
LV005-基础知识
一、什么是音频
1. 简介
声音:是有物体震动产生的波。音频,指人耳可以听到的声音频率在 20Hz~20kHz 之间的声波,称为音频。
我们听到的一系列声音,都是 音频模拟信号,比如公交车上的语音播报,手机扬声器播放的音乐等;模拟信号的采集、传输和保存有着较高的难度,如早期的录音磁带、老旧唱片,其占用空间较大,保存起来麻烦,而且在用同种方法进行拷贝时,失真效果极为严重;而将模拟信号转换成数字信号后,音频的传输、保存和拷贝都变得极为方便。
2. 声音的三要素
音强(volume) :响度,由振幅决定,人主观上感觉的声音大小(单位:分贝 DB)。通俗的讲就是声音的高低,一般男生的声音振幅(响度) 大于女生。
音调(pitch) : 由频率决定,高音、中音、低音。人类听觉的频率(音调) 范围为 20Hz - 20KHz。
音色 (Timbre) : 指声音频率组成成分,由发声物体材料和结构决定。波形决定了其所代表声音的音色。音色不同是因为它们的介质所产生的波形不同。
也有说声音的三要素是频率、振幅、波形。
3. 怎么采集?
我们知道声音是由物体振动产生的声波,是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。声波是一种在时间和振幅上连续的 模拟量,麦克风就是一种采集声波并将其转换成模拟电压信号输出的装置,有了声波的模拟电压信号,下一步需要将模拟信号数字化,即将模拟信号通过模数转换器(A/D)后转换成数字信号。
二、将音频数字化
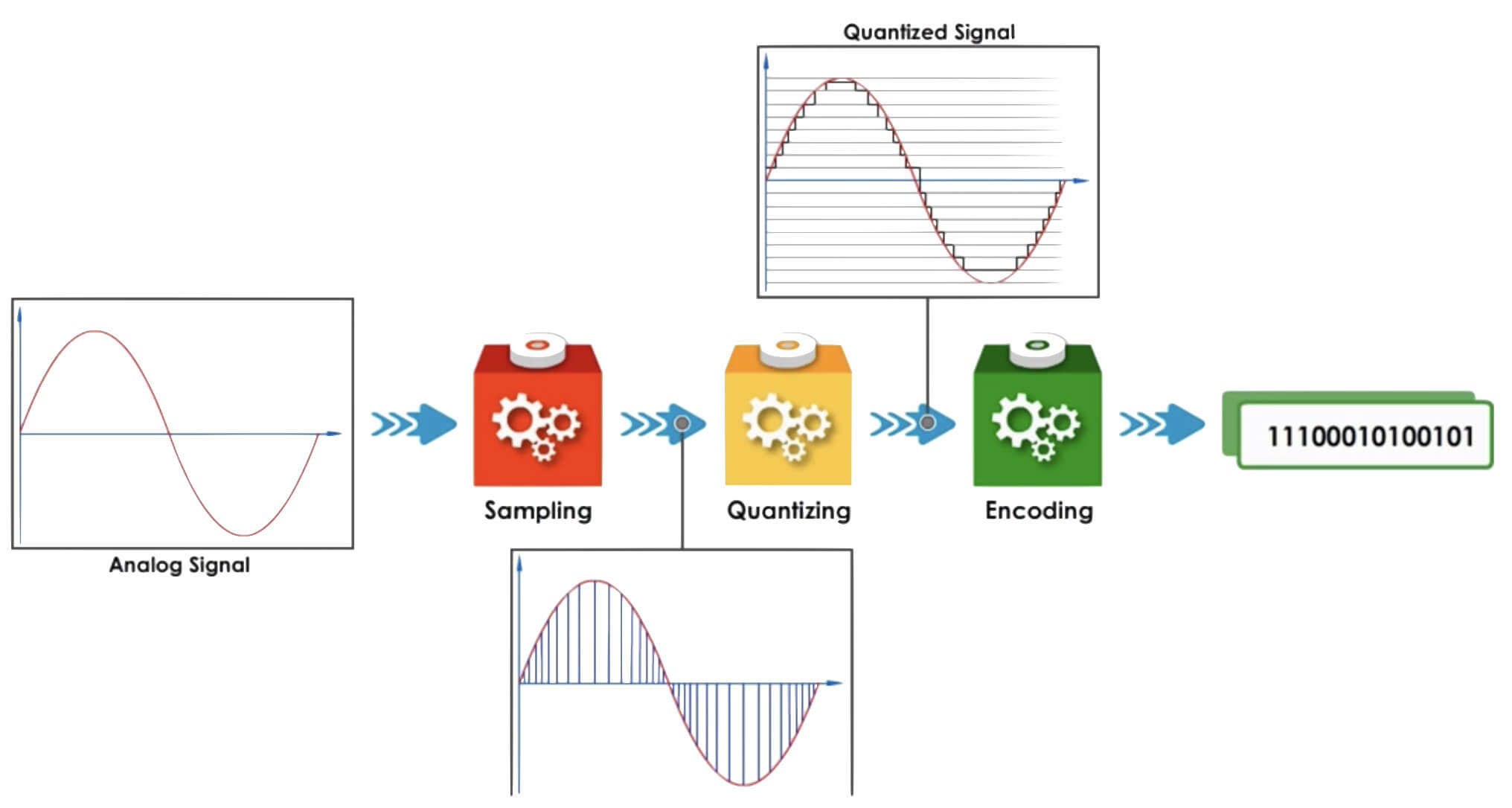
采集音频就是把音频模拟信号转换成数字信号的过程,是通过 A/D 设备(模/数转换器,简称 ADC,analog to digital convert)对模拟信号以一定频率进行 采样,量化,编码。
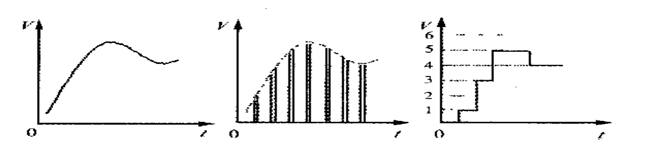
1. 采样
模/数转换器(A/D 转换器)对声波进行采样,每一次采样都记录下了原始模拟声波在某一时刻的状态,称之为 样本。
采样点数 (number of samples)则是指在一段时间内对模拟信号进行采样所得到的 样本数量,常用来衡量 数字音频 的时长和数据量。 在音频处理中,采样点数表示了一段音频中离散的采样点的数量。 每个采样点代表了模拟信号在每个采样时刻的振幅值。
将一串的样本连接起来,就可以描述一段声波了,把 每 1 秒钟所采样的次数 称为 采样频率(Sample Rate)或采率,单位为 HZ(赫兹)。采样率决定声音频率的范围(相当于音调),可以用数字波形表示。以 波形表示的频率范围 通常被称为 带宽。根据奈奎斯特定理,为了准确地重建原始音频信号而不产生混叠失真,采样率至少需要是最高音频频率的两倍。对于人类听觉范围(大约 20Hz 到 20kHz),常用的 CD 质量音频采样率为 44.1kHz。
从效果来看,采样频率越高,所得的离散信号就越接近原始的模拟信号,但也会增加数据量。在当今的主流采集卡上,采样频率一般共分为 8KHz、16KHz、22.05KHz、44.1KHz(44100Hz)、48KHz 多个等级,22.05 KHz 只能达到 FM 广播的声音品质,44.1KHz 则是理论上的 CD 音质界限,48KHz 则更加精确一些。对于高于 48KHz 的采样频率人耳已无法辨别出来了,所以在电脑上没有多少使用价值。
Tips:
(1)给定一个采样率,我们能重建的周期信号的频率至少是该采样率的一半(这个频率叫做 奈奎斯特频率)。在正常的声音中,最高的音频频率也只不过 8kHz,这意味着 16kHz 的采样频率便便可以满足一般要求。但是8kHz 仅仅表示基音的音高,仍有大量的泛音未包括在内。所谓“不失真”应该是“人听不到失真”。人类的听力范围是 20Hz~20kHz,所以采样频率至少是 20k×2=40kHz 才可保证不产生低频失真。CD 音质的 44.1kHz 正是这样制定出来的。
(2)1Hz 表示每秒钟对原始信号采样一次,1KHz 表示每秒钟采样 1000 次。1MHz 表示每秒钟采样 1 百万次。
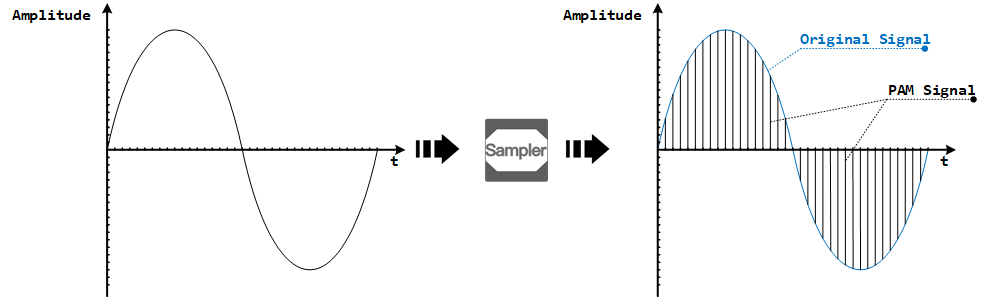
- 蓝色曲线:表示原始的模拟信号。
- 黑色垂直线段:表示当前时间点对原始信号的一次采样。采样 是一系列基于 振幅(amplitude) 的相同时间间隔的样本,这也是为什么采样过程被称为 PAM 的原因。
- PAM:(Pulse Amplitude Modulation)是一系列离散样本的结果。
在上图中,假设这个声波的一个周期是 1 秒,那么在这 1 秒内,采样了 36 次,那么采样率就是 36Hz,产生了 36 个采样点。一般实际情况中多数会使用 16KHz 的采样率,那么 1 秒钟的音频数据所能得到的采样点数就是 16000 个采样点
2. 量化
量化,就是把经过抽样得到的瞬时值将其幅度离散,即用一组规定的 实数(这里可以理解为电平),把瞬时抽样值用最接近的电平值来表示,这些电平值将被转换为二进制数用于模拟信号的存储和传输。一个 模拟信号 经过抽样量化后,得到已量化的是 脉冲幅度调制 信号,它仅为有限个数值。
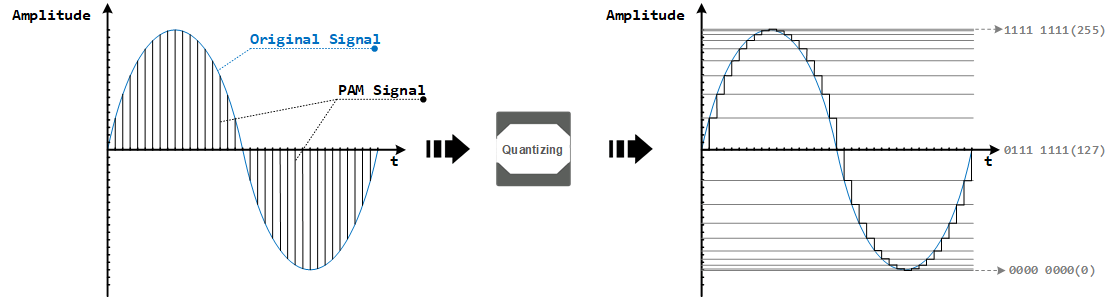
把时间和幅度都用离散的数字表示的信号就称为 数字信号。
量化的过程 就是将一个 平顶样本 四舍五入到一个可用最近 level 描述的过程。如图中 黑色加粗梯形折线。量化过程中,我们给每一个采样点赋值,如图中的 0-255,这里我们规定信号最低点为 0,可以防止出现负数,那么第 0 个采样点就是 127,第 9 个采样点就是 255,第 27 个采样点就是 0。
3. 编码
编码,就是用一组二进制码组来表示每一个有固定电平的量化值,就是将电平值转换为二进制数,例如 255 用 8 位表示的话就是 1111 1111。然而,实际上量化是在编码过程中同时完成的,故编码过程也称为 模数变换,可记作 A/D。

这里有一个采样位数的概念,采样位数 也叫采样精度或者量化深度。量化深度表示每个采样点用多少比特表示,音频的量化深度一般为 8、16、32 位等。量化深度为 8bit 时,每个采样点可以表示 256 个不同的量化值,而量化深度为 16bit 时,每个采样点可以表示 65536 个不同的量化值。量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。
所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或者压缩存储,等等。
4. 小结
音频完整的处理过程如下图:
三、一些基本概念
1. 音频帧
音频跟视频不太一样,视频的每一帧就是一副图像,但是因为音频是流式的,本身是没有一帧的概念的。但是人们可以规定一帧的概念,比如 amr 帧比较简单,它规定每 20ms 的音频是一帧。也可以定义为软件上每次处理音频的数据量称为一帧音频。
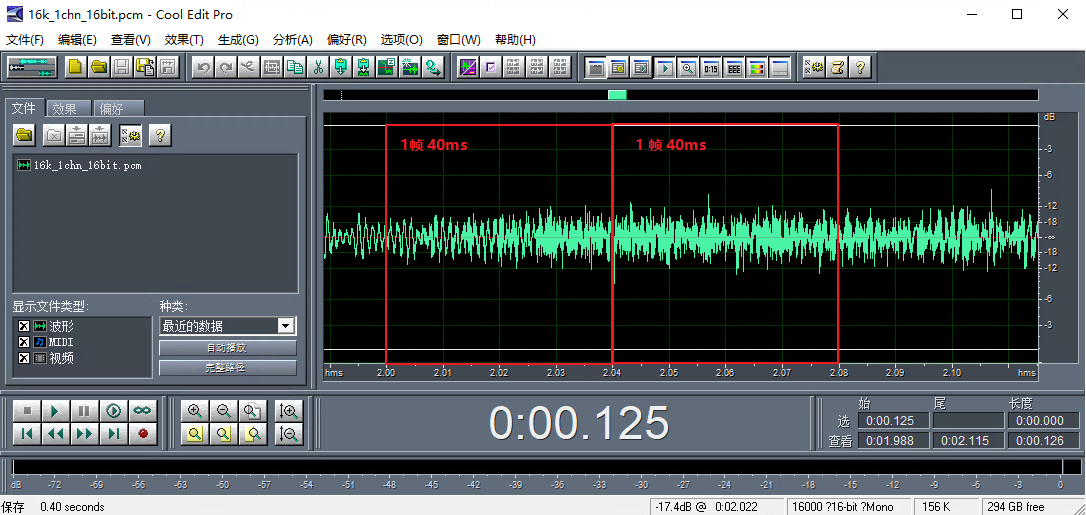
所以在音频中,帧 表示音频信号的一个固定时间长度的片段,由一系列连续的采样点组成,而且音频帧之间数据是连续的。
2. 声道数
声道数即声音的通道数目, 常见的有 单声道 和 双声道 或者立体声道。多声道数据常按下图这种交错排列的方式进行存储:

单声道的声音只能使用一个扬声器发声,或者也可以处理成两个扬声器输出同一个声道的声音,当通过两个扬声器回放单声道信息的时候,我们可以明显感觉到声音是从两个音箱中间传递到我们耳朵里的,无法判断声源的具体位置。
双声道就是有两个声音通道,其原理是人们听到声音时可以根据左耳和右耳对声音相位差来判断声源的具体位置。声音在录制过程中被分配到两个独立的声道,从而达到了很好的声音定位效果。
记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道(立体声)。立体声(双声道)存储大小是单声道文件的两倍。当生成双声道数据的时候就需要两个 mic 同时进行采集。
按照上面的例子,我们每 40ms 为一帧,采样率为 16KHz,那么双声道的话,每一个音频帧就会有 640x2 = 1280 个采样点。
这里可以区分一下采样点数和采样个数,
- 如果是 单声道 , 就有 1 个音频采样 , 每个音频帧有 640 个采样点。
- 如果是 立体声 ( 双声道 ) , 就有 2 个音频采样 , 每个音频帧有 1280 个采样点。
3. 采样位数
前面我们已经了解过了,采样位数其实就是用多少个二进制来表示采样点的振幅,这个也叫量化深度,采样深度。常见的就是 8bit、16bit 等。量化深度为 8bit 时,每个采样点可以表示 256 个不同的量化值,而量化深度为 16bit 时,每个采样点可以表示 65536 个不同的量化值。
4. 比特率/码率
指音频每秒钟播放的数据量,单位为 bit,例如对于原始的数据流,采样率为 16000Hz,采样位数为 16bit,声道数为 2,那么码率为:16000 x 16 x 2 = 512000 bps,即 512kbps。
计算公式为:
5. 音频帧的长度
一帧音频数据的大小称为帧长,帧的大小通常由两个因素决定:时间长度(以毫秒为单位)和 采样率(以 Hz 为单位)。其实这里可以有两种方式来描述帧长:
- (1)音频帧长度指的是 每个音频帧的 " 播放持续时间 " :音频帧持续时间 ( 单位 : 秒 ) = 采样点数 ( 单位 : 个 ) / 采样频率 ( 单位 : 赫兹 Hz ) 。
前面我们规定了一帧是 40ms,可以得到一帧的采样点数,那么现在我们规定一帧为 640 个采样点,16k 的采样率,那么一帧的播放时长就是 640 / 16000 = 0.04s,就是一帧 40ms,后面学习编解码的时候,不同的编码格式对音频帧定义的时候有一些就是会规定采样点数和采样率。
比如 AAC 编码格式的音频,就要求每帧的采样数为 1024,这个时候用 16k 采样率的话,一帧的音频时长就是 1024 / 16000 = 0.064 = 64 ms,1 秒就是大概 15.6 帧。
- (2)音频帧长度 也可以指 " 压缩后每个 音频帧 的 数据长度 " :音频帧的数据长度=采样点数 x (量化位数/8) x 声道数
例如我们的 16k 采样率,40ms 一帧的话(1秒采集25帧),一帧是 640 个采样点,若量化位数是 16bit,那么一帧就是 1280 个字节,若是双声道,那么一帧就是 2560 个字节。
其实严格来说,音频帧并不是以“每秒多少帧”来衡量的(像视频那样),而是通过采样率(Sample Rate)和每帧的采样数(Samples Per Frame)来计算它的持续时间。
6. 音频信号时频域
- 时域波形
- 频域频谱图
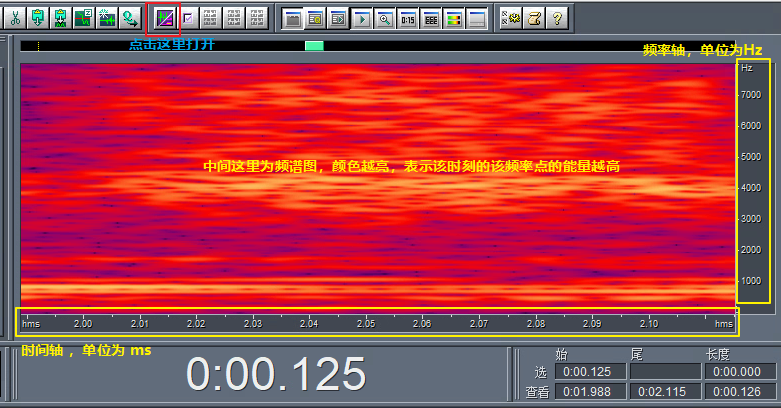
中间的部分也可以叫声纹。不同的声音的声纹是不一样的,例如:
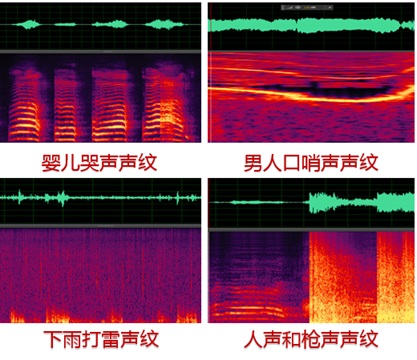
参考资料: