup(nd->path.dentry))// if 判断为 0
goto out;
if (!d_is_reg(nd->path.dentry))// if 判断为 0
will_truncate = false;
if (will_truncate) {// if 判断为 0
//......
}
finish_open_created:
error = may_open(&nd->path, acc_mode, open_flag);
if (error)// if 判断为 0
goto out;
BUG_ON(file->f_mode & FMODE_OPENED); /* once it's opened, it's opened */
error = vfs_open(&nd->path, file); // 这里是重点,真正执行文件打开的操作
if (error)// if 判断为 0
goto out;
opened:
error = ima_file_check(file, op->acc_mode);// 这里 error == 0
if (!error && will_truncate)// if 判断为 0,will_truncate == 0
error = handle_truncate(file);
out:
if (unlikely(error > 0)) {// if 判断为 0
//......
}
if (got_write)// if 判断为 0
mnt_drop_write(nd->path.mnt);
return error;
}我们看到在 do_last()函数调用 complete_walk()函数之前,分别调用了 lookup_fast()和 step_into()函数:
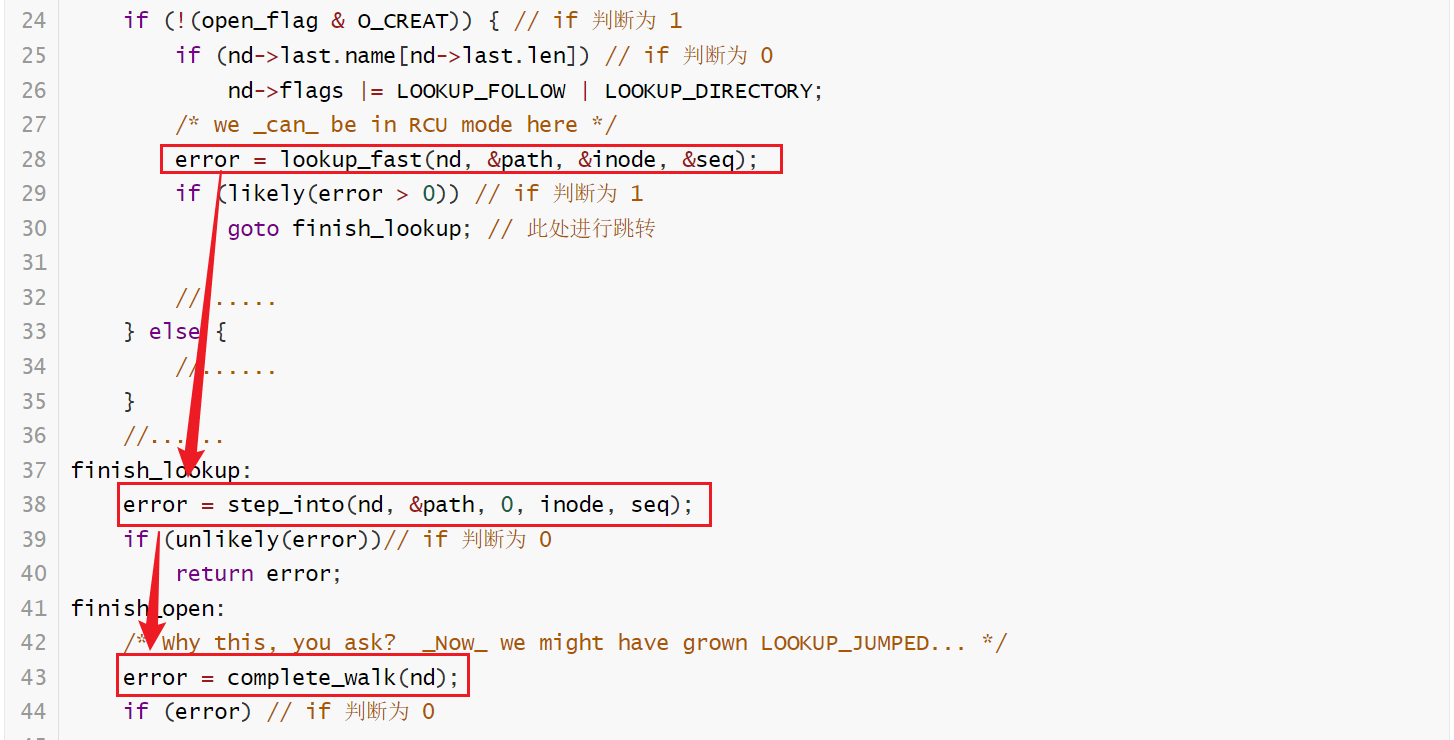
相当于调用了 walk_component()函数,找到文件路径最后一部分对应的 dentry,并存入到 struct nameidata nd 中。
5.1 complete_walk()
complete_walk() 函数定义如下:
/**
* complete_walk - successful completion of path walk
* @nd: pointer nameidata
*
* If we had been in RCU mode, drop out of it and legitimize nd-> path.
* Revalidate the final result, unless we'd already done that during
* the path walk or the filesystem doesn't ask for it. Return 0 on
* success, -error on failure. In case of failure caller does not
* need to drop nd-> path.
*/
static int complete_walk(struct nameidata *nd)
{
struct dentry *dentry = nd->path.dentry;
int status;
if (nd->flags & LOOKUP_RCU) { // if 判断为 1
if (!(nd->flags & LOOKUP_ROOT)) // if 判断为 1
nd->root.mnt = NULL;
if (unlikely(unlazy_walk(nd))) // if 判断为 0
return -ECHILD;
}
if (likely(!(nd->flags & LOOKUP_JUMPED))) // if 判断为 1
return 0; //函数返回
//......
}其中调用了 unlazy_walk() 这个函数。该函数定义:
/**
* unlazy_walk - try to switch to ref-walk mode.
* @nd: nameidata pathwalk data
* Returns: 0 on success, -ECHILD on failure
*
* unlazy_walk attempts to legitimize the current nd-> path and nd-> root
* for ref-walk mode.
* Must be called from rcu-walk context.
* Nothing should touch nameidata between unlazy_walk() failure and
* terminate_walk().
*/
static int unlazy_walk(struct nameidata *nd)
{
struct dentry *parent = nd->path.dentry;
BUG_ON(!(nd->flags & LOOKUP_RCU));
nd->flags &= ~LOOKUP_RCU;
if (unlikely(!legitimize_links(nd))) // if 判断为 0
goto out2;
if (unlikely(!legitimize_path(nd, &nd->path, nd->seq))) // if 判断为 0
goto out1;
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT)) { // if 判断为 0
//......
}
rcu_read_unlock();
BUG_ON(nd->inode != parent->d_inode);
return 0;
//......
}这里又有两个函数需要分析:legitimize_links() 和 legitimize_path() 。
5.1.1 legitimize_links()
legitimize_links() 是用来处理链接的,这里不涉及链接,因此该函数相当于空函数:
static bool legitimize_links(struct nameidata *nd)
{
int i;
for (i = 0; i < nd->depth; i++) { // 这里 nd-> depth = 0, 循环不执行
//......
}
return true;
}5.1.2 legitimize_path()
legitimize_path() 函数定义如下:
/* path_put is needed afterwards regardless of success or failure */
static bool legitimize_path(struct nameidata *nd,
struct path *path, unsigned seq)
{
int res = __legitimize_mnt(path->mnt, nd->m_seq);
if (unlikely(res)) { // if 判断为 0
//......
}
if (unlikely(!lockref_get_not_dead(&path->dentry->d_lockref))) {// if 判断为 0
//......
}
return !read_seqcount_retry(&path->dentry->d_seq, seq); // return 1
}我们来看一下__legitimize_mnt()函数。定义如下:
/* call under rcu_read_lock */
int __legitimize_mnt(struct vfsmount *bastard, unsigned seq)
{
struct mount *mnt;
if (read_seqretry(&mount_lock, seq)) // if 判断为 0
return 1;
if (bastard == NULL) // if 判断为 0
return 0;
mnt = real_mount(bastard);
mnt_add_count(mnt, 1);
smp_mb(); // see mntput_no_expire()
if (likely(!read_seqretry(&mount_lock, seq))) // if 判断为 1
return 0; // 函数返回
//......
}第 9 行:real_mount() 函数较为简单:
static inline struct mount *real_mount(struct vfsmount *mnt)
{
return container_of(mnt, struct mount, mnt);
}是将 struct vfsmount *mnt 转化为 struct mount *mount (前者是后者的一个成员变量,通过宏 container_of() 实现)。
第 10 行:mnt_add_count() 定义如下:
/*
* vfsmount lock must be held for read
*/
static inline void mnt_add_count(struct mount *mnt, int n)
{
#ifdef CONFIG_SMP
this_cpu_add(mnt->mnt_pcp->mnt_count, n); // 略去多核 cpu 同步等问题,等价与 mnt-> mnt_pcp-> mnt_count += n
#else
//......
#endif
}至此 legitimize_path() 函数分析完毕,好像就做了一件事:
container_of(nd->path->mnt)->mnt_pcp->mnt_count++;看起来也是关于同步问题处理相关的,就不深入分析了。
5.1.3 总结
complete_walk() 函数中我们关心的就是 unlazy_walk() 这个函数,这个函数最终其实就做了下面的事:
nd->flags &= ~LOOKUP_RCU;
container_of(nd->path->mnt)->mnt_pcp->mnt_count++;那么,整个 complete_walk() 函数相当于:
static int complete_walk(struct nameidata *nd)
{
nd->root.mnt = NULL;
nd->flags &= ~LOOKUP_RCU;
container_of(nd->path->mnt,struct mount, mnt)->mnt_pcp->mnt_count++;
return 0;
}5.2 audit_inode()
complete_walk() 函数执行完毕之后则进入 audit_inode() 函数,这个函数好像什么都没做,而且这个函数的定义依赖于 AUDIT 相关的内核配置,在某些内核配置下,这个函数的定义就是一个空函数。在这里我们不进行深入分析该函数。
5.3 may_open()
下面执行 may_open() 函数,该函数主要用来检查相应打开权限,这里我们暂不分析,简单认为权限检查没有问题。
5.4 总结
到这里,我们的 [do_last() 函数就分析的差不多了,但是还有一个最重要的函数 vfs_open() 。这个函数非常重要,可以说真正的“打开”操作是在这里进行的,前面所有的操作都是为了“找到”这个文件。后面我们重新开始一小节详细分析。
6. vfs_open()
vfs_open()定义在 open.c - fs/open.c - vfs_open:
/**
* vfs_open - open the file at the given path
* @path: path to open
* @file: newly allocated file with f_flag initialized
* @cred: credentials to use
*/
int vfs_open(const struct path *path, struct file *file)
{
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(path->dentry), NULL);
}这里又调用了 do_dentry_open()函数函完成文件打开的操作。
6.1 do_dentry_open()
do_dentry_open()函数定义在 open.c - fs/open.c - do_dentry_open:
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
static const struct file_operations empty_fops = {};
int error;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
/* Ensure that we skip any errors that predate opening of the file */
f->f_wb_err = filemap_sample_wb_err(f->f_mapping);
if (unlikely(f->f_flags & O_PATH)) { // if 判断为 0
//......
}
/* Any file opened for execve()/uselib() has to be a regular file. */
if (unlikely(f->f_flags & FMODE_EXEC && !S_ISREG(inode->i_mode))) {// if 判断为 0
//......
}
if (f->f_mode & FMODE_WRITE && !special_file(inode->i_mode)) { // if 判断为 0
//......
}
/* POSIX.1-2008/SUSv4 Section XSI 2.9.7 */
if (S_ISREG(inode->i_mode) || S_ISDIR(inode->i_mode)) // if 判断为 1
f->f_mode |= FMODE_ATOMIC_POS;
f->f_op = fops_get(inode->i_fop);
if (unlikely(WARN_ON(!f->f_op))) { // if 判断为 0
//......
}
error = security_file_open(f);
if (error)// if 判断为 0
goto cleanup_all;
error = break_lease(locks_inode(f), f->f_flags);
if (error)// if 判断为 0
goto cleanup_all;
/* normally all 3 are set; -> open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open) // if 判断为 1
open = f->f_op->open;
if (open) { // if 判断为 1
error = open(inode, f);
if (error) // if 判断为 0
goto cleanup_all;
}
f->f_mode |= FMODE_OPENED;
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
if ((f->f_mode & FMODE_READ) &&
likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&
likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
f->f_write_hint = WRITE_LIFE_NOT_SET;
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
/* NB: we're sure to have correct a_ops only after f_op-> open */
if (f->f_flags & O_DIRECT) {
if (!f->f_mapping->a_ops || !f->f_mapping->a_ops->direct_IO)
return -EINVAL;
}
return 0;
//......
}do_dentry_open()函数大部分在为进程生成的 struct file 进行赋值,填充了 struct file *file 的各个成员变量,并调用驱动程序中的 "open" 函数。
我们要关注下第 32 行:这一行是对于 struct file 的 f_op 进行赋值,该 f_op 的赋值会导致最终访问该文件时进行的 write()、read()的行为,这个是重中之重。
f->f_op = fops_get(inode->i_fop);struct file 中的 f_op 的是直接赋值为 inode→ i_fop,从从这里可以看出,驱动程序的 "open()" 函数其实是保存在 struct inode *inode 里面的,而 inode 又是保存在 struct dentry 里面的。通过读取相应的地址信息,并到“/proc/kallsys”里面进行查找,发现在上面 demo 中调用的驱动程序的“open”函数是“ext4_file_open()”。ext4_file_open() 函数这里我们不再进行深入分析了。
7. 各个函数返回
do_dentry_open() 函数在这里不再进行深入分析其中的每个函数调用。do_last()函数返回之后,回到 path_openat() 函数,由于 do_last() 函数返回值为 0,因此在 path_openat() 函数中退出 while()循环,进入到下一条语句:terminate_walk() 。
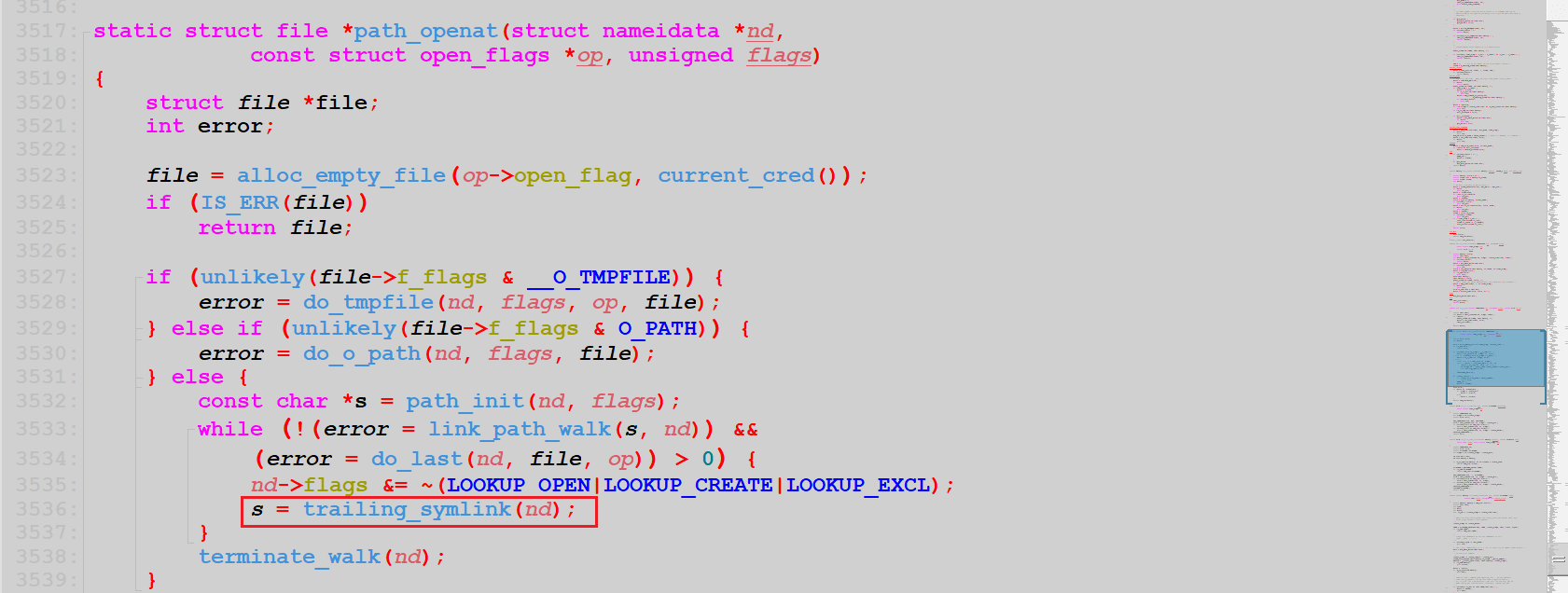
该函数定义如下:
static void terminate_walk(struct nameidata *nd)
{
drop_links(nd);
if (!(nd->flags & LOOKUP_RCU)) { // if 判断为 1
int i;
path_put(&nd->path);
for (i = 0; i < nd->depth; i++)// nd-> depth == 0, 空循环
//......
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT)) { // if 判断为 0
//......
}
} else {
//......
}
nd->depth = 0;
}在这个函数中,由于 drop_links() 是处理链接的情况,这个 demo 中不涉及,该函数为空函数。其中,path_put() 是进程同步相关操作,这里不进行分析。而 nd→ depth 本来就等于零,因此这里 terminate_walk() 除了进程同步操作之外,没有做其他工作。
terminate_walk() 函数结束之后,整个 path_openat() 函数也就返回了,回到 do_filp_open() 函数。do_filp_open() 函数在 path_openat() 函数执行完毕之后也就返回了。
现在回到最顶层函数:do_sys_open() 函数。下面将执行 fsnotify_open() 和 fd_install() 函数。 fsnotify_open() 函数在这里暂不详细分析,以后再说。
至此,整个 do_sys_open() 函数分析完毕。这里只以最简单的实例进行了初步分析,并发性问题的同步控制和权限检查以及错误处理都没有考虑。后面将会再详细分析 walk_component() 函数。
8. 总结
上面分析了那么多,涉及到大量的函数,大概了解一下就行,这里汇总一下函数调用关系:
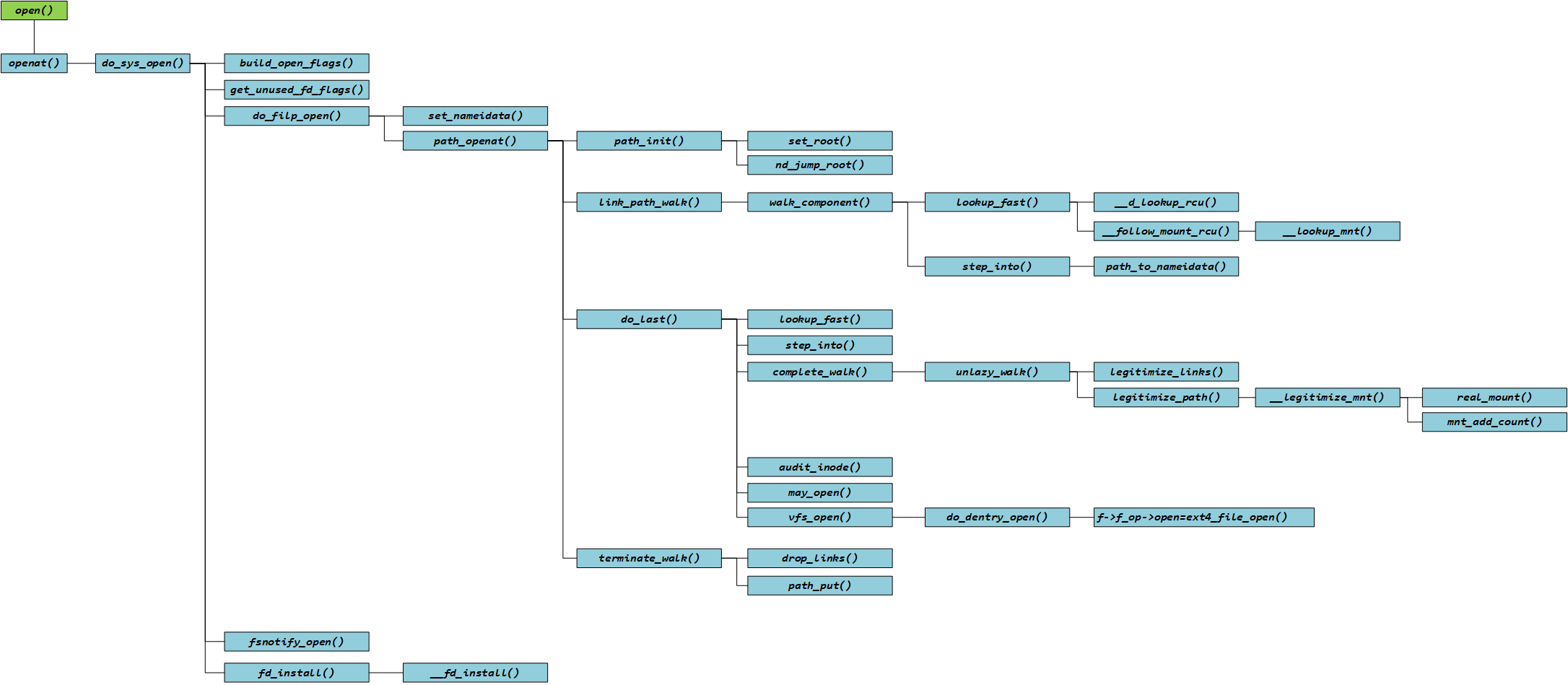
参考资料
Linux 中 open 命令实现原理以及源码分析_linux open-CSDN 博客