
LV015-向量数据库
向量数据库是 RAG 系统的“语义底座”,使用什么数据库决定检索质量与系统可扩展性。
向量数据库在 RAG(Retrieval-Augmented Generation, 检索增强生成)系统中承担了向量化后的文本、图像、代码等数据的高效存储与近邻检索。实际工程中,向量数据库的选则直接影响系统性能、成本和后续扩展能力。
一、RAG 系统中的向量数据库

如图所示,向量数据库位于 Embedding 输出 与 Context 构建 之间,是信息检索质量的核心影响因素。
二、 常见的数据库
1. 可以选择哪些数据库啊?
| 方案 | 最佳使用场景 | 优势 | 局限 | 典型规模 |
|---|---|---|---|---|
| Chroma | 本地开发、轻量应用、桌面级 RAG | 零依赖、好用、迭代快 | 不适合超大规模/分布式 | ≤ 100 万向量 |
| Milvus | 企业级集群、十亿向量、多租户 | 高吞吐、GPU 索引、多副本 HA | 运维成本高 | 1 亿~10 亿向量 |
| Weaviate | 结构化 + 向量混合搜索、知识库 | GraphQL、Filter 强、插件丰富 | 部署复杂度略高 | 1 百万~5 亿 |
| PGVector | 已经大量使用 PostgreSQL 的团队 | 无需引入新系统、关系型融合 | 索引能力弱于专业库 | ≤ 数百万向量 |
| Qdrant | 高性能、快速落地、云原生 | Rust 实现、高并发、实时更新 | 生态略逊于 Milvus | 百万~数亿 |
| Pinecone(商用) | 不希望自运维、想快速上线 | 托管服务、全托管索引 | 成本较高、闭源 | 视套餐而定 |
总的来说,轻量用 Chroma,本地用 PGVector,大规模用 Milvus,语义 + 结构搜索用 Weaviate,全托管选 Pinecone,高性能选 Qdrant。
2. 数据库简介
2.1 Chroma
Chroma 是开源的 AI 应用数据库。Chroma 通过让知识、事实和技能可作为大模型的插件,使构建大模型应用变得简单。
Chroma 采用模块化架构设计,注重性能和易用性。它能从本地开发无缝扩展到大规模生产环境,同时在所有部署模式下提供一致的 API。无论采用何种部署模式,Chroma 都由五个核心组件构成。每个组件在系统中都扮演着独特的角色,并基于共享的 Chroma 数据模型 运行。
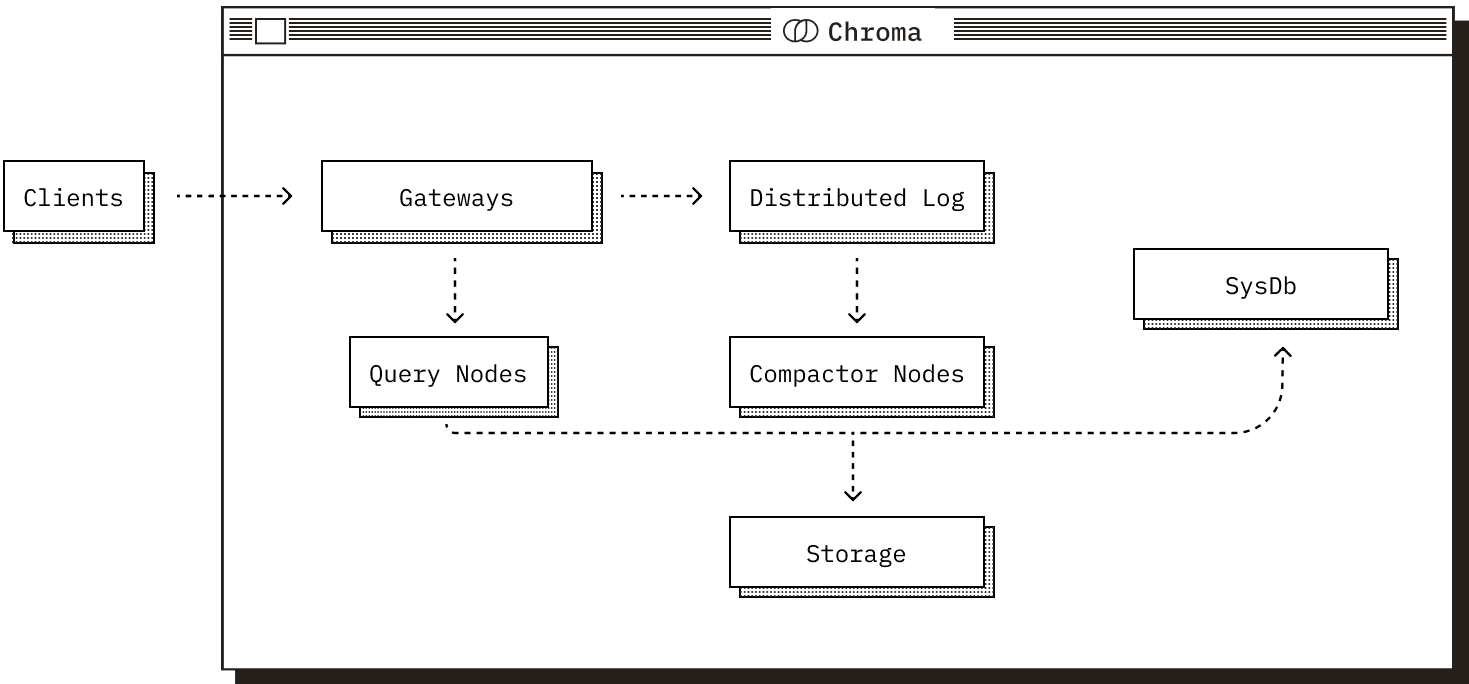
更深入的了解可以看官网文档:Introduction - Chroma Docs
2.2 Milvus(分布式架构)
Milvus 是一个 开源 云原生 向量数据库,专为在海量向量数据集上进行高性能相似性搜索而设计。它建立在流行的向量搜索库(包括 Faiss、HNSW、DiskANN 和 SCANN)之上,可为人工智能应用和非结构化数据检索场景提供支持。
下图说明了 Milvus 的高层架构,展示了其模块化、可扩展和云原生的设计,以及完全分解的存储层和计算层。
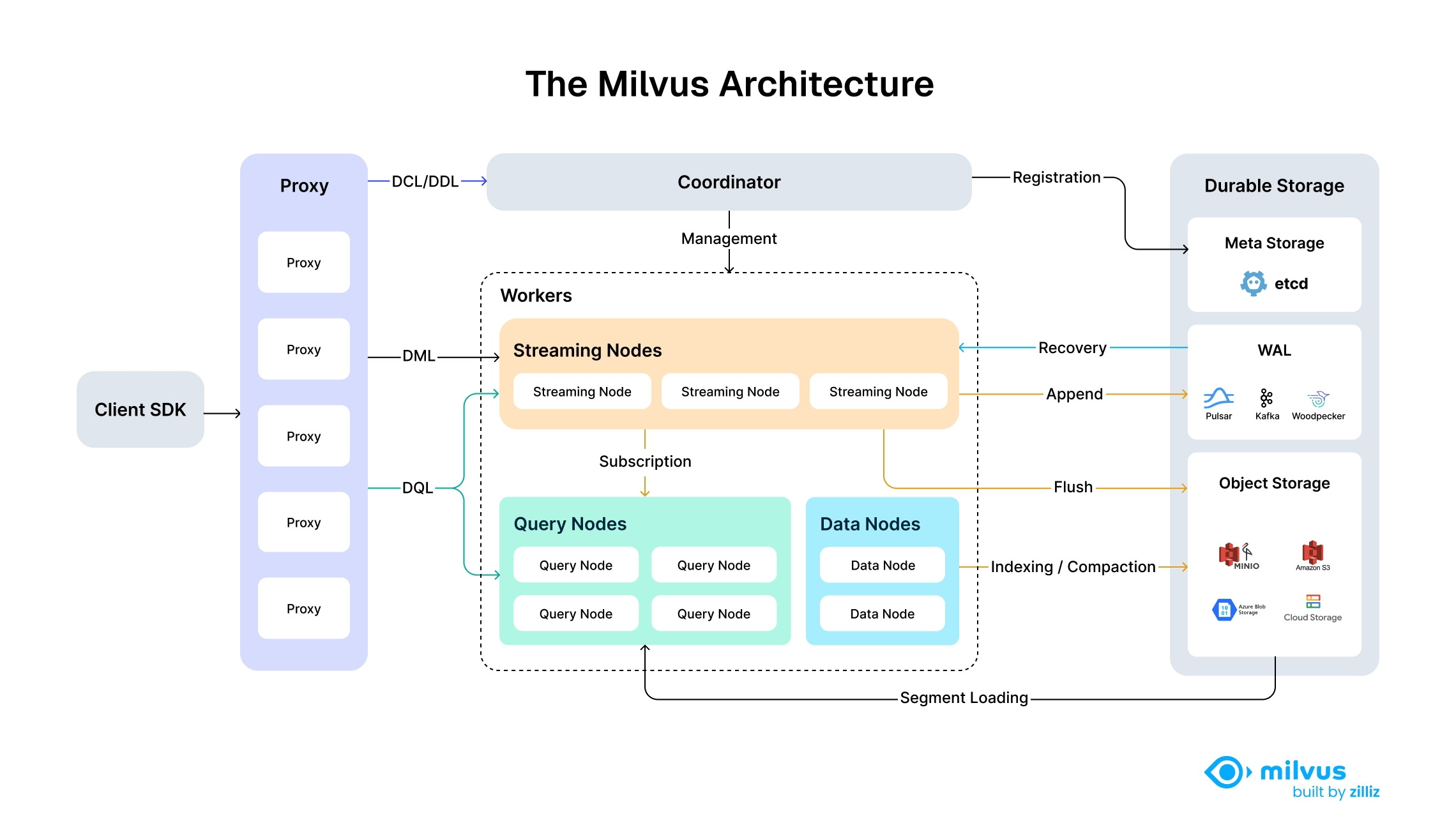
Milvus 遵循数据平面和控制平面分解的原则,由四个主要层组成,在可扩展性和灾难恢复方面相互独立。这种共享存储架构具有完全分解的存储层和计算层,可实现计算节点的横向扩展,同时将啄木鸟作为零磁盘 WAL 层实施,以增强弹性并减少操作开销。
通过将流处理分为流节点(Streaming Node)和批处理分为查询节点(Query Node)和数据节点(Data Node),Milvus 在满足实时处理要求的同时实现了高性能。
更深入的了解可以看官方文档:Milvus 架构概述 | Milvus 文档
2.3 Weaviate(模块化插件架构)
Weaviate 是一个开源的人工智能向量数据库。擅长多模态检索与结构化数据混合搜索,插件生态丰富。

它的一些基本概念可以看这里:Concepts | Weaviate Documentation
2.4 PGVector(关系型融合)
pgvector 是 Postgres 的开源向量相似度搜索,支持精确和近似最近邻搜索,基本架构如下:

PGVector 无需引入额外组件,是最“成本友好”的解决方案,适合小规模或已有 PostgreSQL 资产的场景。
3. 工程实践中的建议
| 工程点 | 建议 |
|---|---|
| 索引选型 | Milvus 用 IVF+PQ;Qdrant/Weaviate 用 HNSW;PGVector 优先 HNSW |
| Embedding 维度 | 低维度更快;高维度更准,但更吃内存 |
| Metadata Filter | 所有向量库都支持,但 Weaviate / Qdrant 最强 |
| 多模态检索 | Weaviate(最完善) |
| 可观测性 | Milvus、Qdrant 表现最佳 |
| 向量更新频率 | Qdrant 更新性能优于 Milvus |
三、总结
向量数据库不是“越强越好”,而是应根据预算、团队能力、数据规模、更新频率、部署环境来选择。在 AI Native 系统中,它本质上是:
- 语义检索引擎
- 上下文质量的决定因素
- RAG 能否扩展到企业级的关键瓶颈点
合理的选则与调优能使 RAG 系统在准确率、召回率、延迟与成本之间做到最佳平衡。