
LV005-LLM基础
一、AI
AI 是什么?
AI,即人工智能(Artificial Intelligence),是一门研究如何让机器模拟人类智能的学科。它涉及到构建可以感知、推理、学习和决策的智能系统,以 解决复杂问题和实现人类类似的任务。
一个有意思的问题:如何向人类同伴证明自己不是一个人工智能
二、大模型
1. 什么是大语言模型?
大语言模型(英文:Large Language Model,缩写 LLM),也称大型语言模型,是一种人工智能模型,就是我们平时听到的大模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM 的特点是 规模庞大,包含数十亿甚至数千亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种 NLP 任务上取得令人印象深刻的表现。
大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
2. 名称中的 B 是什么?
我们看到的大模型都会有一个多少 B 的描述,例如 Qwen3-Coder-480B、Qwen3-VL-8B-Instruct。这些名称中的 B 是什么意思?
在大模型领域,“B”代表的是“billion”,即十亿。当我们说一个模型是多少 B 时,通常指的是该模型所包含的参数数量达到了几十亿级别。例如,GPT-3 模型拥有 1750 亿个参数,可表述为 175B。参数数量越多,理论上模型能够学习和记忆的信息就越丰富,其对复杂数据模式的捕捉和表达能力也就越强。
3. Tokens
3.1 什么是Tokens
token 是大模型(LLM)用来表示自然语言文本的基本单位,可以直观的理解为 “字” 或 “词”。通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。
请说出以下字怎么读:
旯
妁
圳
侈
邯是不是发现竟然有些字不认识,或者说要愣一会才能念出来?那么再试一下下面的:
犄角旮(旯)
媒(妁)之言
深(圳)
奢(侈)
(邯)郸学步是不是一眼看过去就知道这个字念啥?为什么?这是因为我们大脑在日常生活中会把这些有含义的词语或者短语优先作为一个整体来对待,不到万不得已,不会一个字一个字去分析。这就会导致我们对于这些词语很熟悉,但是单独拎一个不常见的字出来可能就要反应一会了。
那为什么要这么做?因为这样可以节省脑力,比如“今天天气不错”这句话,要是一个字一个字处理,需要处理6个字之间的关系,但是要是划分成三个常见且有意义的词:”今天“ 、”天气“、”不错“,就只需要处理这三个词之间的关系了,从而提高效率。
那大模型肯定也可以这么做,所以就有了分词器,专门把大段的文字分解成一个一个的词,这里就被称之为 Token。不同的分词器分出来的结果肯定不同,分的越合理,大模型处理的时候就越轻松。
那怎么分词?有一种方法就是,分词器统计了大量的文本之后,发现“苹果”这两个词经常一起出现,那么就把这两个字打包成一个token,并分配一个数字编号给它,然后丢到一个大的词汇表里。
 |  |
这样下次再看到 “苹果” 这两个字的时候直接认出这个组合就可以了。然后在做另一段文本分析的时候发现 ”鸡” 这个字经常出现,并且可以搭配不同的其他字:
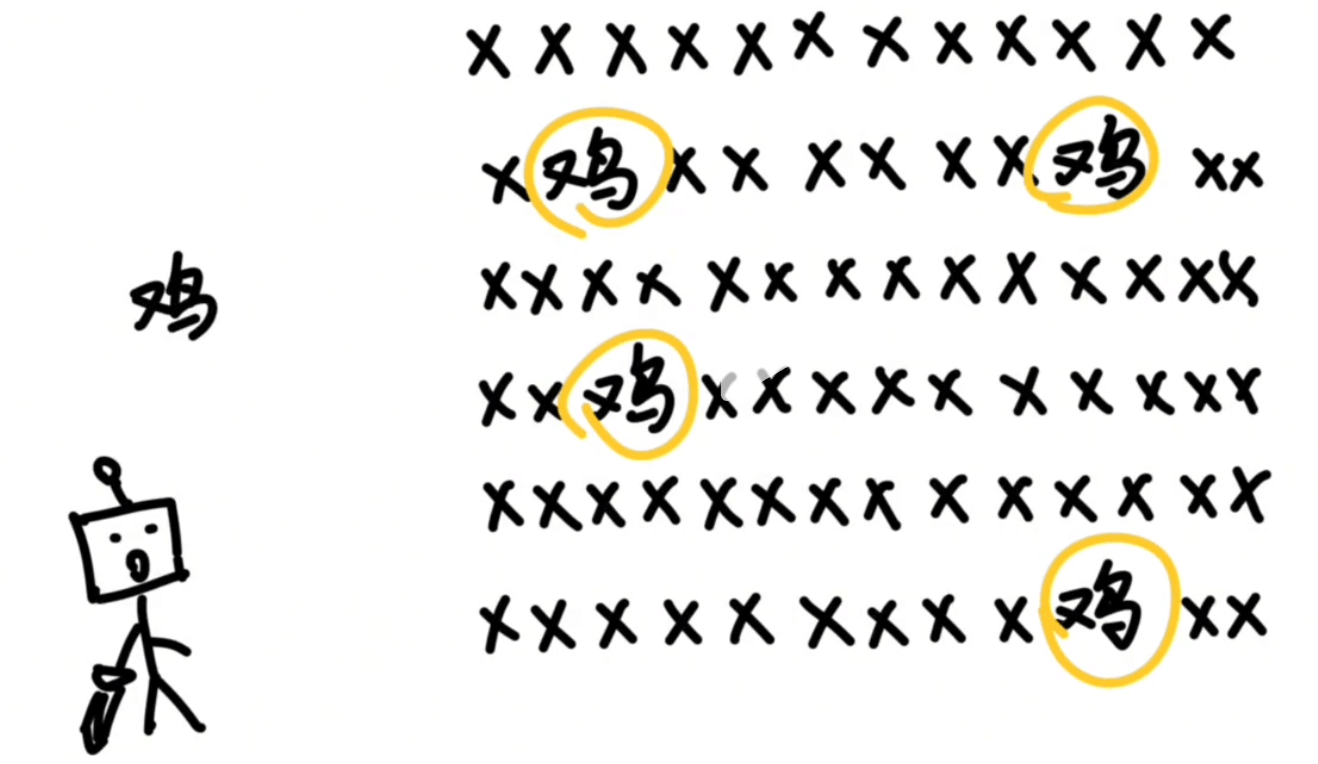 |  |
然后就把鸡这个字打包成一个token,配上一个编号,也放到词汇表里。然后又发现 “ing” 这三个字母经常一起出现,又把这三个字母打包成一个toke并配上一个编号,也扔到词汇表里去。
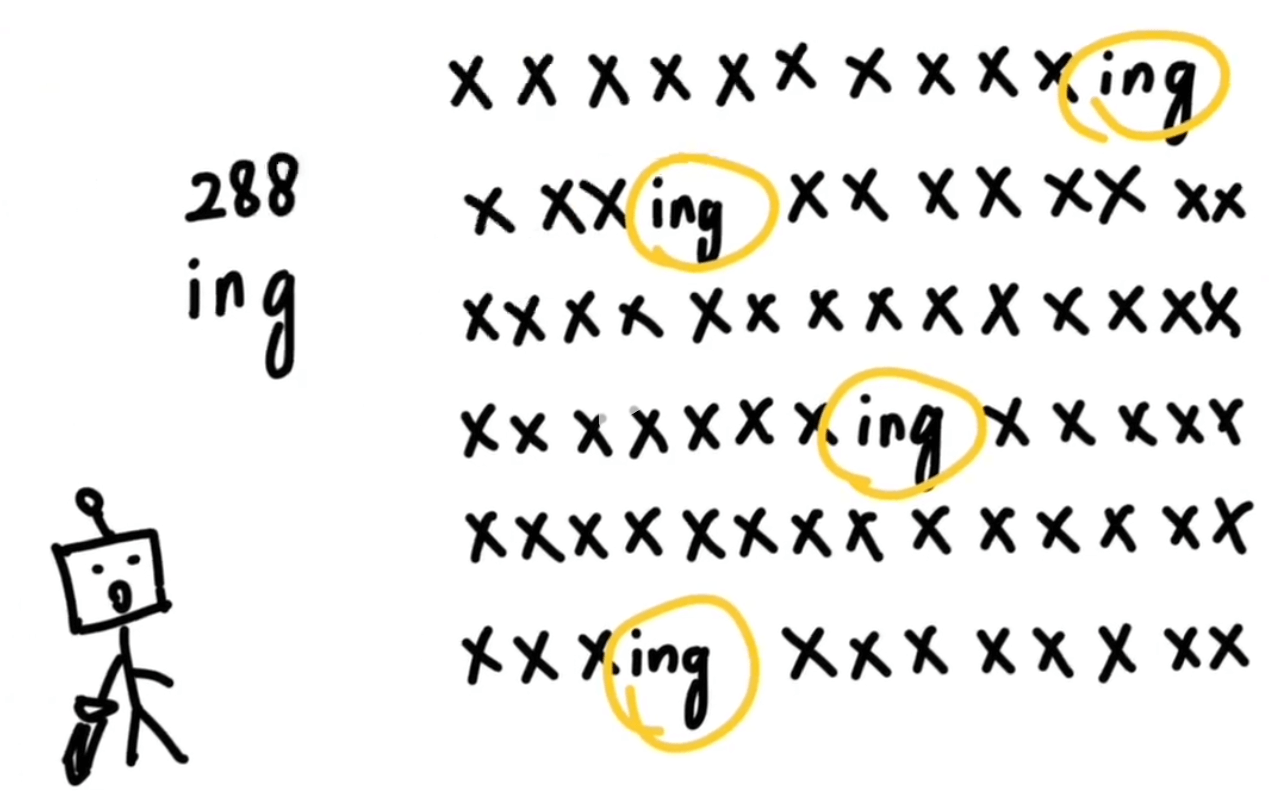 | 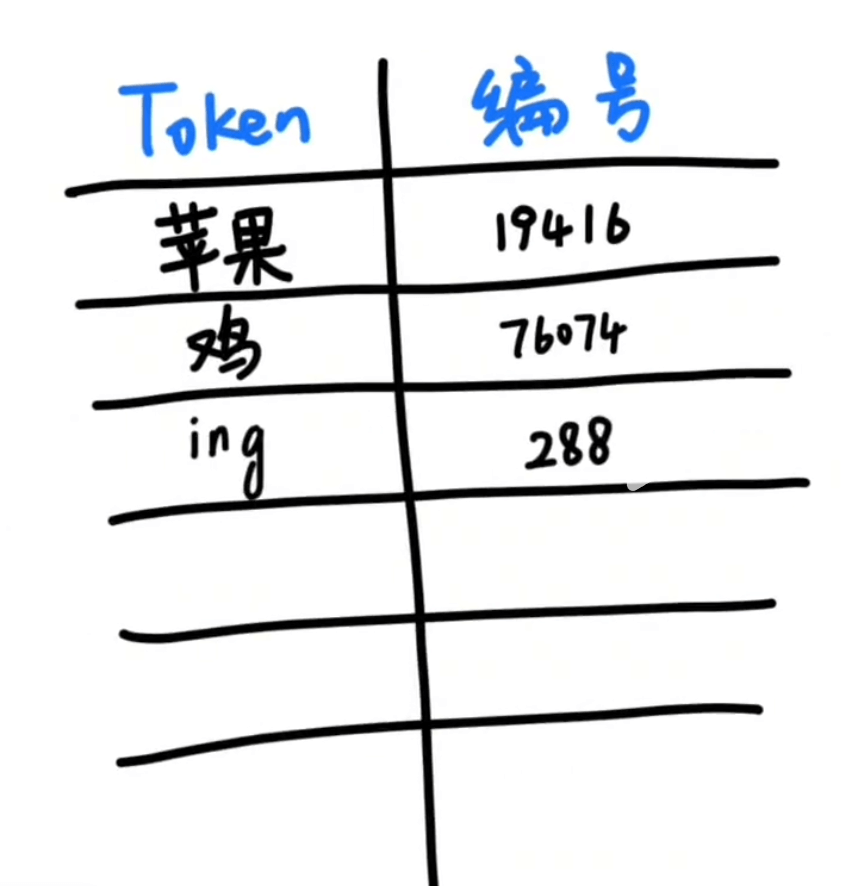 |
经过大量的统计和收集,分词器就会得到一个庞大的token表。可能有5万个、10万个,庞大到可以囊括我们日常能遇到的所有字、词、符号等,这样大模型在输入和输出的时候,都只需要面对一堆的数字编号就可以了,再由分词器按照token词汇表转换成我们可以看懂的文字和符号就可以了。
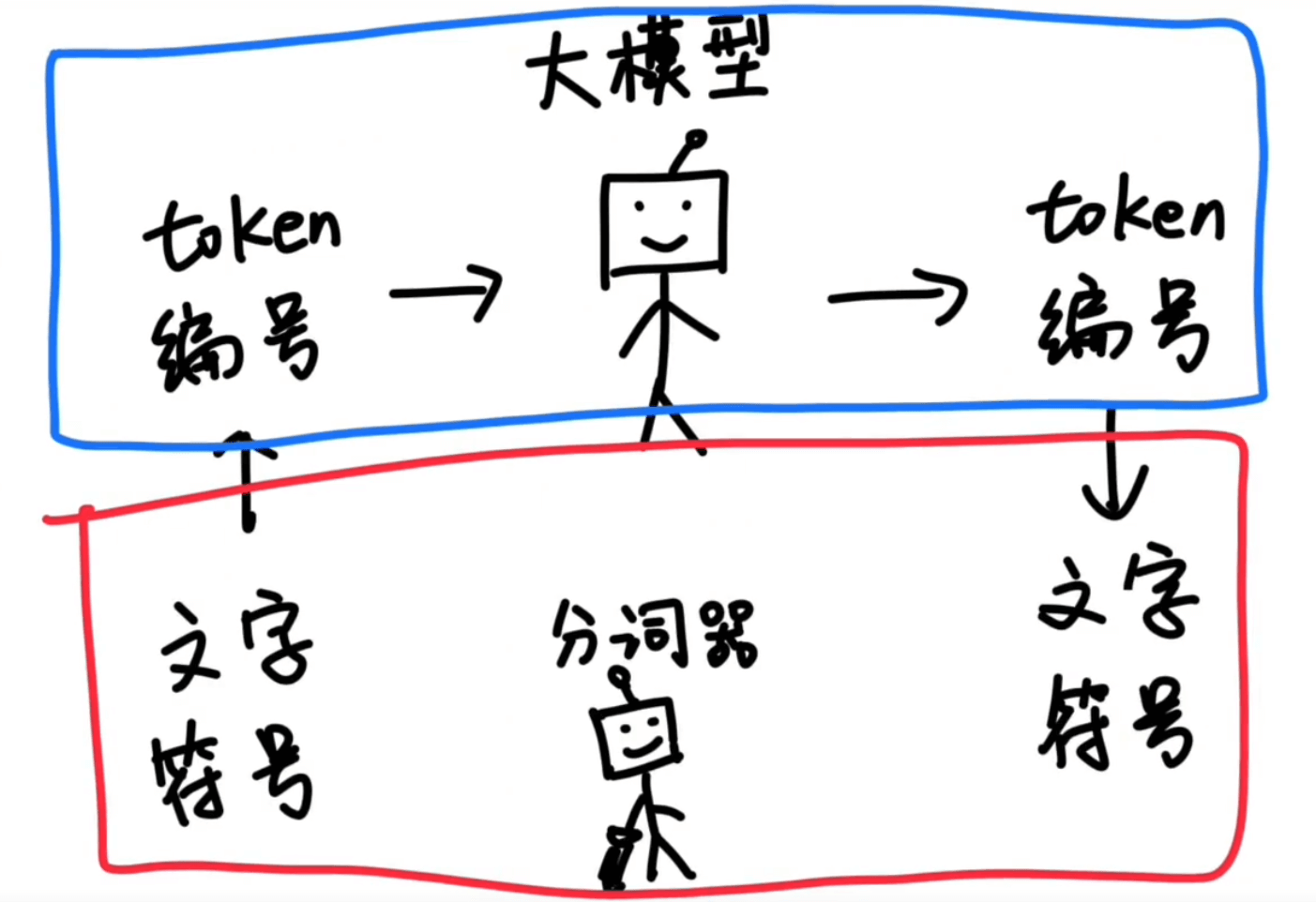
3.2 一个token是多少字数
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
这里有一个网站(Tiktokenizer),选择好模型然后输入文字,就可以帮我们计算输入的文字占用多少个token,还可以告诉我们每个token的编号。
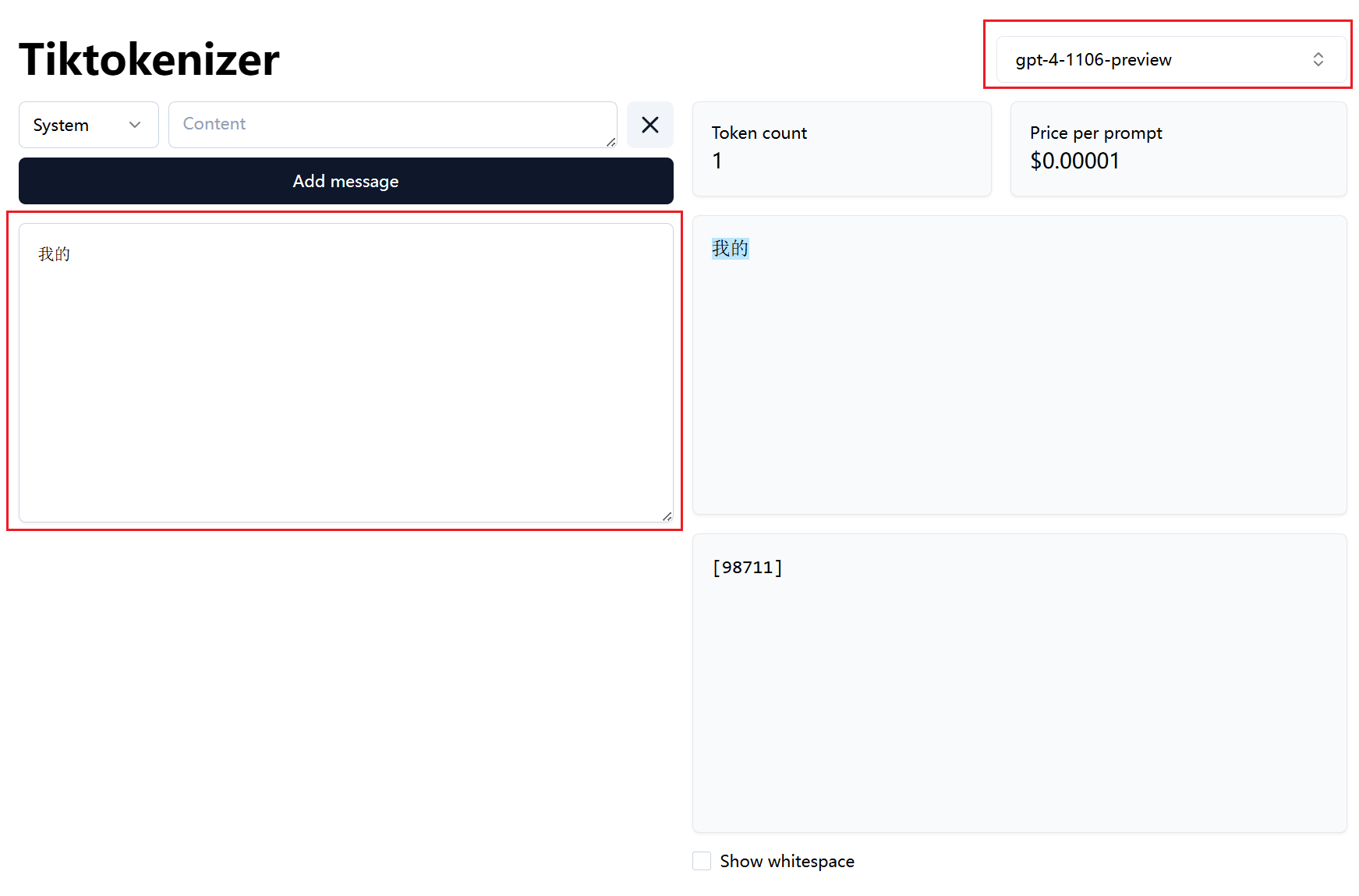
3.3 小结

4. 上下文长度
上下文长度” 在技术领域实际上有一个专有的名词:Context Window
LLM 的 Context Window 指模型在单次推理过程中可处理的全部 token 序列的最大长度,包括:
(1)输入部分(用户提供的提示词、历史对话内容、附加文档等)
(2)输出部分(模型当前正在生成的响应内容)
这里我们解释一下,比如当你打开一个 DeepSeek 的会话窗口,开启一个新的会话,然后输入内容,接着模型给我们输出内容。这就是一个 单次推理 过程。在这简单的一来一回的过程中,所有内容(输入+输出)的文字(tokens)总和不能超过 64K(约 6 万多字)。
那输入多少有限制吗?
有。上文我们介绍了 “上下文长度”,我们知道最长 8K,那么输入内容的上限就是:64K- 8K = 56K。总结来说在一次问答中,我们最多输入 5 万多字,模型最多给你输出 8 千多字。
那多轮对话呢?每一轮都一样吗?
不一样。这里我们要稍微了解一下多轮对话的原理
以 DeepSeek 为例,假设我们使用的是 API 来调用模型。多轮对话发起时,服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。可以看个代码调用示例:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "What's the highest mountain in the world?"}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}")
# Round 2
messages.append({"role": "user", "content": "What is the second?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")在第一轮请求时,传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]在第二轮请求时:
(1)要将第一轮中模型的输出添加到 messages 末尾
(2)将新的提问添加到 messages 末尾
最终传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]所以多轮对话其实就是:把历史的记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型。
那么在多轮对话的情况下,实际上并不是每一轮对话的 Context Window 都是 64K,而是随着对话轮次的增多 Context Window 越来越小。 比如第一轮对话的输入+输出使用了 32K,那么第二轮就只剩下 32K 了,原理正如上文我们分析的那样。
5. 上下文截断
如果按照上面这么说,那么我们每轮对话的输入+输出 都很长的话,那么用不了几轮就超过模型限制无法使用了啊。可是实际上却能正常使用,无论多少轮,模型都能响应并输出内容。(不过大部分还是有上限的,比如 Deepseek 官网的对话,其实一直对话的话也会有上限,提示达到最大,让重开窗口)
在我们使用基于大模型的产品时(比如 DeepSeek),服务提供商不会让用户直接面对硬性限制,而是通过 “上下文截断” 策略实现“超长文本处理”。
例如模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K tokens 供模型参考,前 2K 被丢弃。对用户来说,最后输入的内容被保留了下来,最早的输入(甚至输出)被丢弃了。
这就是为什么在我们进行多轮对话时,虽然还是能够得到正常响应,但大模型会产生 “失忆” 的状况。没办法,Context Window 就那么多,记不住那么多东西,只能 记住后面的忘了前面的。
这里请注意,“上下文截断” 是 工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。
三、部署大模型
1. 怎么获取大模型?
一般开源的大模型都是托管在Hugging Face上,这里使用的Qwen1.5-7B-Chat也不例外。不过Hugging Face在国内因为网络问题连接不上,因此可以使用镜像站HF-Mirror。Hugging Face上的大模型数据可以使用git工具来下载,不过大模型的单个文件可能比较大,需要开启git lfs,使用起来还是有点麻烦。感觉git还是不太适合管理非代码项目,因此还是推荐使用Hugging Face 官方提供的命令行工具huggingface-cli来下载大模型。
首先是安装依赖:
pip install -U huggingface_hub然后设置环境变量:
export HF_ENDPOINT=https://hf-mirror.com最后下载模型:
huggingface-cli download --resume-download Qwen/Qwen1.5-7B-Chat --local-dir Qwen1.5-7B-Chat2. 从入门到放弃
大语言模型要进行本地部署,先得选择一个与本地环境适配的模型。比如Qwen1.5-7B-Chat,那么可以计算一下需要的存储空间大小:
(1)这里的7B代表7-billion,也就是7×10⁹参数。
(2)每个参数是4字节浮点型。
(3)一次性加载所有参数需要7×10⁹×4 Bytes的存储空间
(4)7×10⁹×4 Bytes约等于28GB
入门消费级的显卡的显存是很少能满足这个存储要求的,比如我的R9000P,用的是NVIDIA GeForce RTX 3060 6GB的显卡(然后我选择直接放弃)。为了能在这台机器上使用Qwen1.5-7B-Chat,就要进行量化。“量化”是个很专业的词汇,但其实没那么难理解,简单来说就是“压缩精度”,或者“降低分辨率”的意思。比如全精度的模型参数是4字节浮点型,将其重新映射到8位整型:
| 原始值(FP32) | 量化后(INT8) |
|---|---|
| 0.123 | 15 |
| -0.456 | -58 |
| 0.999 | 127 |
实现原理很简单,就是把一个浮点范围(比如-1.0到+1.0)划分成256个离散的等级(因为 8-bit可以表示2⁸=256个值),然后每个原始值“四舍五入”到最近的那个等级。这种处理办法在信号处理或者数字图形处理中也非常常见。
如果使用8-bit量化,那么7B模型大概只需要7GB显存,理论是可以在8GB显存的机器上部署的。不过实际上大模型运行不是只有模型权重参数这么简单,实际的显存占用=模型权重+中间缓存+ 优化器状态+输入输出等,所以最好还是使用4-bit量化。
3. 为什么要看显卡?
CPU:设计目标是低延迟,擅长处理复杂但顺序的任务(如逻辑判断、分支跳转)。核心数量少(通常8-64个),但每个核心功能强大。
显卡是一个完整的硬件组件,除了GPU芯片外,还包括显存、散热系统、供电模块。
GPU(图形处理器)是核心处理器,专门设计用于并行计算和图形处理等。设计目标是高吞吐量,拥有数千个计算核心(如RTX 4090有16,384个CUDA核心),专为并行计算而生。
显存(VRAM)是显卡专用的内存,对于大模型部署至关重要,因为:
(1)模型存储:大模型的所有参数(权重、梯度等)必须加载到显存中才能被GPU快速访问。70亿参数(7B)模型,FP16精度需约 14GB显存(每个参数占用2字节)。
(2)计算缓冲:中间计算结果存储在显存中
(3)性能影响:显存大小直接决定能运行的模型规模
大模型(如GPT、LLaMA等)包含数十亿甚至上万亿个参数,训练和推理时需要同时进行海量矩阵运算(如矩阵乘法、卷积等),所以其实GPU是最适合跑大模型的。
参考资料: