
LV010-词嵌入
一、词嵌入(Word Embedding)
1. 基本概念
词是自然语言表义的基本单元。我们之所以认识词语,是因为我们大脑中建立了很多映射连接。那计算机怎么去识别呢?
自然语言需要翻译成机器语言才能为机器处理。这也是词嵌入引出的原因:把词映射为实数域向量的技术也叫词嵌入(word embedding),核心思想就是见每个词映射成低维空间(通常 K = 50-300 维)上的一个稠密向量(Dense Vector)。
单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本 X{x12345……xn12345……yn },这个映射的过程就叫做 词嵌入。
推荐一个项目:webvectors,它是一个用于在网络上提供向量语义模型(特别是基于预测的词嵌入模型,如 word2vec 或 ELMo)的工具包。它旨在简化向公众展示这些模型的能力,使得非专业人士也能轻松理解和使用这些先进的自然语言处理技术。WebVectors 支持多种语言,包括俄语、英语和挪威语,并且提供了直观的用户界面,让用户能够通过简单的查询来探索词向量的奥秘。
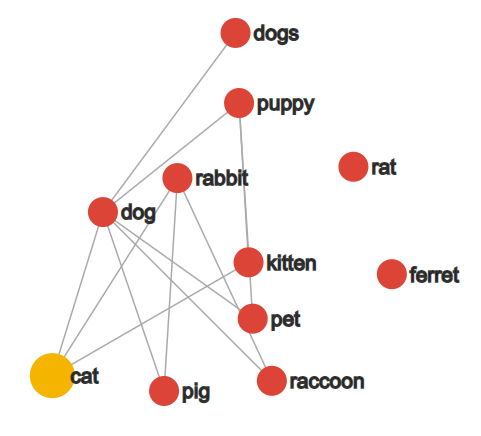
2. 类比
2.1 国王与女王的实例
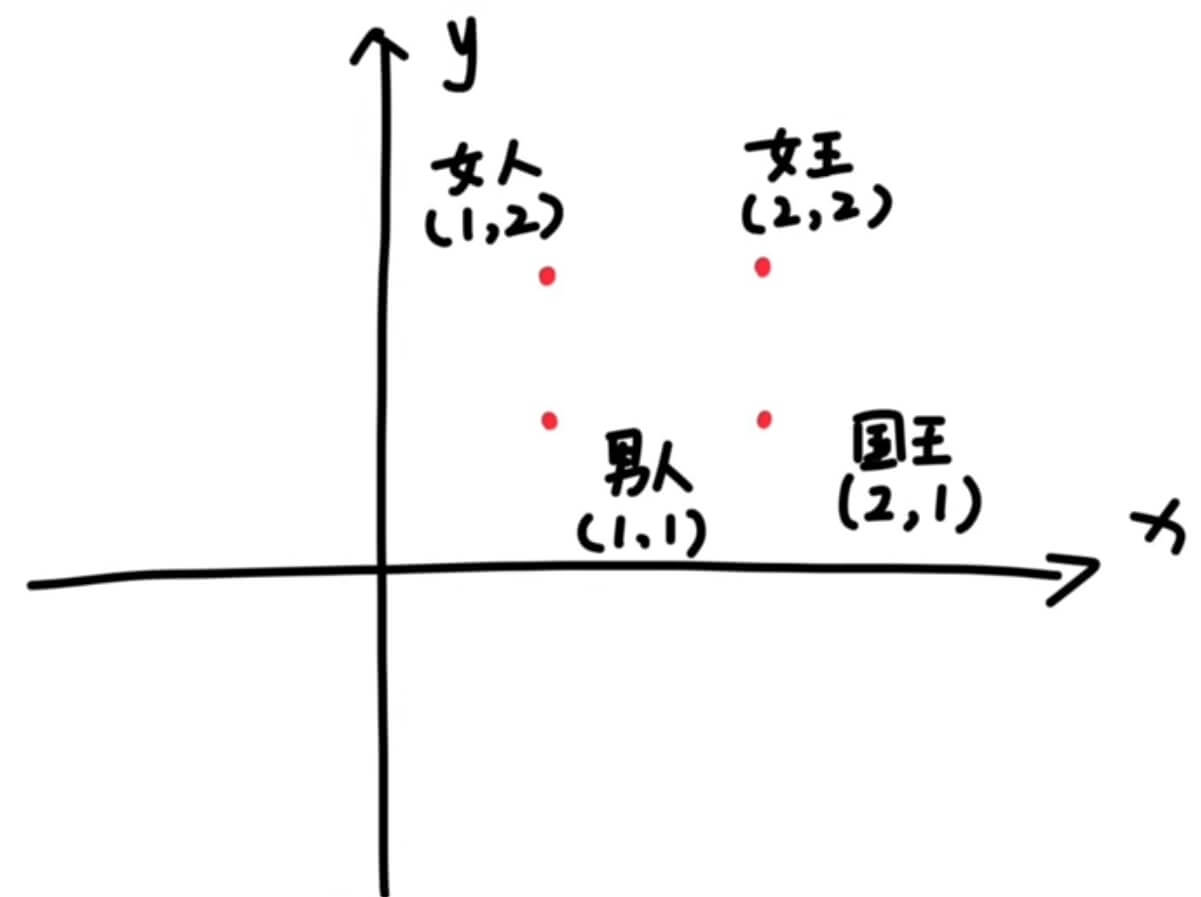
词向量有一个神奇的特性,那就是:我们往往可以通过向量的算术来实现单词的类比。最著名的例子就是:

即「国王 - 男人 + 女人 ≈ 女王」。
但这是为什么呢?为什么算术运算符适用于像「word2vec」这样的非线性模型生成的向量呢?在向量空间中,要想通过训练语料库使这些类比成立需要满足什么条件?很少有理论试图解释这种现象,而那些现有的理论对词频或向量空间做出了很强的假设。发表在 ACL 2019 上的论文「Towards Understanding Linear Word Analogies」中在不做出这种强假设的条件下,针对「GloVe」和「基于负采样的 skipgram」两种嵌入模型提出了词类比运算的正式解释。
我们想象一下,从地位上来看,他们两个是不是等同的呢?我们用数字 2 带代表地位这个方面:
| 地位 | |
|---|---|
| 国王 | 2 |
| 女王 | 2 |
但是,这两者并不完全是等同的,比如性别我们现在用 1 表示男性,用 0 表示女性,那么就有
| 地位 | 性别 | |
|---|---|---|
| 国王 | 2 | 1 |
| 女王 | 2 | 0 |
这个时候,除国王和女王外,我们把男人和女人的地位表示为 1,在地位上,国王和普通民众确实是不同的,这个时候我们把他们写到一起:
| 地位 | 性别 | |
|---|---|---|
| 国王 | 2 | 1 |
| 女王 | 2 | 0 |
| 男人 | 1 | 1 |
| 女人 | 1 | 0 |
这个时候,我们要是把这些写成数学中向量的格式:
向量的加减法如下:
那么这个时候,我们想一下,在这个王国中,只有这四种人,普通男人,女人,国王或者女王,国王如果不是男的,那肯定就是女的了,我们这样计算
这里我们其实是在做一个二维向量的加减法,一个也可以看出,一个二维向量,表示出了国王、女王、男人和女人这四者之间的关系,我们可以把地位、性别称之为 维度。我们把向量放到对应的空间坐标系中,其实就相当于把这个词语放在了对应的空间,二维的可以放在二维平面,三维的放在三维平面,n 维的放在 n 维平面,这个就可以理解为嵌入,词嵌入就可以理解为吧一个词转换为 n 维向量,然后嵌入到对应的空间中。
2.2 猫
猫的种类繁多,我们以这个为例,再来看一下,下面十几只猫的图片,上面数字表示体长。

- (1)我们先用体长来对比区分下,用一条坐标轴来表示体长。

这些猫就都会落在这个坐标轴上不同的点,有不同的体长数字。但一个体长不足以区分它们。 三花猫、蓝猫的体长都是 0.42 米,蓝白英短、苏格兰折耳猫都是 0.29 米。
- (2)这个时候就需要第二个维度了,比较它们的体重。
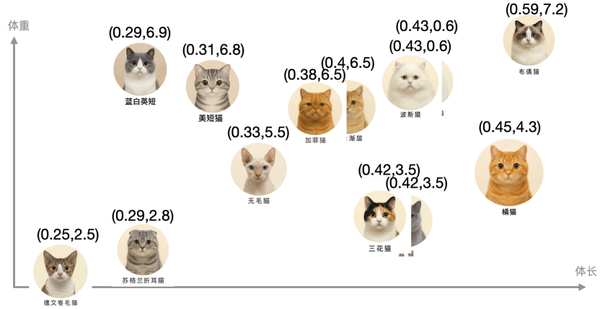
这样蓝白英短、苏格兰折耳猫就区分开了,它们的体重不一样,一个是 6.9KG,一个是 2.8KG。这个时候每个猫的特征,就用了两个数字来表示,可以认为是一个二维的向量,这些向量存在一个二维的坐标系中。但还是有些猫的特征非常接近,比如波斯猫和临清狮子猫。
- (3)所以这里添加第三个维度,耳朵长度。
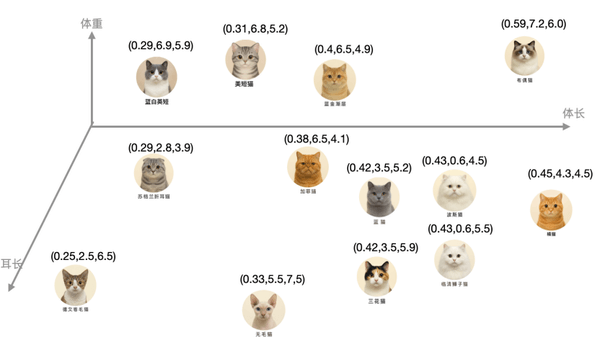
这样就能把它们区分开。这时表示每个猫的特征,就用到了一个三维向量。
- (4)同样的道理,我们可以拓展到四维、五维……更高维度。
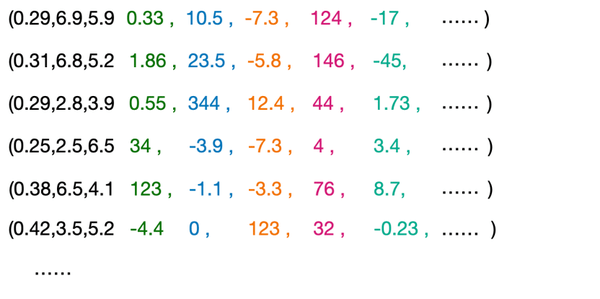
虽然身为三维生物的我们,很难想象更高维的场景,但数字上的维度增加很容易理解。就是增加更多区分的数字。从三维,变成更高维的向量。
- (5)把猫换成词语(token),这个过程就是词语拓展到高维的情况。
词语之间语义产生差异的维度太多了,不过仍然是可以穷举的。我们就穷举出所有能想象维度。x 轴代表发生时间差别,z 轴代表褒义贬义差别,z 轴代表静止或移动.......神经网络就是这么干的,用众多维度来区分词语的这些差异。
3. 相似?
前面我们通过实例,了解了词嵌入是什么,那么我们怎么知道两个词是相似的还是完全不相关?计算相似度的方法有很多,例如 余弦相似度、Jaccard 相似度、编辑距离、词向量模型 等。详细的就暂时不去看了,简单看一下余弦相似度,其实这个就是向量是否相似的判定方法
余弦相似度是一种常用的度量两个非零向量之间相似度的方法,广泛应用于文本挖掘、推荐系统等领域。该算法通过测量两个向量之间的夹角的余弦值来评估它们的相似度。理论上,两个向量的方向越接近,它们的余弦相似度就越高。余弦值为 1 表示两个向量方向完全相同,为 0 表示两者正交,而为 -1 则表示两者方向完全相反。
给定两个向量 cos(θ) 可以通过下面的公式计算得出:
其中,(A · B) 表示 A 和 B 的点积,而 ||A|| 和 ||B|| 分别表示 A 和 B 的欧氏范数(即向量的长度)。
可以根据这个值来简单表示两个向量是否相似,我们用上面猫的实例做一个计算,我们计算一些蓝白英短(0.29,6.9,5.9)、美短猫(0.31,6.8,5.2)和三花猫(0.42,3.5,5.9)
蓝白英短(0.29,6.9,5.9)和美短猫(0.31,6.8,5.2)的余弦相似度为:
蓝白英短(0.29,6.9,5.9)和三花猫(0.42,3.5,5.9)的余弦相似度为:0.9464。所以其实白英短(0.29,6.9,5.9)和美短猫(0.31,6.8,5.2)更像,从图片上看也是更像,从空间上,两者的距离也更近。
这里是我写的一个计算的 Python 脚本:
pythonimport numpy as np import math def cosine_similarity_raw(vec1, vec2): """ 使用原始公式计算两个向量之间的余弦相似度 余弦相似度公式: cos(θ) = (A · B) / (||A|| × ||B||) 其中: - A · B 是向量点积 - ||A|| 和 ||B|| 是向量的模长 参数: vec1: 第一个向量 (list or numpy array) vec2: 第二个向量 (list or numpy array) 返回: 余弦相似度值 (float) """ # 转换为 numpy 数组 vec1 = np.array(vec1, dtype=np.float64) vec2 = np.array(vec2, dtype=np.float64) # 检查向量维度是否相同 if vec1.shape != vec2.shape: raise ValueError("向量维度不匹配") # 计算点积 (A · B) dot_product = np.sum(vec1 * vec2) # 计算向量模长 ||A|| 和 ||B|| magnitude_vec1 = math.sqrt(np.sum(vec1 * vec1)) magnitude_vec2 = math.sqrt(np.sum(vec2 * vec2)) print(f"dot_product={dot_product}, magnitude_vec1={magnitude_vec1}, magnitude_vec2={magnitude_vec2}") # 避免除零错误 if magnitude_vec1 == 0 or magnitude_vec2 == 0: return 0.0 # 计算余弦相似度 cosine_sim = dot_product / (magnitude_vec1 * magnitude_vec2) return cosine_sim def cosine_similarity_matrix(vectors): """ 计算向量集合中每对向量之间的余弦相似度矩阵 参数: vectors: 向量列表 (list of lists or numpy arrays) 返回: 余弦相似度矩阵 (numpy array) """ n = len(vectors) similarity_matrix = np.zeros((n, n)) for i in range(n): for j in range(n): similarity_matrix[i][j] = cosine_similarity_raw(vectors[i], vectors[j]) return similarity_matrix # 示例和测试 if __name__ == "__main__": print("=== 余弦相似度计算示例 ===") print("余弦相似度范围: [-1, 1]") print("- 1 表示完全相同方向") print("- 0 表示垂直(无关)") print("- -1 表示完全相反方向") print() # 测试向量 vector_a = [0.29,6.9,5.9] vector_b = [0.31,6.8,5.2] vector_c = [0.42,3.5,5.9] print(f"向量 A: {vector_a}") print(f"向量 B: {vector_b}") print(f"向量 C: {vector_c}") print() # 计算相似度 sim_ab = cosine_similarity_raw(vector_a, vector_b) sim_ac = cosine_similarity_raw(vector_a, vector_c) print("=== 计算结果 ===") print(f"A 和 B 的余弦相似度: {sim_ab:.6f}") print(f"A 和 C 的余弦相似度: {sim_ac:.6f}") print() # 验证相同向量的相似度为 1 sim_aa = cosine_similarity_raw(vector_a, vector_a) print(f"A 和 A 的余弦相似度 (应为1): {sim_aa:.6f}") print()
4. 大模型是怎么理解的
前面大概了解了词嵌入是什么意思,那么词嵌入的值是怎么定出来的?一开始的时候其实都是随机的,但是在大模型训练的过程中,会根据人类现有的文字分布规律,把每一个词嵌入到合适的位置去,意思相近的词放的更近一些,训练完后,词语和词语的位置关系就可以体现出语义的关系。
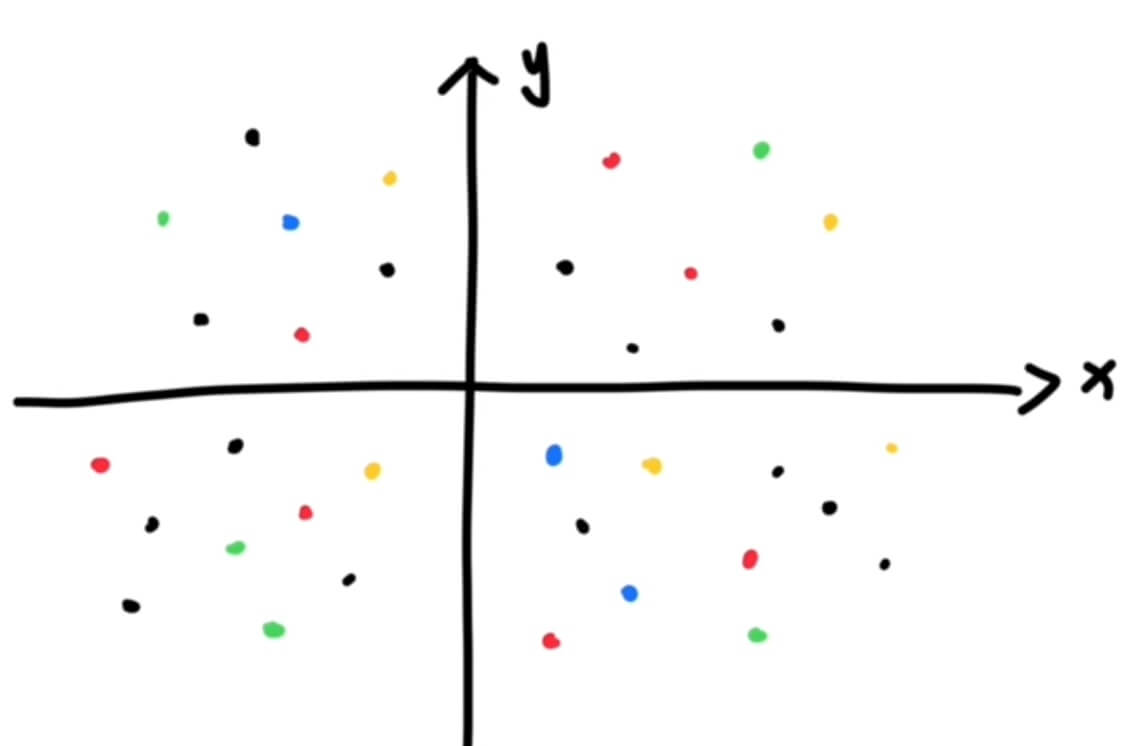 | 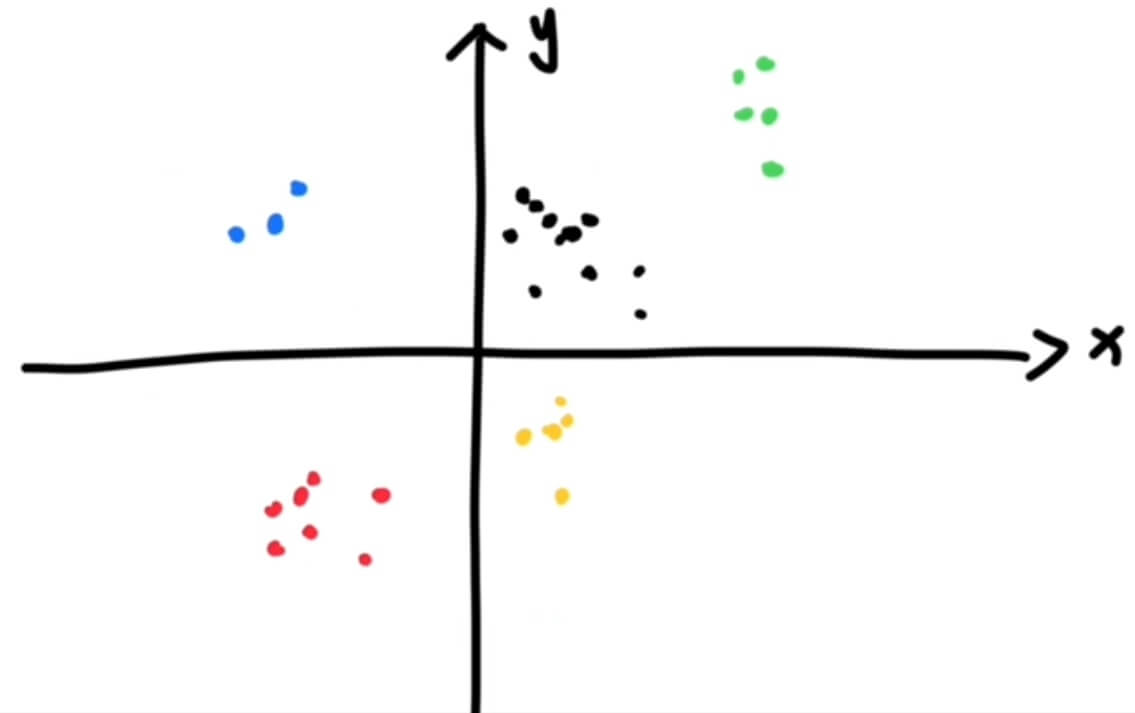 |
其实一个词的含义,本质上就是由 他和其他词的关系决定 的,我们在解释一个词的时候,会有一些其他的词语来解释这个词,解释的这些词右需要用另外一批词来解释:
所以在空间上的位置关系,就可以体现出每一个词的含义,用的数字越多,就描述的越细致。
那这个时候有一个问题,就是像苹果这个词,既可以表示水果,也可以表示 Apple 公司,那怎么区分这个?词嵌入的位置是离水果更近还是离公司品牌更近呢?
其实一开始,苹果这个词的词向量是处于一个中间状态,当它和其他的词出现在一起发生计算的时候就会改变原来的值,变成代表某一种具体含义的词向量的值。例如,和吃字放在一起的的时候,吃字和苹果发生计算,苹果的词向量更新为表示水果的那个 苹果,当和手机或者公司放在一起的时候,就会吧苹果的词向量更新为表示公司品牌的那个苹果。这其实就是 Contextual Word Embeddings,即上下文化词向量。
5. 小结
词向量的本质:自然语言的语义在数学空间的表示。简单来说词向量就是用来描述每个词的特征,让计算机能“认识”每个词。
维度:每个维度都代表一个事物的某个特征。例如某几维在编码情感、某几维在编码地理位置、某几维在编码类别等。
二、词向量的发展
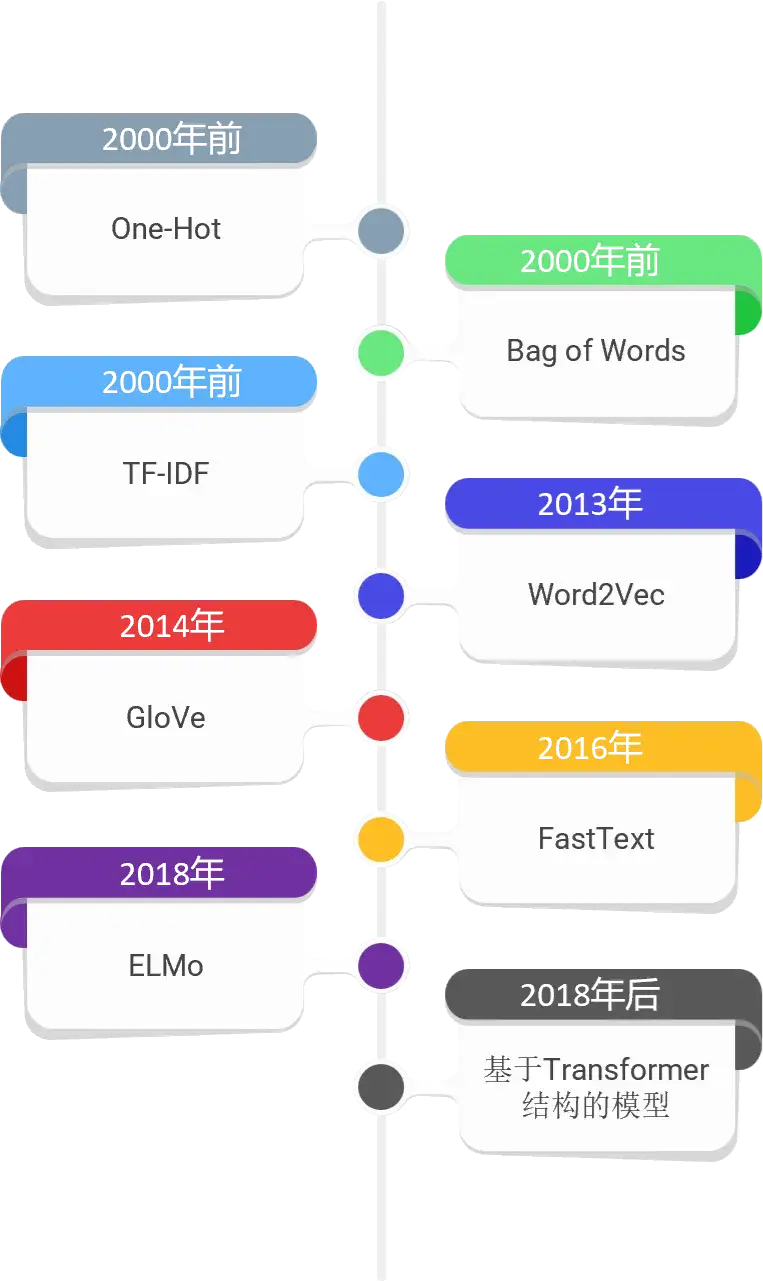
1. 早期的词表示方法
最早的词向量是通过统计方法得来的。在 NLP 的早期阶段,使用了 one-hot 编码和词袋(BoW)等简单技术。然而,这些方法未能捕捉语言的上下文和语义的复杂性。每个单词都被视为一个孤立的单元,不了解它与其他单词的关系或其在不同上下文中的用法。
1.1 one-hot
One-Hot 编码(独热编码)是 NLP 中处理离散型类别变量的核心方法,其本质是将每个类别映射为一个二进制向量。假设词汇表包含 N 个单词,每个单词会被表示为一个 N 维的二进制向量,其中仅对应单词索引的位置为 1,其余均为 0。例如,构建的词典信息如下:

基于字典组成 one-hot 模型:
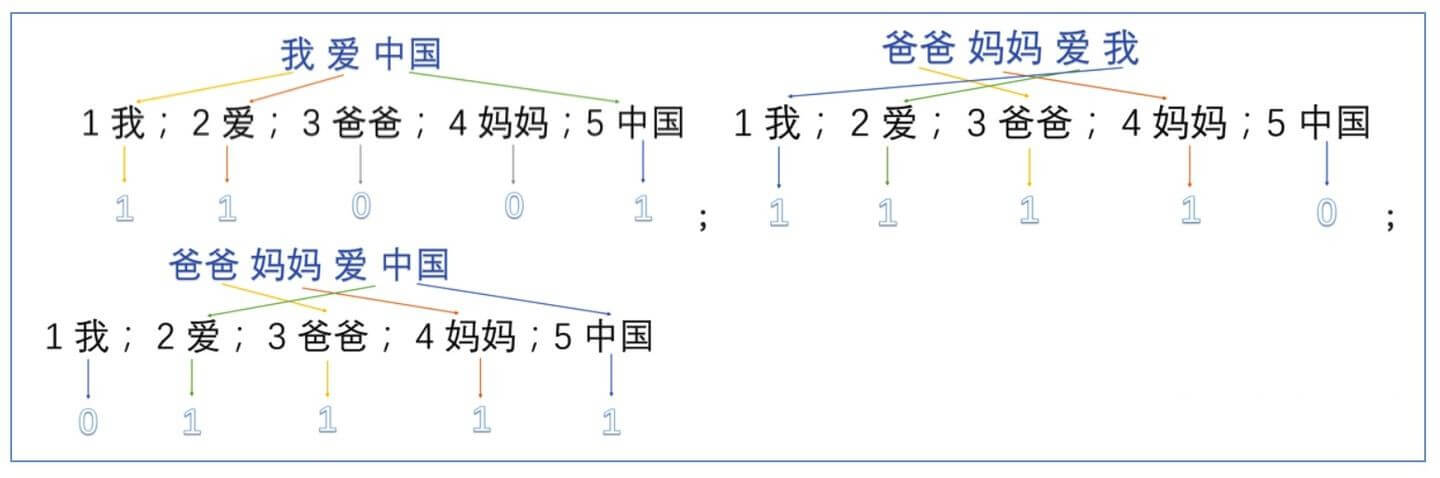
一方面词典的数目一般都是上万数量级的,造成对于单个词而言,向量表示过于稀疏,也会导致计算量骤增,另一方面由于仅仅存储 0、1 数据,没有办法保存对应的语序信息,也就无法通过 one-hot 编码挖掘词与词之间的语义关系。于是就有了后续一系列的改进措施。
从数学角度看,One-Hot 编码通过正交基向量构建特征空间,确保不同类别在向量空间中具有最大距离(欧氏距离为 √2),从而避免数值型编码(如序数编码)可能引入的虚假顺序关系。这种特性使其成为词嵌入(Word Embedding)前的标准预处理步骤。
1.2 BOW 词袋模型
词袋模型(Bag-of-Words model,BOW)BoW(Bag of Words)词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words 即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
例如三个句子如下:
句子1:小孩喜欢吃零食。
句子2:小孩喜欢玩游戏,不喜欢运动。
句子3 :大人不喜欢吃零食,喜欢运动。首先根据 语料 中出现的句子分词,然后构建 词袋(每一个出现的词都加进来)。计算机不认识字,只认识数字,那在计算机中怎么表示词袋模型呢?其实很简单,给每个词一个位置索引就可以了。小孩放在第一个位置,喜欢放在第二个位置,以此类推。
{“小孩”:1,“喜欢”:2,“吃”:3,“零食”:4,“玩”:5,“游戏”:6,“大人”:7,“不”:8,“运动”:9}其中 key 为词,value 为词的索引,预料中共有 9 个单词, 那么每个文本我们就可以使用一个 9 维的向量来表示。如果文本中含有的一个词出现了一次,就让那个词的位置置为 1,词出现几次就置为几,那么上述文本可以表示为:
句子1:[1,1,1,1,0,0,0,0,0]
句子2:[1,2,0,0,1,1,0,1,1]
句子3:[0,2,1,1,0,0,1,1,1]该向量与原来文本中单词出现的顺序没有关系,仅仅是词典中每个单词在文本中出现的频率。
与词袋模型非常类似的一个模型是词集模型(Set of Words, 简称 SoW),和词袋模型唯一的不同是它仅仅考虑词是否在文本中出现,而不考虑词频。也就是一个词在文本在文本中出现 1 次和多次特征处理是一样的。在大多数时候,我们使用词袋模型。
BoW 模型正是基于这样一个简单的概念:
- 忽略顺序: 就像袋子里的东西没有特定的顺序一样,BoW 模型不考虑单词在文档中的顺序或语法结构,只考虑词汇是否出现,以及它们出现的频率。
- 构建词汇表: 在应用 BoW 模型时,首先要构建一个词汇表,这个表包含了所有文档中出现的不重复词汇。
- 文档向量: 然后,每个文档都被转换成一个向量,这个向量的维度等于词汇表的大小。向量中的每一个元素代表对应在词汇表中的词汇在文档中出现的次数或者是出现与否的指标。
BoW 的缺点:
语境信息的缺失: 因为 BoW 模型忽略了单词的顺序和语境,所以它无法捕捉到词语之间的语义关系。
高维稀疏: BoW 向量通常很稀疏,因为词汇表可能非常庞大,而每个文档中的单词却相对较少,这导致了大量的零值出现在向量中。
频率不代表重要性: 仅仅依靠频率,BoW 模型不能区分出哪些词对于文档的意义更为重要。尽管可以用 TF-IDF 等方法来改善,但仍然有局限性。
词袋模型最重要的是构造词库,需要维护一个很大的词库。
词袋模型严重 缺乏相似词之间的表达。例如 “我喜欢北京”“我不喜欢北京”其实这两个文本差异很小,但是是严重不相似的。但词袋模型会判为高度相似。“我喜欢北京”与“我爱北京”其实表达的意思是非常非常的接近的,但词袋模型不能表示“喜欢”和“爱”之间严重的相似关系。(当然词袋模型也能给这两句话很高的相似度,但是其实这两者的程度是不一样的,只是这个模型无法表示出这种程度)
尽管有这些局限,BoW 模型因其实现简单和计算高效,在很多基本的文本分析任务中仍然非常有用。
1.3 TF-IDF
TF-IDF 是一种基于统计的词表示方法,通过计算词频(TF)和逆文档频率(IDF)来衡量词的重要性。
TF 表示词在文档中出现的频率,反映词在该文档中的重要程度。IDF 衡量词在整个语料库中的 稀有 程度,稀有词的 IDF 值更高。这种表示方法能有效降低常见高频词的权重,突出重要且区分度高的词。但是仍然忽略词的语义关系,只关注统计信息。对长文本效果较好,短文本表现有限。
1.4 小结
One-hot、BoW、TF-IDF 都是基于词频统计的表示方法,向量很稀 疏,且:
不能理解词之间的“意思相近”或“含义相关”
词向量互相之间“距离”没有实际意义(“猫”和“狗”距离与“猫”和“电脑”距离一样,没反映相似度)
2. 传统词向量技术
2.1 Word2Vec
2013 年 Google 推出的 Word2Vec 标志着 NLP 领域的重大飞跃。 Word2Vec 是一种使用神经网络从大型文本语料库中学习单词关联的算法。因此,它生成单词的密集向量表示或嵌入,捕获大量语义和句法信息。单词的上下文含义可以通过高维空间中向量的接近程度来确定。
Word2Vec 包含两种主要模型架构:连续词袋模型(Continuous Bag of Words, CBOW)和跳字模型(Skip-Gram)。Skip-Gram 的目标是根据目标词预测其周围的上下文词汇,与之相反,CBOW 模型的目标是根据周围的上下文词汇来预测目标词。
Word2Vec 的优点是能够揭示词与词之间的相似性,比如通过计算向量之间的距离来找到语义上相近的词。典型的实例就是上面提到的【国王-男人+女人 ≈ 女王】

The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
由于 Word2Vec 训练时只考虑了上下文的内容,并且在使用时我们的输入都是一个个单独的词语,所以我们 不能捕捉到文本中“语序”产生的相关意义与语言结构。
早期的方法(如 one-hot 编码)导致高维稀疏向量,无法捕捉语义关系。Word2Vec 通过稠密向量(通常 50-300 维)高效表示词语,解决了维度灾难。它通过向量空间中的几何关系(如余弦相似度)直接计算词语相似性(例如,“国王”和“王后”的向量接近)。
2.2 GloVe:用于单词表示的全局向量
斯坦福大学的研究人员在 2014 年推出了 GloVe,进一步推进了词嵌入的概念。GloVe 通过在整个语料库中更全面地检查统计信息来创建词向量,从而在 Word2Vec 的基础上进行了改进。通过考虑本地上下文窗口和全局语料库统计数据,它可以实现更细致的语义理解。
与 Word2Vec 同样,在构建词共现矩阵时,GloVe 不考虑 “词序问题“。它的关注点在于词语整体的使用模式,词语在语句中的排列顺序并不能被完美捕捉到。
3. 现代 Embedding
进入深度学习时代,嵌入模型开始能“看懂”上下文。
| 特性 | 传统 Embedding(Word2Vec / GloVe) | 现代 Embedding(BERT / GPT 等) |
|---|---|---|
| 向量是否固定 | 是,每个词一个向量 | 否,向量由上下文动态生成 |
| 是否考虑上下文 | ❌ 不考虑(无语境差异) | ✅ 考虑(上下文决定语义) |
| 多义词支持 | ❌ “苹果”永远一个向量 | ✅ “苹果”(水果 vs 公司)向量不同 |
| 模型结构 | 简单浅层网络 | 深度 Transformer |
| 表达能力 | 静态语义相似度 | 动态语义理解、句法语义结构 |
4. 小结
这部分只是简单了解一下词向量发展过程,但是其实并不详细,毕竟自己对大模型了解还不是特别的深入,后续再继续补充。
参考资料:
Transformer Explainer: LLM Transformer Model Visually Explained
A Survey on Contextual Embeddings
Efficient Estimation of Word Representations in Vector Space 和 Distributed Representations of Words and Phrases and their Compositionality(这两篇论文提出了两种学习单词表示的方法:连续词袋模型 和 连续跳字模型)
WordEmbedding 发展史(语言模型演变史) - 知乎
RAG 系列 | 嵌入模型详解:一文带你读懂向量化的过去、现在与未来
「国王-男人+女人 = 皇后」背后的词类比原理究竟为何?| ACL 2019 | 雷峰网
19_Word2Vec 详解:训练你的词嵌入-腾讯云开发者社区-腾讯云
图解词嵌入、语言模型、Word2Vec_embedding 和 context-CSDN 博客
word2vec 中的数学原理详解 - peghoty - 博客园
12 深入理解 Word2Vec:解开词向量生成的奥秘 - 极客时间文档
The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.