
LV040-上下文工程
一、从 Prompt 到 Context
在智能系统的早期,Prompt Engineering 被认为是激发大语言模型(LLM, Large Language Model)能力的关键手段。但实际开发 RAG(Retrieval-Augmented Generation)、Agent 或工具调用系统时,开发者很快发现 Prompt 只能“控制模型思考”,却无法“控制模型知道什么”。 模型本质上是一台 被隔离的推理引擎:
- 它对外部世界一无所知;
- 它的记忆仅限于临时上下文窗口;
- 它无法访问实时数据或历史经验。
这种限制主要源于 Context Window(上下文窗口)。LLM 的上下文窗口是其工作记忆,容量有限。输入的每个 token(包括指令、上下文、对话历史)都在竞争这一狭窄空间。当空间被占满,早期信息会被遗忘,新输入覆盖旧状态。
Prompt Engineering 解决模型“如何思考”;Context Engineering 解决模型“在什么世界中思考”。
二、上下文工程
1. 什么是上下文工程
Context Engineering,上下文工程。定义是在有限的上下文窗口中,选择、组织并注入与用户输入或任务高度相关的信息,从而让大语言模型(LLM)能够在合理的边界内做出最佳推理和执行。
2. 上下文工程包含哪些?
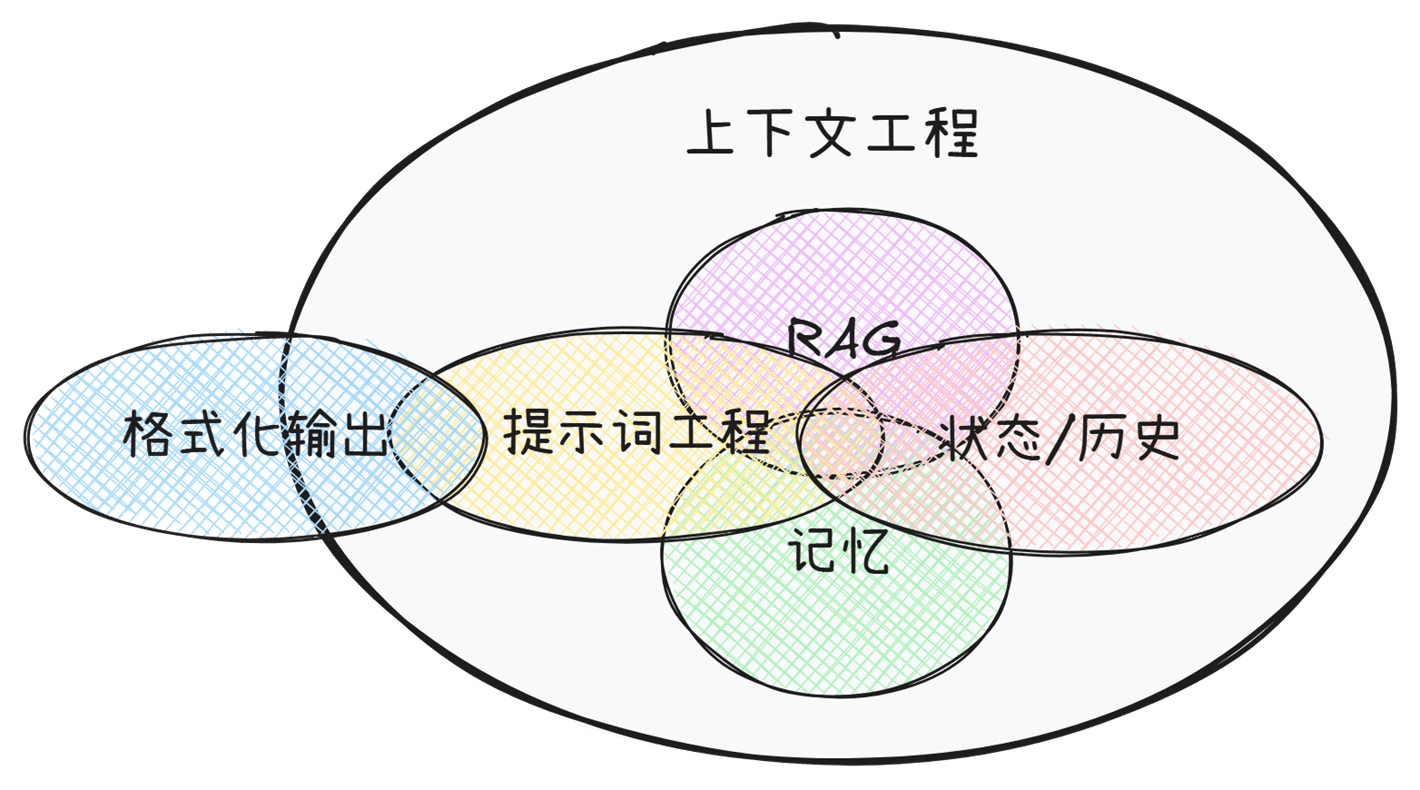
2.1 提示词工程(Prompt Engineering)
这是上下文工程最基础、最核心的部分。它专注于设计和优化直接输入给模型的指令文本(即“提示词”)。提示词工程包括了一系列相关提示词的技术:
- 明确指令(Clear Instruction): 清晰地告诉模型要做什么,避免模糊不清的词语。
- 角色扮演(Role-playing): 让模型扮演一个特定角色(如“你是一位资深律师…”)。
- 提供示例(Few-shot Learning): 给出几个输入和输出的范例,让模型学习并模仿。
- 思维链(Chain-of-Thought, CoT): 引导模型一步一步地思考,将复杂问题分解,从而得出更可靠的结论。
- 设定输出格式(Format Specification): 要求模型以特定格式输出,如 JSON、Markdown 表格、HTML 等。
2.2 检索增强生成(Retrieval-Augmented Generation, RAG)
当模型的内部知识不足(比如,对于最新的信息、私有领域的知识库或非常专业的内容)时,RAG 就显得尤为重要,它极大地减少了模型“胡说八道”(幻觉)的概率,提高了答案的准确性和时效性,并且可以引用信息来源。
- 检索(Retrieve): 当用户提出问题时,系统首先从一个外部的知识库(如公司的内部文档、数据库、网站等)中检索最相关的信息片段。
- 增强(Augment): 将检索到的这些信息片段,连同用户的原始问题,一起整合到提示词中。
- 生成(Generate): 将这个“增强后”的上下文发送给 LLM,让它基于这些最新、最相关的“外部知识”来生成答案。
2.3 上下文构建与管理(Context Construction & Management)
这部分关注的是如何动态地、智能地构建和维护整个上下文窗口(Context Window)。LLM 的输入长度是有限的(即上下文窗口),如何有效利用这个有限的空间至关重要。
- 上下文压缩(Context Compression): 在保持关键信息的同时,删减不重要或冗余的内容,以节省空间。
- 对话历史管理(Conversation History Management): 在多轮对话中,如何有效地总结和管理之前的对话历史,确保对话的连贯性,同时避免上下文窗口被陈旧信息占满。
- 动态上下文注入(Dynamic Context Injection): 根据对话的进展或用户的行为,实时地从外部源(如用户画像数据库、实时传感器数据等)拉取信息并注入到上下文中。
2.4 记忆机制(Memory Systems)
- 短期记忆:维护当前会话状态、任务链信息。
- 长期记忆:保存跨会话历史、用户偏好,通过检索机制注入上下文中。
3. 意义
我们不再只优化一句 prompt,而是设计一个系统,确保模型能够:
- 获取正确的信息(retrieval)
- 保持连续的记忆(memory)
- 与外部世界交互(tools)
- 动态调整策略(agents)
二、有什么好处?
通过上下文工程带来如下好处:
- 提升模型性能和准确性: 这是最直接的好处。好的上下文可以显著减少模型的错误和幻觉,让输出结果更贴近事实和用户需求。
- 降低成本和复杂性: 相比于重新训练(Re-training)或微调(Fine-tuning)一个庞大的语言模型,上下文工程的成本要低得多,实施起来也更快速、更灵活。它允许我们在不改变模型底层的情况下,适配各种不同的应用场景。
- 增强可控性和可解释性: 通过 RAG 等技术,我们可以知道模型是依据哪些信息来生成答案的,这增强了系统的透明度和可信度。同时,通过精心设计的提示词,我们可以更好地控制模型的输出风格、语气和内容。
- 实现个性化和动态适应: 上下文工程使得 AI 应用能够整合实时的、个性化的用户信息,提供千人千面的服务。例如,一个 AI 客服可以根据用户的历史购买记录(通过 RAG 检索得到)提供更有针对性的建议。
如果说大型语言模型是强大的“引擎”,那么上下文工程就是设计精良的“驾驶舱”和“导航系统”。它决定了我们如何驾驭这股强大的力量,将其引导到正确的方向,去完成具体、有价值的任务。
参考资料:
Practical-Guide-to-Context-Engineering/README.md