
LV010-0长度数组
这部分会提前用到内存管理、结构体等相关知识。这里使用的是 ubuntu18.04,gcc 版本为 7.5.0
一、0 长度数组简介
在内核中,肯呢个会看到 0 长度的数组,来简单了解下这种数组。
1. 基本概念
GNU/GCC 在标准的 C/C++ 基础上做了有实用性的 扩展, 零长度数组(Arrays of Length Zero) 就是其中一个知名的扩展。多数情况下, 其应用在变长数组中。
0长度数组, 也叫柔性数组。 主要用途是为了满足 需要变长度的结构体。
Tips:C 语言标准并不支持 0 长度数组,它是 GCC 的一个扩展语法。
2. 直接定义?
2.1 定义形式
int a[0]; // 编译器扩展,将长度0作为特例处理
int a[]; // 标准特性,由C99正式引入,但是后面试了一下,单独定义的话,怎么编译都会报错,放在结构体中就不会有问题。2.2 示例
能直接定义吗?来尝试一下:
#include <stdio.h>
int main(int argc, const char *argv[])
{
int a[0];
int size_a = 0;
int len_a = 0;
size_a = sizeof(a);
len_a = sizeof(a) / sizeof(a[0]);
printf("size_a=%d len_a=%d\n", size_a, len_a);
printf("addr=%p\n", a);
return 0;
}我们编译运行:

发现这样地址是可以访问的,只是大小和长度都是 0。
3. 能赋值吗?
说明:这里的示例,其实都是在非法操作内存!!!
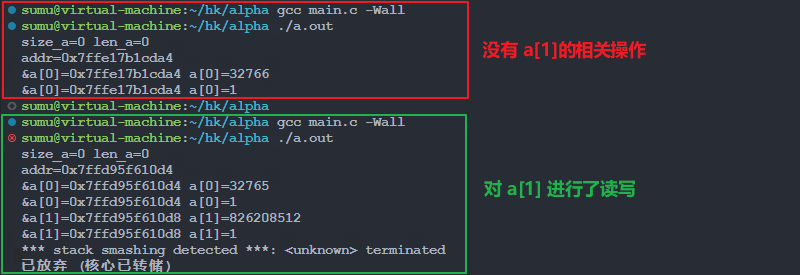
理论上来说,是不能直接赋值的,因为 0 长度数组长度为 0,并没有为它分配内存,但是,实测证明,可以为首个元素赋值,而且可以访问,但是从第二个元素开始就会报错。
#include <stdio.h>
int main(int argc, const char *argv[])
{
int a[0];
int size_a = 0;
int len_a = 0;
size_a = sizeof(a);
len_a = sizeof(a) / sizeof(a[0]);
printf("size_a=%d len_a=%d\n", size_a, len_a);
printf("addr=%p\n", a);
printf("&a[0]=%p a[0]=%d\n", &a[0], a[0]);
a[0] = 1;
printf("&a[0]=%p a[0]=%d\n", &a[0], a[0]);
// (1)下面的部分将会导致程序崩溃,出现段错误
printf("&a[1]=%p a[1]=%d\n", &a[1], a[1]);
a[1] = 1;
printf("&a[1]=%p a[1]=%d\n", &a[1], a[1]);
return 0;
}我们可以屏蔽(1)部分,然后放开(1)这一部分,看一下运行区别:
这里用的 gcc 版本为:
sumu@virtual-machine:~/hk/alpha gcc --version
gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.4. 真的没有分配内存吗?
真的没有为它分配内存吗?我们是可以测试一下的,先来了解一个工具。
4.1 AddressSanitizer
AddressSanitizer(简称为 ASan)是 Google 开发的一个 C/C++内存错误检测工具,通过在编译时插入探测代码来检测释放后使用、缓冲区溢出(下标越界)、内存泄露等内存错误。
GCC 编译器(4.8 版本以上)自带了 AddressSanitizer。我们可以在编译的时候这样使用:
gcc -fsanitize=address -g 源文件 -Wall4.2 一个示例
我们直接用上面的 0 长度数组试一下:
#include <stdio.h>
int main(int argc, const char *argv[])
{
int a[0];
int size_a = 0;
int len_a = 0;
size_a = sizeof(a);
len_a = sizeof(a) / sizeof(a[0]);
printf("size_a=%d len_a=%d\n", size_a, len_a);
printf("addr=%p\n", a);
printf("&a[0]=%p a[0]=%d\n", &a[0], a[0]);
a[0] = 1;
printf("&a[0]=%p a[0]=%d\n", &a[0], a[0]);
return 0;
}用下面的命令编译:
gcc -fsanitize=address -g main.c -Wall会得到以下输出:
sumu@virtual-machine:~/hk/alpha gcc -fsanitize=address -g main.c -Wall
sumu@virtual-machine:~/hk/alpha ./a.out
size_a=0 len_a=0
addr=0x7fff062f99f0
=================================================================
==26117==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fff062f99f0 at pc 0x5651c68a9c90 bp 0x7fff062f99a0 sp 0x7fff062f9990
READ of size 4 at 0x7fff062f99f0 thread T0
#0 0x5651c68a9c8f in main /home/sumu/hk/alpha/main.c: 15
#1 0x7f8dda122b96 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x21b96)
#2 0x5651c68a9a89 in _start (/home/sumu/hk/alpha/a.out+0xa89)
Address 0x7fff062f99f0 is located in stack of thread T0 at offset 32 in frame
#0 0x5651c68a9b79 in main /home/sumu/hk/alpha/main.c: 4
This frame has 1 object(s):
[32, 33) 'a' <== Memory access at offset 32 partially overflows this variable
HINT: this may be a false positive if your program uses some custom stack unwind mechanism or swapcontext
(longjmp and C++ exceptions *are* supported)
SUMMARY: AddressSanitizer: stack-buffer-overflow /home/sumu/hk/alpha/main.c:15 in main
Shadow bytes around the buggy address:
0x100060c572e0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c572f0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57300: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57310: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57320: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x100060c57330: 00 00 00 00 00 00 00 00 00 00 f1 f1 f1 f1[01]f2
0x100060c57340: f2 f2 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57350: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57360: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57370: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x100060c57380: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==26117==ABORTING会发现在第 15 行访问 a [0] 的时候就报错了,因为 a [0] 并没有分配内存,但是这个地址是存在的,但是访问是非法的。
4.3 结论
不占用内存:零长度数组
int a[0];本身不占用任何内存空间,提供 "占位符":虽然不占空间,但数组名 a 本身是一个符号地址,代表着紧随结构体尾部之后的内存地址的起始。这个特性使其成为实现动态大小结构的理想“占位符”。
5. 那怎么使用?
一般来说不会单独使用 0 长度数组,它常用于结构体中。
在一个结构体的最后, 申明一个长度为 0 的数组, 就可以使得这个结构体是可变长的. 对于编译器来说, 此时长度为 0 的数组并不占用空间, 因为数组名本身不占空间, 它只是一个偏移量, 数组名这个符号本身代表了一个不可修改的地址常量。
struct Example {
int length;
char data[0]; // 这里的 0 长结构体就为变长结构体提供了非常好的支持
};这种方式比起在结构体中声明一个指针变量、再进行动态分配的办法,这种方法效率要高。因为在访问数组内容时,不需要间接访问,避免了两次访存。缺点就是在结构体中,数组为 0 的数组必须在最后声明,使 用上有一定限制。
那使用的时候怎么用?我们需要通过 malloc 来为结构体变量申请内存空间:
#include <stdio.h>
#include <stdlib.h>
struct Example {
int length;
char data[0]; // 这里的 0 长结构体就为变长结构体提供了非常好的支持
};
int main() {
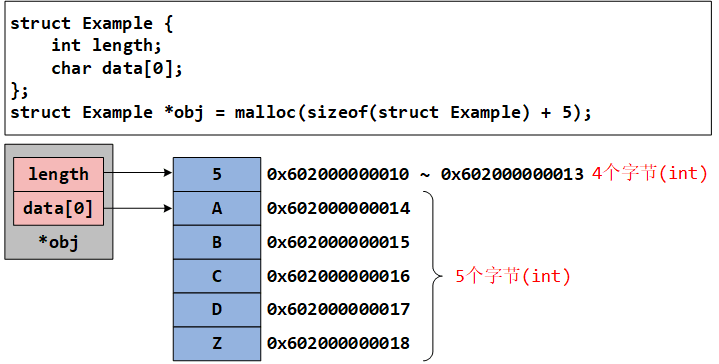
// 分配结构体 + 5 字节的额外空间
struct Example *obj = malloc(sizeof(struct Example) + 5);
if (obj == NULL) return 1;
obj->length = 5;
obj->data[0] = 'A'; // 合法!此时 data 指向新分配的内存
obj->data[1] = 'B'; // 合法!此时 data 指向新分配的内存
obj->data[2] = 'C'; // 合法!此时 data 指向新分配的内存
obj->data[3] = 'D'; // 合法!此时 data 指向新分配的内存
obj->data[4] = 'Z'; // 合法,访问索引 0~4
printf("sizeof(struct Example)=%ld\n", sizeof(struct Example));
printf("&obj->length=%p,obj->length=%d\n", &obj->length, obj->length);
printf("&obj->data[0]=%p,obj->data[0]=%c\n", &obj->data[0], obj->data[0]);
printf("&obj->data[1]=%p,obj->data[1]=%c\n", &obj->data[1], obj->data[1]);
printf("&obj->data[2]=%p,obj->data[2]=%c\n", &obj->data[2], obj->data[2]);
printf("&obj->data[3]=%p,obj->data[3]=%c\n", &obj->data[3], obj->data[3]);
printf("&obj->data[4]=%p,obj->data[4]=%c\n", &obj->data[4], obj->data[4]);
free(obj); // 释放内存
return 0;
}我们用下面的命令编译然后运行:
gcc -fsanitize=address -g main.c -Wall可以得到如下打印信息:

这个时候,内存空间应该是这样的:
6. 为什么不占内存?
0 长度数组与指针实现有什么区别,为什么 0 长度数组不占用存储空间?其实本质上涉及到的是一个 C 语言里面的数组和指针的区别问题. char a[1] 里面的 a 和 char *b 的 b 相同吗?
《 Programming Abstractions in C》(Roberts, E. S.,机械工业出版社,2004.6)82 页里面有如下内容:
“arr is defined to be identical to &arr[0]”.也就是说,char a [1] 里面的 a 实际是一个常量,等于&a [0]。而 char *b 是有一个实实在在的指针变量 b 存在。 所以,a = b 是不允许的,而 b = a 是允许的。 两种变量都支持下标式的访问,那么对于 a [0] 和 b [0] 本质上是否有区别?我们可以通过一个例子来说明。
6.1 两个示例
6.1.1 zero_length_array.c
#include <stdio.h>
#include <stdlib.h>
struct str {
int len;
char s[0];
};
struct foo {
struct str *a;
};
int main(int argc, const char *argv[])
{
struct foo f = { NULL };
printf("sizeof(struct str) = %ld\n", sizeof(struct str));
printf("before f.a->s.\n");
if(f.a->s)
{
printf("before printf f.a->s.\n");
printf("f.a->s=%s", f.a->s);
printf("before printf f.a->s.\n");
}
return EXIT_SUCCESS;
}我们编译并执行:

6.1.2 pzero_length_array.c
#include <stdio.h>
#include <stdlib.h>
struct str {
int len;
char *s;
};
struct foo {
struct str *a;
};
int main(int argc, const char *argv[])
{
struct foo f = { NULL };
printf("sizeof(struct str) = %ld\n", sizeof(struct str));
printf("before f.a->s.\n");
if(f.a->s)
{
printf("before printf f.a->s.\n");
printf("f.a->s=%s", f.a->s);
printf("before printf f.a->s.\n");
}
return EXIT_SUCCESS;
}编译并运行:

6.1.3 小结
可以看到这两个程序虽然都存在访问异常, 但是段错误的位置却不同。
6.2 编译成汇编
我们把上面两个示例编译成汇编,然后对比一下:
gcc -S zero_length_array.c -Wall
gcc -S pzero_length_array.c -Wall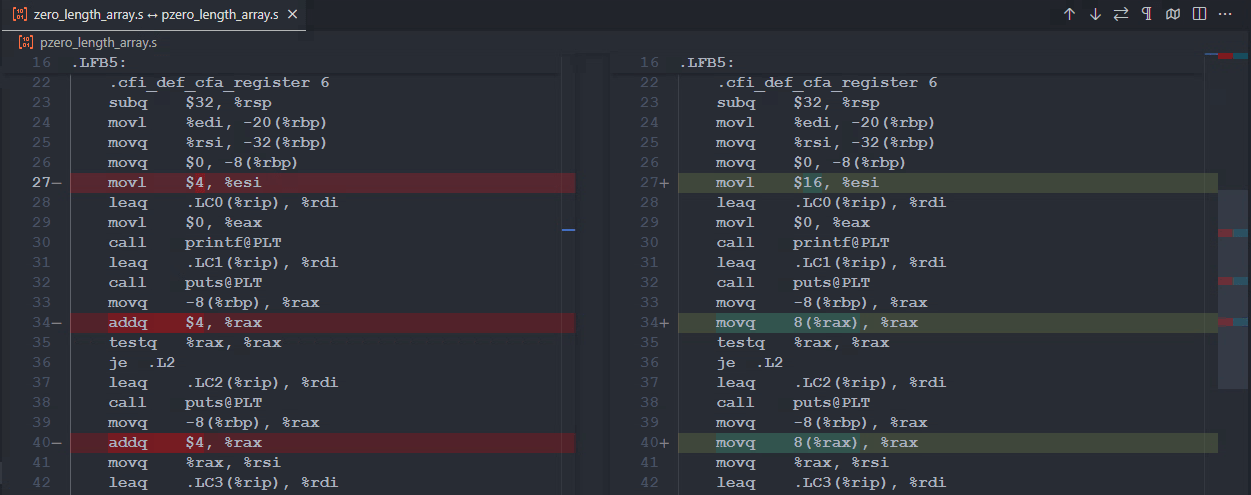
这样可能不太好看,我们可以通过 gdb 这样来做:
#!/bin/bash
# 用法: ./gen_asm.sh source_file.c [function_name]
SOURCE_FILE="${1:-a.c}"
FUNC_NAME="${2:-main}"
# 获取不带扩展名的文件名
BASENAME="${SOURCE_FILE%.c}"
OUTPUT_FILE="${BASENAME}.asm"
TARGET="$BASENAME.out"
# 编译
gcc -Wall -g -O0 "$SOURCE_FILE" -o $TARGET
# 生成混合输出
{
echo "======= C源码与汇编对应关系 ======="
echo "源文件: $SOURCE_FILE"
echo "函数: $FUNC_NAME"
echo "================================"
echo ""
} > "$OUTPUT_FILE"
gdb -batch -q -ex "set pagination off" \
-ex "disas /s $FUNC_NAME" \
./$TARGET >> "$OUTPUT_FILE"
echo "输出已保存到: $OUTPUT_FILE"然后我们比较输出的 asm 文件就可以知道哪一行对应了哪些汇编文件。
Tips:需要注意的是,这里用 gdb 得到的汇编指令和直接编译成汇编文件得到的有些许不同,例如上面的 add 和 addq,其实都是加法指令,只是 addq 明确指定了是 64 位加法,是 add 指令的 64 位版本。
从 64 位系统中, 汇编我们看出, 变长数组结构的大小为 0x4(4), 而指针形式的结构大小为 0x10(16)。再来看 if(f.a->s) 这部分,
f.a->s
< addq $4, %rax
---
> movq 8(%rax), %rax- 对于
char s[0]来说, 汇编代码用了addq指令,addq $4, %rax - 对于
char*s来说,汇编代码用了movq指令,movq 8(%rax), %rax
6.2.1 汇编代码详解
char s[0]的情况:addq $4, %rax
addq $4, %rax将 %rax 的值加 4。执行过程如下:
(1)%rax 初始指向 struct str 的起始地址(即 len 的地址)
(2)addq $4 表示 len 字段占 4 字节
(3)结果:%rax 现在指向 char s[0] 的地址
这只是 地址计算,没有访问内存!数组名 s 本质上是一个 常量偏移量,等于 &s[0],编译器直接通过算术运算得到地址。
char *s的情况:movq 8(%rax), %rax
movq 8(%rax), %rax从 %rax + 8 地址处读取 8 字节数据到 %rax。执行过程如下:
(1)%rax 指向 struct str 起始地址
(2)8(%rax) 表示偏移 8 字节(int len 4 字节 + 指针 s 本身占 8 字节)
(3)movq 把该地址 内存中的内容(即指针 s 存储的地址值)加载到 %rax
这里 访问了内存,读取指针变量 s 本身存储的地址值。
6.2.2 为什么 movq 有时被称为 "leap 指令"?
"leap"(跳跃)这个说法很形象:
addq:只是计算地址,就像 走到 某个位置movq:从内存读取内容,就像 跳跃到 指针指向的另一个位置
6.2.3 结构体布局对比图
struct str 结构体布局:
char s[0] 的情况: char *s 的情况:
┌─────────────┐ ┌─────────────┐
│ len (4B) │ %rax │ len (4B) │ %rax
├─────────────┤ ├─────────────┤
│ s[0] (0B) │ %rax + 4 ──→ │ s (8B) │ %rax + 8
└─────────────┘ └─────────────┘
(不占空间) (占8B)
│
↓
读取 s 的值
(movq 指令)6.2.4 总结对比
| 特性 | char s[0] | char *s |
|---|---|---|
| 汇编指令 | addq $4, %rax | movq 8(%rax), %rax |
| 内存访问 | ❌ 无(仅计算地址) | ✅ 有(读取指针值) |
| 本质 | 数组名 = 常量偏移量 | 指针 = 存储地址的变量 |
| 空间占用 | 0 字节 | 8 字节(64 位系统) |
核心理解:访问成员数组名得到的是数组的 相对地址,而访问成员指针得到的是相对地址里的 内容(即指针指向的实际地址)。这就是零长度数组相比指针的优势所在——不需要额外的间接访问,效率更高。
二、GNU Document
接下来我们看看 GNU 官方文档对 0 长度数组的相关描述。主要参考:
在 C90 之前, 并不支持 0 长度的数组, 0 长度数组是 GNU C 的一个扩展, 因此早期的编译器中是无法通过编译的。对于 GNU C 增加的扩展, GCC 提供了编译选项来明确的标识出他们:
-pedantic选项,那么使用了扩展语法的地方将产生相应的警告信息-Wall使用它能够使 GCC 产生尽可能多的警告信息-Werror, 它要求 GCC 将所有的警告当成错误进行处理
1. 不同的编译选项
1.1 测试 demo
#include <stdio.h>
#include <stdlib.h>
int main(int argc, const char *argv[])
{
char a[0];
printf("%d\n", sizeof(a));
return EXIT_SUCCESS;
}1.2 -Wall
gcc main.c -Wall这个不会有任何的警告和错误。
1.3 -pedantic
gcc main.c -Wall -pedantic # 对 GNU C 的扩展显示警告会有以下警告:

1.4 -Werror
gcc main.c -Werror -Wall -pedantic # 显示所有警告同时 GNU C 的扩展显示警告, 将警告用 error 显示这样编译会直接报错:

2. 为什么要扩展它
0 长度数组其实就是灵活的运用的 数组指向的是其后面的连续的内存空间。
struct buffer
{
int len;
char data[0];
};在早期没引入 0 长度数组的时候, 大家是通过定长数组和指针的方式来解决的, 但是
- 定长数组定义了一个足够大的缓冲区, 这样使用方便, 但是每次都造成空间的浪费。
- 指针的方式, 要求程序员在释放空间是必须进行多次的 free 操作, 而我们在使用的过程中往往在函数中返回了指向缓冲区的指针, 我们并不能保证每个人都理解并遵从我们的释放方式。
所以 GNU 就对其进行了 0 长度数组的扩展。当使用 data [0] 的时候, 也就是 0 长度数组的时候,0 长度数组作为数组名, 并不占用存储空间。
在 C99 之后,也加了类似的扩展,只不过用的是 char payload [] 这种形式(所以如果我们在编译的时候确实需要用到 -pedantic 参数,那么我们可以将 char payload [0] 类型改成 char payload [], 这样就可以编译通过了,当然我们使用的编译器必须支持 C99 标准的,如果太古老的编译器,那可能不支持了)
#include <stdio.h>
#include <stdlib.h>
struct payload
{
int len;
char data[];
};
int main(int argc, const char *argv[])
{
struct payload pay;
printf("%ld\n", sizeof(pay));
return EXIT_SUCCESS;
}使用 -pedantic 编译后, 不出现警告, 说明这种语法是 C 标准的
gcc main.c -Wall -pedantic -std=c99这个时候结构体的末尾, 就是指向了其后面的内存数据。因此我们可以很好的将该类型的结构体作为数据报文的头格式,并且最后一个成员变量,也就刚好是数据内容了。
三、应用场景
我们设想这样一个场景, 我们在网络通信过程中使用的数据缓冲区, 缓冲区包括一个 len 字段和 data 字段, 分别标识数据的长度和传输的数据, 我们常见的有几种设计思路
- 定长数据缓冲区, 设置一个足够大小
MAX_LENGTH的数据缓冲区。 - 设置一个指向实际数据的指针, 每次使用时, 按照数据的长度动态的开辟数据缓冲区的空间。
我们从实际场景中应用的设计来考虑他们的优劣. 主要考虑的有, 缓冲区空间的开辟, 释放和访问。
1. 定长包(开辟空间, 释放, 访问)
比如我要发送 1024 字节的数据, 如果用 定长包, 假设定长包的长度 MAX_LENGTH 为 2048, 就会浪费 1024 个字节的空间, 也会造成不必要的流量浪费。
1.1 数据包结构定义
// 定长缓冲区
struct max_buffer {
int len;
char data[MAX_LENGTH];
};1.2 数据结构大小
考虑对齐, 那么数据结构的大小 >= sizeof(int) + sizeof(char) * MAX_LENGTH
由于考虑到数据的溢出, 变长数据包中的 data 数组长度一般会设置得足够长足以容纳最大的数据, 因此 max_buffer 中的 data 数组很多情况下都没有填满数据, 因此造成了浪费。
1.3 内存申请
假如我们要发送 CURR_LENGTH = 1024 个字节。一般来说, 我们会返回一个指向缓冲区数据结构 max_buffer 的指针:
/// 开辟
if ((mbuffer = (struct max_buffer *)malloc(sizeof(struct max_buffer))) != NULL)
{
mbuffer->len = CURR_LENGTH;
memcpy(mbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", mbuffer->len, mbuffer->data);
}1.4 数据访问
前面申请的这段内存要分两部分使用。
- 前部分 4 个字节 p→ len, 作为包头(就是多出来的那部分),这个包头是用来描述紧接着包头后面的数据部分的长度,这里是 1024, 所以前四个字节赋值为 1024 (既然我们要构造不定长数据包,那么这个包到底有多长呢,因此,我们就必须通过一个变量来表明这个数据包的长度,这就是 len 的作用),
- 而紧接其后的内存是真正的数据部分, 通过 p→ data, 最后, 进行一个 memcpy() 内存拷贝, 把要发送的数据填入到这段内存当中。
1.5 释放内存
那么当使用完毕释放数据的空间的时候, 直接释放就可以了:
/// 销毁
free(mbuffer);
mbuffer = NULL;1.6 小结
使用定长数组, 作为数据缓冲区, 为了避免造成缓冲区溢出, 数组的大小一般设为足够的空间 MAX_LENGTH, 而实际使用过程中, 达到 MAX_LENGTH 长度的数据很少, 那么多数情况下, 缓冲区的大部分空间都是浪费掉的。
但是使用过程很简单, 数据空间的开辟和释放简单, 无需程序员考虑额外的操作。
2. 指针数据包(开辟空间, 释放, 访问)
如果你将上面的长度为 MAX_LENGTH 的定长数组换为 指针, 每次使用时动态的开辟 CURR_LENGTH 大小的空间, 那么就避免造成 MAX_LENGTH - CURR_LENGTH 空间的浪费, 只浪费了一个指针域的空间。
2.1 数据包结构定义
struct point_buffer
{
int len;
char *data;
};2.2 数据结构大小
考虑对齐, 那么数据结构的大小 >= sizeof(int) + sizeof(char *)
2.3 内存申请
这样定义了一个指针来指向数据区域,也造成了使用在分配内存时,需采用两步:
// ==== ==== ==== ==== ==== =
// 指针数组 占用-开辟-销毁
// ==== ==== ==== ==== ==== =
/// 占用
printf("the length of struct test3:%d\n",sizeof(struct point_buffer));
/// 开辟
if ((pbuffer = (struct point_buffer *)malloc(sizeof(struct point_buffer))) != NULL) // 为结构体对象申请内存空间
{
pbuffer->len = CURR_LENGTH;
if ((pbuffer->data = (char *)malloc(sizeof(char) * CURR_LENGTH)) != NULL) // 为数据区域分配内存空间
{
memcpy(pbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", pbuffer->len, pbuffer->data);
}
}首先, 需为结构体分配一块内存空间;
其次再为结构体中的成员变量分配内存空间。
这样两次分配的内存是 不一定连续 的, 需要分别对其进行管理。当使用长度为的数组时, 则是采用一次分配的原则, 一次性将所需的内存全部分配给它。
2.4 释放内存
释放时也是一样的:
/// 销毁
free(pbuffer->data);
free(pbuffer);
pbuffer = NULL;2.5 小结
使用指针结果作为缓冲区, 只多使用了一个指针大小的空间, 无需使用 MAX_LENGTH 长度的数组, 不会造成空间的大量浪费.
但那是开辟空间时, 需要额外开辟数据域的空间, 释放时候也需要显式释放数据域的空间, 但是实际使用过程中, 往往在函数中开辟空间, 然后返回给使用者指向 struct point_buffer 的指针, 这时候我们并不能假定使用者了解我们开辟的细节, 并按照约定的操作释放空间, 因此使用起来多有不便, 甚至造成内存泄漏。
3. 变长数据缓冲区(开辟空间, 释放, 访问)
定长数组使用方便, 但是却浪费空间, 指针形式只多使用了一个指针的空间, 不会造成大量空间分浪费, 但是使用起来需要多次分配, 多次释放, 那么有没有一种实现方式能够既不浪费空间, 又使用方便的方案?
这个时候,0 长度数组就可以上场了。
3.1 数据包结构定义
// 0 长度数组
struct zero_buffer
{
int len;
char data[0];
};3.2 数据结构大小
这样的变长数组常用于网络通信中构造不定长数据包, 不会浪费空间浪费网络流量, 因为 char data[0]; 只是个数组名, 是不占用存储空间的。即:
sizeof(struct zero_buffer) = sizeof(int)3.3 内存申请
我们使用的时候, 只需要申请 1 次内存即可:
/// 开辟
if ((zbuffer = (struct zero_buffer *)malloc(sizeof(struct zero_buffer) + sizeof(char) * CURR_LENGTH)) != NULL)
{
zbuffer->len = CURR_LENGTH;
memcpy(zbuffer->data, "Hello World", CURR_LENGTH);
printf("%d, %s\n", zbuffer->len, zbuffer->data);
}3.4 释放空间
释放空间也是一样的, 一次释放即可:
/// 销毁
free(zbuffer);
zbuffer = NULL;4. 测试代码
// zero_length_array.c
#include <stdio.h>
#include <stdlib.h>
#define MAX_LENGTH 1024
#define CURR_LENGTH 512
// 0 长度数组
struct zero_buffer
{
int len;
char data[0];
}__attribute((packed));
// 定长数组
struct max_buffer
{
int len;
char data[MAX_LENGTH];
}__attribute((packed));
// 指针数组
struct point_buffer
{
int len;
char *data;
}__attribute((packed));
int main(int argc, const char *argv[])
{
struct zero_buffer *zbuffer = NULL;
struct max_buffer *mbuffer = NULL;
struct point_buffer *pbuffer = NULL;
// ==== ==== ==== ==== ==== =
// 0 长度数组 占用-开辟-销毁
// ==== ==== ==== ==== ==== =
printf("the length of struct test1:%d\n",sizeof(struct zero_buffer));
if ((zbuffer = (struct zero_buffer *)malloc(sizeof(struct zero_buffer) + sizeof(char) * CURR_LENGTH)) != NULL)
{
zbuffer->len = CURR_LENGTH;
memcpy(zbuffer->data, "Hello World", CURR_LENGTH);
printf("0长度数组:%d, %s\n", zbuffer->len, zbuffer->data);
}
/// 销毁
free(zbuffer);
zbuffer = NULL;
// ==== ==== ==== ==== ==== =
// 定长数组 占用-开辟-销毁
// ==== ==== ==== ==== ==== =
printf("the length of struct test2:%d\n",sizeof(struct max_buffer));
if ((mbuffer = (struct max_buffer *)malloc(sizeof(struct max_buffer))) != NULL)
{
mbuffer->len = CURR_LENGTH;
memcpy(mbuffer->data, "Hello World", CURR_LENGTH);
printf("定长数组:%d, %s\n", mbuffer->len, mbuffer->data);
}
/// 销毁
free(mbuffer);
mbuffer = NULL;
// ==== ==== ==== ==== ==== =
// 指针数组 占用-开辟-销毁
// ==== ==== ==== ==== ==== =
printf("the length of struct test3:%d\n",sizeof(struct point_buffer));
if ((pbuffer = (struct point_buffer *)malloc(sizeof(struct point_buffer))) != NULL)
{
pbuffer->len = CURR_LENGTH;
if ((pbuffer->data = (char *)malloc(sizeof(char) * CURR_LENGTH)) != NULL)
{
memcpy(pbuffer->data, "Hello World", CURR_LENGTH);
printf("指针:%d, %s\n", pbuffer->len, pbuffer->data);
}
}
/// 销毁
free(pbuffer->data);
free(pbuffer);
pbuffer = NULL;
return EXIT_SUCCESS;
}5. 小结
- 长度为 0 的数组并不占有内存空间, 而指针方式需要占用内存空间.
- 对于长度为 0 数组, 在申请内存空间时, 采用一次性分配的原则进行; 对于包含指针的结构体, 才申请空间时需分别进行, 释放时也需分别释放.
- 对于长度为的数组的访问可采用数组方式进行
参考资料:
C 语言 0 长度数组(可变数组/柔性数组)详解_零长数组使用-CSDN 博客