
LV015-WAV格式
前面我们了解了 PCM 数据,这是原始的音频数据,一般播放器是无法直接播放的,不能总是用前面说的 ffplay 或者 Cool edit 吧。接下来我们来看一下 WAV 格式的文件。
一、WAV 简介
1. WAV 是什么?
WAV 是微软公司开发的一种声音文件格式,它符合 RIFF(Resource Interchange File Format) 文件规范,用于保存 Windows 平台的音频信息资源,被 Windows 平台及其应用程序所广泛支持。
wav 文件格式是无损音频文件格式,相对于其他音频格式文件数据是没有经过压缩的,通常文件也相对比较大些。PCM 是没有压缩的编码方式。PCM 是无损 wav 文件中音频数据的一种编码方式,需要知道的是 wav 还可以用其它方式编码,并不一定全部都是 PCM。
这里有两篇文档可以参考:Microsoft Word - riffmci.rtf、Wave File Specifications
2. RIFF 概念
在 Windows 环境下,大部分的多媒体文件都依循着一种结构来存放信息,这种结构称为 "资源互换文件格式"(Resources lnterchange File Format),简称 RIFF。例如声音的 WAV 文件、视频的 AV1 文件等等均是由此结构衍生出来的。RIFF 可以看做是一种树状结构,其基本构成单位为 chunk,犹如树状结构中的节点,每个 chunk 由 "辨别码"、"数据大小" 及 "数据" 所组成。

3. 播放时间
基于 PCM 格式的 WAVE 文件(*.wav)中至少带有 44 个字节的头信息, 音频播放时间取决于音频数据的长度,而不是整个文件大小。头信息是固定的,不参与播放。因此,计算已播放时间时,需要
(1)先确定文件总大小。
(2)减去头信息的大小(例如,44字节),得到纯音频数据的大小。
(3)根据音频参数(如采样率、位深度和声道数)计算时间。公式一般为:播放时间(秒) = 音频数据大小(字节) / (采样率 × 位深度/8 × 声道数)。例如,如果采样率为44.1kHz、16位、立体声(2声道),则每秒钟音频数据大小约为176,400字节(44,100 × 2 × 2)。
二、文件格式
1. WAV 格式
WAVE 文件是非常简单的一种 RIFF 文件,它的格式类型为 "WAVE"。RIFF 块包含两个子块,这两个子块的 ID 分别是 "fmt" 和 "data", 其中 "fmt" 子块由结构 PcmWaveFormat 所组成,其子块的大小就是 sizeof(PcmWaveFormat), 数据组成就是 PcmWaveFormat 结构中的数据。

WAV 文件由若干个 RIFF chunk 构成,分别为: RIFF WAVE Chunk,Format Chunk,Fact Chunk(可选),Data Chunk。另外,文件中还可能包含一些可选的区块,如:Fact chunk、Cue points chunk、Playlist chunk、Associated data list chunk 等。
基本 WAV 文件头(包括 RIFF Chunk 和 fmt Subchunk)的 最小长度为 44 字节(12 字节的 RIFF Chunk 加上 16 字节的 fmt Subchunk 加上 4 字节的 data Subchunk ID 和 4 字节的 data Subchunk Size)。
WAV 文件可以包含额外的信息,如 'fact'、'list'、'JUNK' 等其他子块,这将增加文件头的总长度。在没有这些额外子块的情况下,最小文件头长度为 44 字节。当涉及到实际的音频数据时,'data' 子块的大小将决定整个文件的大小。
2. 格式解析
2.1 RIFF chunk

typedef struct
{
char ChunkID[4]; //'R','I','F','F'
unsigned int ChunkSize;
char Format[4]; //'W','A','V','E'
} riff_chunk;| 内容 | size | 含义 |
|---|---|---|
| ChunkID | 4 bytes | RIFF |
| ChunkSize | 4 bytes | 从下一个字段首地址开始到文件末尾的总字节数。该字段的数值加 8 为当前文件的实际长度 |
| Format | 4 bytes | WAVE |
其中 ChunkSize 代表的是整个 file_size 的大小减去 ChunkID 和 ChunkSize 的大小,即 file_size = ChunkSize + 8。
2.2 fmt chunk
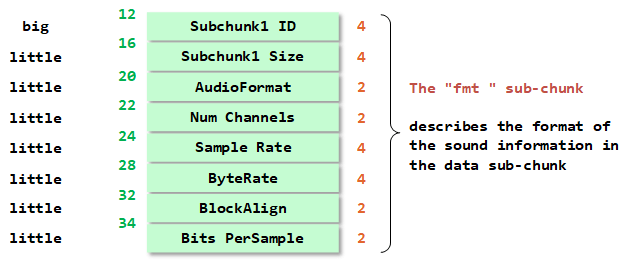
typedef struct
{
char FmtID[4];
unsigned int FmtSize;
unsigned short FmtTag;
unsigned short FmtChannels;
unsigned int SampleRate;
unsigned int ByteRate;
unsigned short BlockAilgn;
unsigned short BitsPerSample;
} fmt_chunk;| 内容 | size | 含义 |
| FmtID | 4 bytes | "fmt " |
| FmtSize | 4 bytes | fmt chunk 的大小,一般有 16/18/20/22/40 字节 (也有超过 40 字节的情况),超过 16 字节部分为扩展块 |
| FmtTag | 2 bytes | 编码格式代码,其值见常见编码格式表,如果上述取值为 16,则此值通常为 1,代表该音频的编码方式是 PCM 编码 |
| FmtChannels | 2 bytes | 声道数目,1 代表单声道,2 代表双声道 |
| SampleRate | 4 bytes | 采样频率,8/11.025/12/16/22.05/24/32/44.1/48/64/88.2/96/176.4/192 kHZ4 bytesByteRate 传输速率,每秒的字节数,计算公式为: SampleRate * FmtChannels * BitsPerSample/8 |
| BlockAilgn | 2 bytes | 块对齐,告知播放软件一次性需处理多少字节,公式为: BitsPerSample*FmtChannels/8 |
| BitsPerSample | 2 bytes | 采样位数,一般有 8/16/24/32/64,值越大,对声音的还原度越高 |
| 格式编码 | 格式名称 | fmt 块长度 | fact 块 |
|---|---|---|---|
| 0x01 | PCM / 非压缩格式 | 16 | |
| 0x02 | Microsoft ADPCM | 18 | √ |
| 0x03 | IEEE float | 18 | √ |
| 0x06 | ITU G.711 a-law | 18√ | |
| 0x07 | ITU G.711 μ-law | 18√ | |
| 0x031 | GSM 6.10 | 20 | √ |
| 0x040 | ITU G.721 ADPCM | √ | |
| 0xFFFE | 见子格式块中的编码格式 | 40 |
2.3 data chunk
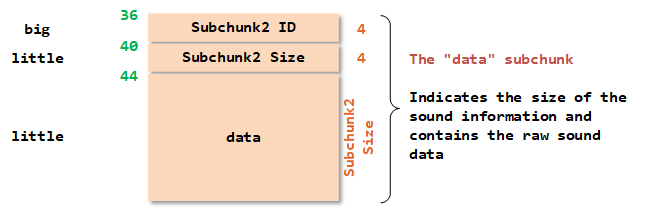
struct DATA_CHUNK
{
char DataID[4]; //'d','a','t','a'
unsigned int DataSize;
};| 内容 | size | 含义 |
|---|---|---|
| DataID | 4 bytes | data |
| DataSize | 4 bytes | 原始音频数据的大小 |
3.1 ffmpeg 转 pcm 为 wav
我们可以网上找一个 wav 文件,或者找个 pcm 文件用 ffmpeg 转一下,用 ffmpeg 转的话,可以用下面的命令:
ffmpeg -f s16le -ar 16000 -ac 1 -i input.pcm output.wav
# -f s16le:指定输入 PCM 格式为有符号 16 位小端序(常见格式)
# -ar 16000:设置采样率为 16kHz
# -ac 1:设置声道数为单声道(立体声改为-ac 2)
# -i input.pcm:输入 PCM 文件
# 常见 PCM 格式调整: 8 位无符号:-f u8、32 位浮点:-f f32le、立体声 48kHz:-ar 48000 -ac 2像前面我们找的测试文件:e9372/pcm 测试文件.rar · 开源工具包/语音 PCM 测试文件专用 - AtomGit | GitCode 就可以直接用 ffmpeg 转,转完后就可以直接用 windows 自带的播放器播了。转完我们可以看一下开头的部分:

pcm 转成 wav 其实就是加上了一些 LIST 块,这会导致头的结构发生一些变化,这里就先不深究了。
52 49 46 46 F2 C2 A2 00 57 41 56 45 66 6D 74 20 10 00 00 00 01 00 01 00 80 3E 00 00 00 7D 00 00 02 00 10 00 4C 49 53 54 1A 00 00 00 49 4E 46 4F 49 53 46 54 0D 00 00 00 4C 61 76 66 36 32 2E 36 2E 31 30 33 00 00 64 61 74 61 AC C2 A2 00这些加起来一共是 78 个字节,ffmpeg 转的时候,还添加了一些 LIST 块。
3.2 python 脚本
上面转出来添加了很多其他字段,其实是没啥必要的,我们字节可以写一个脚本来添加 44 字节头,例如:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import struct
import os
import sys
class WavHeader:
"""WAV文件44字节头部类"""
def __init__(self):
# RIFF chunk
self.chunk_id = b'RIFF' # 4 bytes
self.chunk_size = 0 # 4 bytes
self.format = b'WAVE' # 4 bytes
# fmt chunk
self.fmt_id = b'fmt ' # 4 bytes
self.fmt_chunk_size = 16 # 4 bytes (PCM 格式固定为 16)
self.audio_format = 1 # 2 bytes (PCM 编码为 1)
self.num_channels = 1 # 2 bytes
self.sample_rate = 16000 # 4 bytes
self.byte_rate = 0 # 4 bytes
self.block_align = 0 # 2 bytes
self.bits_per_sample = 16 # 2 bytes
# data chunk
self.data_id = b'data' # 4 bytes
self.data_size = 0 # 4 bytes
def calculate_derived_fields(self):
"""根据基本字段计算派生字段"""
self.byte_rate = self.sample_rate * self.num_channels * self.bits_per_sample // 8
self.block_align = self.num_channels * self.bits_per_sample // 8
def set_chunk_size(self, pcm_size):
"""设置chunk大小 (文件总大小 - 8)"""
self.chunk_size = pcm_size + 44 - 8
def set_data_size(self, pcm_size):
"""设置数据块大小"""
self.data_size = pcm_size
def to_bytes(self):
"""将WAV头部转换为字节串"""
# 计算派生字段
self.calculate_derived_fields()
# 构建字节串
header = bytearray()
# RIFF chunk (12 bytes)
header.extend(self.chunk_id)
header.extend(struct.pack('<I', self.chunk_size))
header.extend(self.format)
# fmt chunk (16 bytes)
header.extend(self.fmt_id)
header.extend(struct.pack('<I', self.fmt_chunk_size))
header.extend(struct.pack('<H', self.audio_format))
header.extend(struct.pack('<H', self.num_channels))
header.extend(struct.pack('<I', self.sample_rate))
header.extend(struct.pack('<I', self.byte_rate))
header.extend(struct.pack('<H', self.block_align))
header.extend(struct.pack('<H', self.bits_per_sample))
# data chunk (8 bytes)
header.extend(self.data_id)
header.extend(struct.pack('<I', self.data_size))
return bytes(header)
def __str__(self):
"""返回头部信息的字符串表示"""
return f"""WAV Header Information:
RIFF Chunk:
Chunk ID: {self.chunk_id}
Chunk Size: {self.chunk_size}
Format: {self.format}
Format Chunk:
Fmt ID: {self.fmt_id}
Fmt Chunk Size: {self.fmt_chunk_size}
Audio Format: {self.audio_format}
Number of Channels: {self.num_channels}
Sample Rate: {self.sample_rate}
Byte Rate: {self.byte_rate}
Block Align: {self.block_align}
Bits Per Sample: {self.bits_per_sample}
Data Chunk:
Data ID: {self.data_id}
Data Size: {self.data_size}"""
def add_wav_header(pcm_file_path, wav_file_path=None, sample_rate=16000, bits_per_sample=16, channels=1):
"""
为PCM文件添加WAV头,封装为WAV格式
参数:
pcm_file_path: 输入的PCM文件路径
wav_file_path: 输出的WAV文件路径,默认为在原文件名基础上添加.wav后缀
sample_rate: 采样率,默认16000
bits_per_sample: 位深度,默认16
channels: 声道数,默认1
"""
# 如果未指定输出文件路径,则在原文件名基础上添加.wav 后缀
if wav_file_path is None:
wav_file_path = pcm_file_path + ".wav"
# 读取 PCM 文件
with open(pcm_file_path, 'rb') as pcm_file:
pcm_data = pcm_file.read()
# 获取 PCM 数据长度
pcm_size = len(pcm_data)
# 创建 WAV 头部对象
wav_header = WavHeader()
# 设置头部参数
wav_header.sample_rate = sample_rate
wav_header.bits_per_sample = bits_per_sample
wav_header.num_channels = channels
wav_header.set_data_size(pcm_size)
wav_header.set_chunk_size(pcm_size)
# 写入 WAV 文件
with open(wav_file_path, 'wb') as wav_file:
wav_file.write(wav_header.to_bytes())
wav_file.write(pcm_data)
print(f"成功创建WAV文件: {wav_file_path}")
print(f"原始PCM文件大小: {pcm_size} 字节")
print(f"WAV文件总大小: {pcm_size + 44} 字节")
print(f"采样率: {sample_rate} Hz")
print(f"位深度: {bits_per_sample} bits")
print(f"声道数: {channels}")
def main():
if len(sys.argv) < 2:
print("使用方法: python add_wav_header.py <pcm_file_path> [wav_file_path]")
print("示例: python add_wav_header.py input.pcm output.wav")
return
pcm_file_path = sys.argv[1]
if not os.path.exists(pcm_file_path):
print(f"错误: 文件 {pcm_file_path} 不存在")
return
wav_file_path = sys.argv[2] if len(sys.argv) > 2 else None
# 为指定的 PCM 文件添加 WAV 头
add_wav_header(
pcm_file_path=pcm_file_path,
wav_file_path=wav_file_path,
sample_rate=16000, # 16kHz 采样率
bits_per_sample=16, # 16 位深度
channels=1 # 单声道
)
if __name__ == "__main__":
main()参考资料: