
LV005-概述
一、为什么要编码
我们都知道,要想把音视频数据实时分享到世界的各个角落,有一个传输工具必不可少:网络。而要用好这个传输工具,有一个必须关注的点:网络带宽。
带宽 指的是网络链路 1 秒钟内能传输的最大数据量,其单位一般使用 bps(bit per second),对应到推流(上传)/拉流(下载),可以相应分为上行带宽和下行带宽。如果把网络比喻为高速路,那么带宽就相当于这条路的宽度,音视频数据相当于路上来往的车辆。公路越宽,则允许并行通过的车辆越多,其运输能力就越强,如果道路太窄、需要并行通过的车辆又太多,可能会出现阻塞、甚至是车祸。对应的,网络带宽越大,单位时间能传输的数据越多,如果带宽不足,势必导致传输异常,产生卡顿、甚至数据丢失等影响用户体验的问题。
基于对带宽的了解,我们进一步看看纯音频场景对带宽的需求情况。我们已经知道,音频模拟信号经数字化处理会得到标准的数字 ⾳ 频数据裸流,其格式为 PCM。不妨先来计算一下,如果直接传输 PCM 数据需要多少带宽。
音频数据传输所需的带宽,可以通过音频码率来度量。对于采样率 44.1K Hz,位深 16 bit 的双声道音频 PCM 数据,它的码率为:
采样率/Hz * 位深/bit * 声道数 * 时长(1s) = 44100 * 16 * 2 * 1 = 1411200 bps = 1.4112 Mbps(bps = bit per second)
也就是说,要求推流用户的上行带宽、拉流用户的下行带宽至少为:1.4112 Mbps。这是单条音频流的情况,如果将场景扩展到语聊房或在线会议,带宽要求还需要依据上麦人数翻 N 倍。而在一些特殊场景,比如曾风靡一时的 ClubHouse 或 势头正旺的 MetaWorld,它们甚至号称“不限制上麦人数”,对于带宽的要求必然会更高。根据统计数据显示,2021 年我国宽带网络的上行速率中值约为 35Mbps,考虑到实际场景中除了音频之外,还有其他数据需要传输(比如视频数据,所需带宽是音频的数十倍),综合考量下来,带宽也算是“寸土寸金”了,PCM 数据的码率着实让人“高攀不起”。
二、音频编码压缩的可行性
我们已经知道,音频编码过程是压缩、减少数据量的过程,但“减少”并不代表可以随意丢弃,而 要在减少“数据量”时,同时尽可能避免“信息量”的丢失,也即保真。如果被压缩的音频数据,其所有信息可以被完整地解压、还原,我们称相应的处理为无损压缩;否则,相应的处理即为有损压缩,有损压缩能够带来更好的压缩效益,是 RTC 场景下普遍使用的方案。
值得一提的是,有损和无损也是相对而言的,目前任何数字编码方案都无法做到完全无损,就像用数值表达圆周率 π = 3.1415926……,只能无限提高精度、无限接近,但永远无法相等。
Tips:PCM 就属于“无损”的音频编码,我们已了解其原理是对模拟音频信号在时间轴、幅度轴上进行采样、量化处理,以使重构的语音波形尽可能与原始语音信号的一致,其保真度好,但编码码率很高,不适用于 RTC 场景。
那么,既然是“有损压缩”,实现可观的压缩率,又要最大限度避免“信息量”丢失,这不是相互矛盾了吗?
其实,“信息量”再加上一个定语会更贴切,那就是避免“有用、重要的“的”信息量丢失。压缩过程中丢弃的数据相对于整体应该是“不必要”或“不重要” – 也即“冗余”的。在 RTC 场景中,人是音频信号的消费者,我们可以充分利用人耳听觉的生理、心理特性来寻找这些“不必要”、“不重要”的冗余成分,总结下来主要包括两方面:
- (1)人耳听觉范围之外的音频信号
人耳的听力范围仅限于频率 20Hz ~ 20kHz,低于或者高于该频率范围的声音无法被人耳感知,被称为次声波(<20Hz)和超声波(>20KHz)。这部分“无法被人耳感知”的声音,就属于音频信号中“不必要” 的“冗余”部分。同时,因为不同类型信号的频率特征不同,比如语音的频率集中在 300 ~ 3400Hz,如果只关注语音信号,300~3400Hz 频段之外的信号也可以视为“冗余”,可以在编码压缩过程中“丢弃”。
- (2)被掩蔽掉的音频信号
除了对特定频率的声音不敏感外,人耳还会因为“掩蔽效应”而忽略某些“弱音信号”。关于“掩蔽效应”,我们以响度(声强级)作为参考,做如下理解:
人耳对于不同频率的声音,有相应的最小响度可闻阈,如果某个频率的声音响度小于该频率的最小可闻阈,该声音将无法被人耳听到。并且,某一频率声音的最小可闻阈不是固定的,当存在能量较大的“强音信号”时,该“强音信号”附近频率的“弱音信号”的最小可闻阈值会提高,这就是掩蔽效应中的“频域掩蔽”,如下图【频域掩蔽】所示。
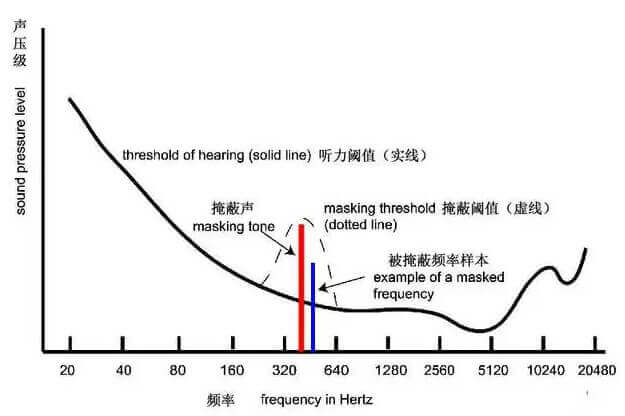
除了频域掩蔽外,当强音信号和弱音信号同时存在时,在不同时机,还会有“时域掩蔽”。如下图【时域掩蔽】所示,在强音信号出现前的短时间内(约 20ms),已经存在的弱音信号会被掩蔽;当二者同时存在,弱音信号会被掩蔽;当强音信号消失后,还需要等上一段时间(约 150ms),弱音信号才能重新被人耳听到。以上三种类型的时域掩蔽分别称为 超前、同时和滞后掩蔽。
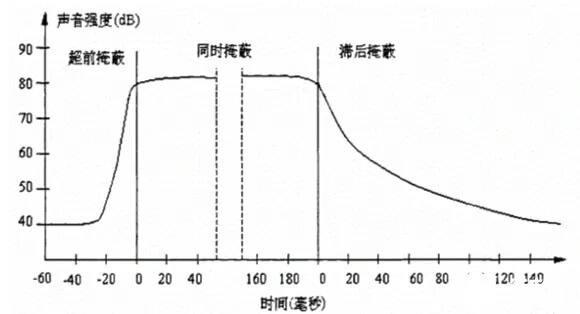
在频域掩蔽和时域掩蔽中,那些“被掩蔽的信号”无法被人耳感知,所以可以视为冗余信号,可以在编码压缩过程中“丢弃”。
除了利用人耳听觉的生理、心理特性定义的“冗余”外,基于信息论原理,音频信号在时域和频域上的特征具有统计相关性,也即存在数据冗余,这些冗余也可以通过信息编码的方式进行压缩处理。
综上,我们从声音信号中找到了“冗余”成分,它们是支撑音频编码压缩的“可行性”基础。
三、常见音频编码格式
1. 常见编码类型汇总
| codec名称 | 采样率 | 声道 | 码率kbps |
| G711 | 8 kHz | 单 | 64 |
| G722.1 | 16 kHz | 单 | 16、24、32 |
| 32 kHz | 单 | 16、24、32、48 | |
| G723.1 | 8 kHz | 单 | 5.3、6.3 |
| G726 | 8 kHz | 单 | 40、32、24、16 |
| G729 | 8 kHz | 单 | 8 |
| MPEG 1 LAYER 2 | 32 kHz、44.1 kHz、48 kHz | 双/单 | 32、48、 ... 、384 |
| MPEG 1 LAYER 3 | 32 kHz、44.1 kHz、48 kHz | 双/单 | 32、40、 ... 、320 |
| MPEG 2 LAYER 2 | 16K、22.05K、24K、32K、44.1K、48K | 双/单 | 8、16、 ... 、384 |
| AMR NB | 8K | 单 | 12.2、10.2、 ... 、4.75 |
| AMR WB | 16K | 单 | 6.60、... 、23.05、23.85 |
| AAC | 8K、16K、32K、44.1K | 双/单 | 8、16、32、64 |
2. 部分格式简介
这里有一些可能上面的表里没有。
2.1 WAV
这个前面已经了解过了,它是由微软开发。符合 RIFF(ResourceInterchange File Format) 规范。所有的 WAV 都有一个文件头,这个文件头包含了音频流的编码参数。WAV 对音频流的编码没有硬性规定,除了 PCM 之外,还有几乎所有支持 ACM 规范的编码都可以为 WAV 的音频流进行编码。
但是其实吧,它是一种文件格式,严格来说并不算编码格式,是一种无损的格式,对 PCM 数据没有做任何处理,只是加了个 44 字节头。
2.2 MP3(MPEG Audio Layer III)
MP3 是 MPEG(MPEG: Moving Picture Experts Group) Audio Layer-3 的简称,是一种高效的计算机音频编码方案,能以较大的压缩比将音频文件转换成较小的扩展名为.mp3 的文件,基本保持源文件的音质,MP3 是 ISO/MPEG 标准的一部分,ISO/MPEG 标准描述了使用高性能感知编码方案的音频压缩,此标准一直在不断更新以满足“质高量小”的追求,现已形成 MPEG Layer1、Layer2、Layer3 三种音频编解码方案,分别对应 MP1、MP2、MP3 这三种声音文件。
它是在 1991 年由位于德国埃尔朗根的研究组织 Fraunhofer-Gesellschaft 的一组工程师发明和标准化的。mp3 标准参见 ISO/IEC 11172-3, ISO/IEC 13818-3。
MP3 音质还原较好,压缩比比较高:10:1~12:1。文件体积较小,有利网络传输,但是多次编辑后,音质会急剧下降。
文件封装格式:
- .mp3:mp3 并不适合作为素材格式保存。
2.3 G711
G.711 是国际电信联盟 ITU-T 定制出来的一套语音压缩标准,压缩率为 2:1, 即把 14 位(u-law)或 13 位(a-law)采样的 PCM 数据压缩成 8 位。G.711 是主流的波形声音编解码器。采样率为 8k, 压缩后的位宽为 8bit,所以比特率为 64kbps。
优点是语音质量好,CPU 消耗小,协议免费。缺点就是压缩效率低。
G.711 标准下有两种压缩算法:u-law 和 a-law
- a-law:主要在欧洲和国际电话网络中使用。a-law 的压缩比 u-law 小,但线性度较好,量化误差较小。
- u-law:又称 often u-law, ulaw, mu-law。主要在北美和日本使用。u-law 提供较高的压缩比,但线性度较差,量化误差较大。
2.4 G722
G.722 是国际电信联盟(ITU-T)制定的重要语音编解码标准,归属于 G 系列建议书体系(ITU-T G.722)。广泛应用于 VoIP、视频会议和多媒体通信系统。该标准支持 64kbps、48kbps 和 32kbps 三种比特率,采用子带编码与自适应差分脉冲编码调制(ADPCM)技术,实现宽带语音传输,提供比传统电话更清晰的音质。
ITU-T Rec. G.722 (11/88) 7 kHz audio-coding within 64 kbit/s
2.5 G726
G.726 是 ITU-T 定义的音频编码算法。1990 年 CCITT(ITU 前身)在 G.721 和 G.723 标准的基础上提出。G.726 可将 64kbps 的 PCM 信号转换为 40kbps、32kbps、24kbps、16kbps 的 ADPCM 信号。
最为常用的方式是 32 kbit/s,但由于其只是 G.711 速率的一半,所以就将网络的可利用空间增加了一倍。G.726 具 体规定了一个 64 kbpsA-law 或 μ-law PCM 信号是如何被转化为 40, 32, 24 或 16 kbps 的 ADPCM 通道的。在这些通道中,24 和 16 kbps 的通道被用于数字电路倍增设备(DCME)中的语音传输,而 40 kbps 通道则被用于 DCME 中的数据解调信号(尤其是 4800 kbps 或更高的调制解调器)。
实际上,G.726 encoder 输入一般都是 G.711 encoder 的输出:64kbit/s 的 A-law 或 µ-law;G.726 算法本质就是一个 ADPCM, 自适应量化算法,把 64kbit/s 压缩到 32kbit/s 。
2.6 AAC
AAC 是高级音频编码(Advanced Audio Coding) 的缩写,出现于 1997 年,最初是基于 MPEG-2 的音频编码技术。由 Fraunhofer IIS、Dolby Laboratories、AT&T、Sony 等公司共同开发,目的是取代 MP3 格式。2000 年,MPEG-4 标准出现后,AAC 重新集成了其特性,加入了 SBR 技术和 PS 技术,为了区别于传统的 MPEG-2 AAC 又称为 MPEG-4 AAC。
利用 AAC 格式,可使人感觉声音质量没有明显降低的前提下,更加小巧。相对于 mp3,AAC 格式的音质更佳,文件更小。AAC 属于 有损压缩 的格式,与时下流行的 APE、FLAC 等无损格式 相比音质存在“本质上”的差距。加之,传输速度更快的 USB3.0 和 16G 以上大容量 MP3 正在加速普及,也使得 AAC 头上“小巧”的光环不复存在。
文件封装格式:
- .aac:使用 MPEG-2 AAC 编码的容器,传统的 AAC 编码
- .mp4:使用 MPEG-4 AAC 编码的容器;
- .m4a:其本质与音频 MP4 相同,苹果公司为区别视频 mp4 故改名为 m4a,这个扩展名变得流行了。
2.7 OPUS
Opus 是一个有损声音编码的格式,由 Xiph.Org 基金会开发,之后由 IETF(互联网工程任务组)进行标准化,目标是希望用单一格式包含声音和语音,取代 Speex 和 Vorbis,且适用于网络上低延迟的即时声音传输,标准格式定义于 RFC 6716 文件。Opus 格式是一个开放格式,使用上没有任何专利或限制。
Opus 集成了两种声音编码的技术:以语音编码为导向的 SILK 和低延迟的 CELT。Opus 可以无缝调节高低比特率。在编码器内部它在较低比特率时使用线性预测编码在高比特率时候使用变换编码(在高低比特率交界处也使用两者结合的编码方式)。Opus 具有非常低的算法延迟(默认为 22.5 ms),非常适合用于低延迟语音通话的编码,像是网上上的即时声音流、即时同步声音旁白等等,此外 Opus 也可以透过降低编码码率,达成更低的算法延迟,最低可以到 5 ms。在多个听觉盲测中,Opus 都比 MP3、AAC、HE-AAC 等常见格式,有更低的延迟和更好的声音压缩率。
2.8 AMR
AMR( Adaptive Multi-Rate)自适应多速率音频压缩。AMR 被标准语音编码 3GP 在 1998 年 10 月选用,现在广泛在 GSM 和 UMTS 中使用。它使用 1-8 个不同的位速编码。
之前的手机里有很多 amr 的音频文件,可分成:AMR-NB,AMR-WB 和 AMR-WB+三种不同的协议。AMR-NB 应用于窄带,而 AMR-WB 和 AMR-WB+则应用于宽带通信中。
AMR 声码器采用 ACELP (Algebraic Code Excited Linear Prediction)编码方式,提供了 8 种编码速率(4.75~12.20kbit/s) ,每种速率都有不同的容错率。
2.9 WMA
WMA 就是 Windows Media Audio 编码后的文件格式, 由微软开发, 和以往的编码不同, WMA 支持防复制功能, 支持通过 Windows Media Rights Manager 加入保护, 可以限制播放时间和播放次数甚至于播放的机器等等。
WMA 支持流技术, 即一边读一边播放, 因此 WMA 可以很轻松的实现在线广播, 微软在 Windows 中加入了对 WMA 的支持, WMA 有着优秀的技术特征, 在微软的大力推广下, 这种格式被越来越多的人所接受。
2.10 ADPCM
DPCM, Adaptive Differential Pulse Code Modulation, 自适应差分脉冲编码调制.压缩比 4:1。ADPCM 算法是一个统称, 有 YAMAHA, Microsoft, IMA 等标准, 开发中最常见的 IMA ADPCM 。
四、如何选择音频编解码格式
从大方向上看,我们选择音频编解码方案时主要考虑两点“可不可用” 和 “好不好用” ,而每个大方向上,会有其细分维度。
1. 可不可用
首先是“可不可用”。具体的应用场景,可能因为某些“限制”导致某些编解码方式“不可用”或者“仅可用”,这些限制主要涉及“兼容性”和“适用性”两方面。
对于兼容性,就音视频场景来说,主要指流媒体传输协议兼容性和平台兼容性。而平台可能绑定某种流媒体传输协议,二者一般是关联考虑的。比如微信小程序平台支持 RTMP 传输协议,而 RTMP 协议支持 AAC 音频编码,就形成了一定制约。另外需要注意的是,如果某两个平台支持的音频编解码格式不同,又有互通需求,可能就需要通过服务端转码的方式来搭建桥梁。
对于适用性,主要指的是“频宽支持是否符合场景需求”。频宽指的是声音频率的支持范围,人耳对声音频率的感知范围(20Hz~20kHz)可以被划分成四个频宽区间:窄带、宽带(wideband)、超宽带(super-Wideband)和 全带(fullband),如下图所示:
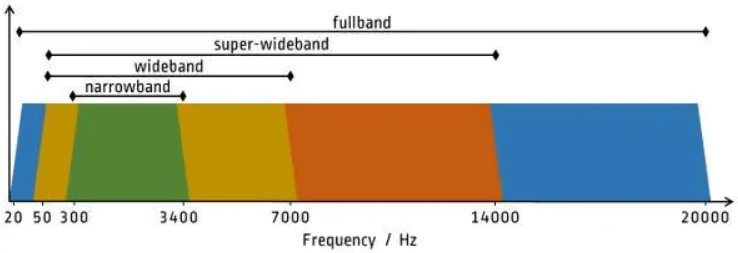
结合已学习的声音频率、采样率、奈奎斯特采样定理等概念,大家应该很容易就能理解上述图表。举一个简单的例子,音频编解码格式 G.711 仅支持窄带信号,所以在编码普通语音(低频)时“可用“,适用于固话、电话场景,但是在编码全带信号时“不可用”,不适用于音乐直播等场景。
2. 好不好用
某种编解码格式 “好不好用” ,主要指的是:它在满足特定场景基本要求的基础上,能否将编码工作做到“尽善尽美”。而在 RTC 场景下,关于“尽善尽美” 我们主要考虑音质和延迟两方面。
关于音质。音质是大家普遍关注的指标,它的影响因素还比较多,除了已经提到的采样率,还有采样位深和声道数,支持的采样位深越大、声道数越多,自然可以更好的保证音质。比如 AAC 支持 96khz 采样和多达 48 个声道,这让它在追求高音质的场景备受青睐。既然采样率、采样位深和声道数均影响音质,那么基于三者计算的综合指标 – 码率,自然也不例外。一般来说,支持的码率越高、越广,音质越能得到保障、灵活性也越大。那些仅支持固定码率的编码格式,比如仅支持 64kbps 码率的 G.711,其适用范围、音质上限就受到很大的限制了。
关于延迟。延迟在音视频传输中,指的是音视频数据从“主播端麦克风采集“、到从“观众端扬声器播放”的“端到端耗时”,这个耗时由音视频处理链路上的各个环节引入,包括采集、前处理、编解码、网络传输、渲染播放等等。显然,延迟越低意味着实时性越高,也就越接近于“面对面沟通”,在有连麦互动需求的场景中,“低延迟”甚至是最重要的需求之一,关乎用户体验的核心。所以,根据场景需求,选择一个延迟合适的编解码格式相当重要。
3. 总结
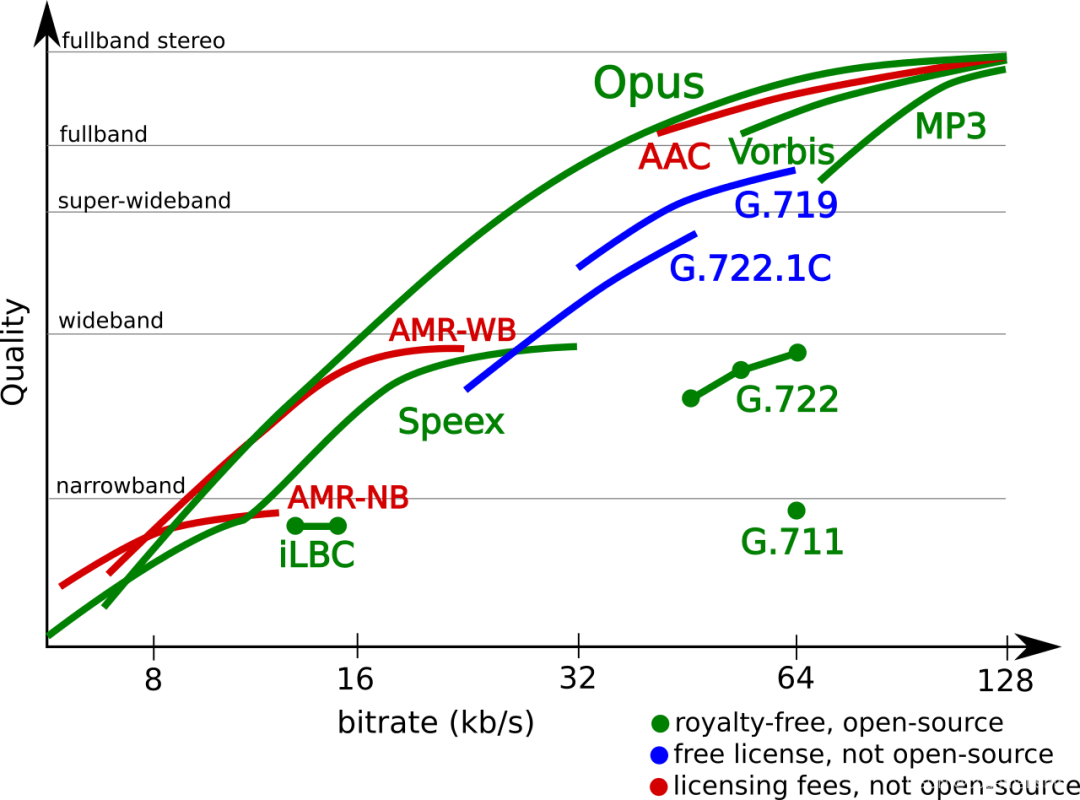
当我们选择编解码方案时,我们其实是在 选择 “兼容性” 和 “适用性”,进一步的,还需要关注 “音质” 和 “延迟”,通过这四个细分维度,就基本能保证所选方案是”可用“且“好用”的。下图展示了不同音频编码在不同码率 (Bitrate)、不同频宽上的音质表现(Quaity)。
参考资料: