LV010-编译过程
一、编译基本命令
1. 有哪些命令?
我们先看几个编译命令,这里以单文件 test.c 为例:
#include <stdio.h>
int main(int argc, char **argv)
{
printf("Hello, world!\n");
return 0;
}这就是一个很简单的打印 helloworld 程序,我们执行下面的命令:
gcc test.c -o test # 直接编译成可执行文件
# 以上命令等价于执行以下全部操作
gcc -E test.c -o test.i # 预处理,可理解为把头文件的代码汇总成 C 代码,把 *.c 转换得到*.i 文件
gcc -S test.i -o test.s # 编译,可理解为把 C 代码转换为汇编代码,把 *.i 转换得到*.s 文件
gcc -c test.s -o test.o # 汇编,可理解为把汇编代码转换为机器码,把 *.s 转换得到*.o,即目标文件
gcc test.o -o test # 链接,把不同文件之间的调用关系链接起来,把一个或多个*.o 转换成最终的可执行文件然后我们就会得到以下文件:

2. 编译过程分析
GCC 编译的流程有四个步骤:
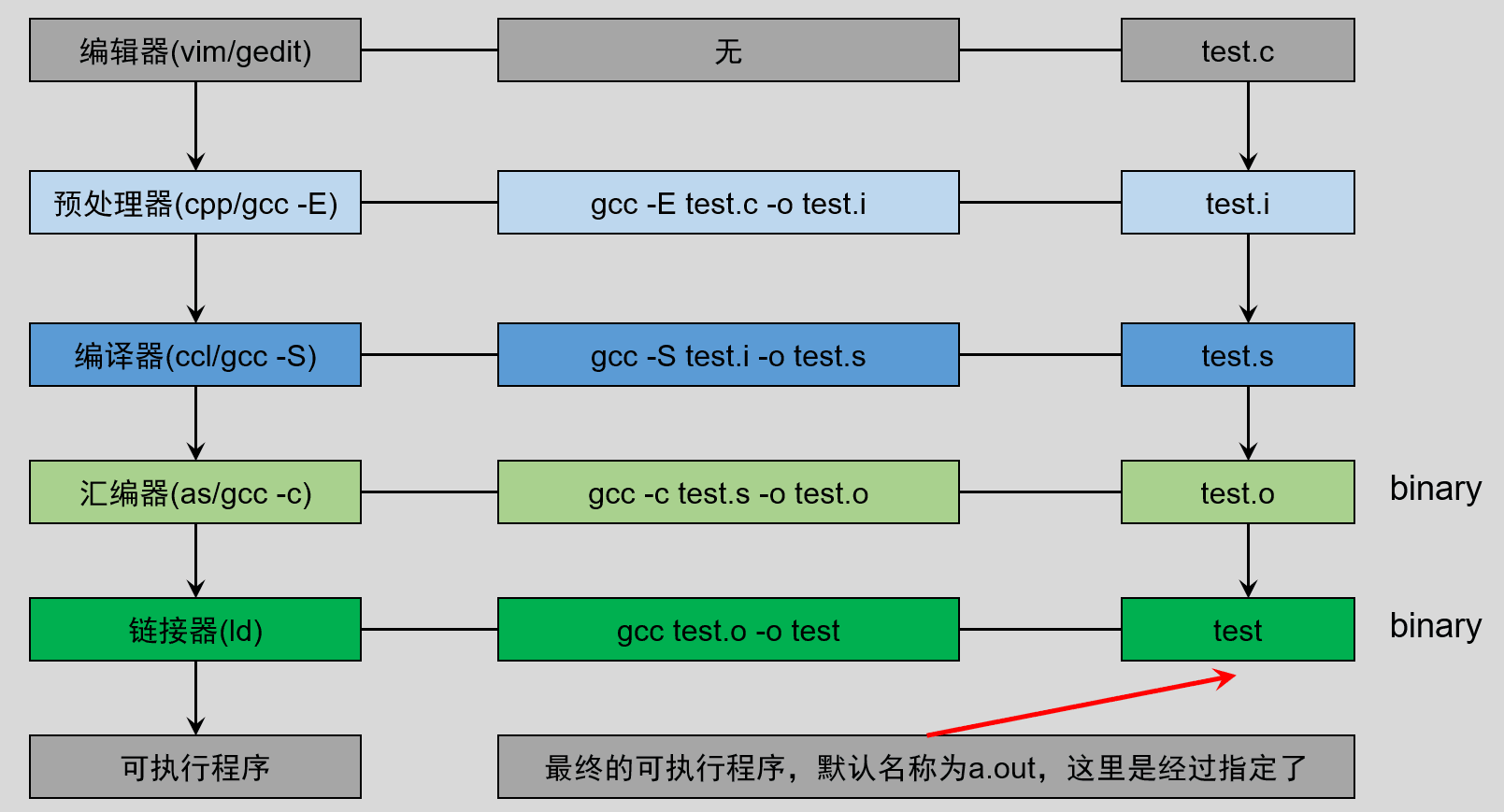
【编译命令】
gcc -E test.c -o test.i # 预处理, 得到预处理文件 *.i
gcc -S test.i -o test.s # 编译, 得到汇编文件 *.s
gcc -c test.s -o test.o # 汇编, 得到二进制文件 *.o
gcc test.o -o test # 链接, 得到可执行文件 *.out二、GCC 编译的步骤
接下来我们对每个步骤进行分析,想要更为详细的了解,可以看这本书:

1. 预处理( Pre-Processing )
预处理,主要是处理源文件和头文件中以 # 开头的命令,包括 #include 、 #define 、 #ifdef 等(关于这些后边还会详细学习)。
1.1 预处理的命令
预处理的命令如下:
gcc -E test.c -o test.i使用 GCC 的参数“-E”,可以让编译器生成.i 文件,参数“-o”,可以指定输出文件的名字。
1.2 预处理做了什么?
基本规则如下:
- 删除所有 #define ,并展开所有的宏定义。
- 处理所有条件编译命令,包括 #if 、 #ifdef 、 #elif 、 #else 、 #endif 等。
- 处理 #include 命令,将被包含文件的内容插入到该命令所在的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还会包含其他的文件。
- 删除所有的注释,包括 // 和 /.../ 。
- 添加行号和文件名标识,便于在调试和出错时给出具体的代码位置。
- 由于编译器的需要,预处理阶段会保留所有的 #pragma 命令。
总的来说,预处理主要是进行宏的替换,例如 对文件包含#include 和预编译语句(如宏定义#define 等)进行处理,需要包含的进行包含,需要展开的宏进行展开等,所以在后续进行编译的时候是没有 include 和 define 的,所以 .i 文件里都是一些库函数的声明。 可理解为把头文件的代码、宏之类的内容转换成更纯粹的 C 代码,不过生成的文件以 .i 为后缀。
1.3 预处理的结果
预处理的结果是生成 .i 文件, .i 文件是包含 C 语言代码的源文件,只不过在此文件中所有的宏已经被展开,所有包含的文件已经被插入到当前文件中。可以看这个文件:LV01_GCC_COMPILE/00_compile/01_monofile/test.i
文件中以“#”开头的是注释,可看到有非常多的类型定义、函数声明被加入到文件中, 这些就是预处理阶段完成的工作,相当于它把原 C 代码中包含的头文件中引用的内容汇总到一处。 如果原 C 代码有宏定义,还可以更直观地看到它把宏定义展开成具体的内容(如宏定义代表的数字)。
2. 编译( Compiling )
编译就是把预处理完的文件进行一些列的词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。编译是整个程序构建的核心部分,也是最复杂的部分之一。
由于比较复杂,而且对我来说不是关注重点,这里就简单介绍,不再详写了。毕竟就这一部分的东西就有一本叫《编译原理》的书来详细解释了 😂。
2.1 编译的命令
gcc -S test.i -o test.s
# 或者也可以由源文件直接得到
gcc -S test.c -o test.s2.2 编译做了什么?
这个阶段编译器主要做词法分析、语法分析、语义分析等,在检查无错误后后,把代码翻译成汇编语言,生成 .s 文件。 在这个过程,即使我们调用了一个没有定义的函数,也不会报错。
2.3 编译的结果
编译的结果就是生成汇编文件, GCC 中它以 .s 为后缀名,其他编译器下可能以 .asm 为后缀。可以看这个文件:LV01_GCC_COMPILE/00_compile/01_monofile/test.s
汇编语言是跟平台相关的,由于本示例的 GCC 目标平台是 x86,所以此处生成的汇编文件是 x86 的汇编代码。
3. 汇编( Assembling )
汇编的过程就是将汇编代码转换成可以执行的机器指令。
3.1 汇编的命令
gcc -c test.s -o test.o3.2 汇编做了什么?
汇编器 as 将 汇编语言文件翻译成机器语言。这一步是由汇编文件生成目标文件.o 文件,每一个源文件都对应一个目标文件。GCC 的参数“c”表示只编译(compile)源文件但不链接,会将源程序编译成目标文件(.o 后缀)。计算机只认识 0 或者 1,不懂得 C 语言,也不懂得汇编语言,经过编译汇编之后,生成的目标文件包含着机器代码,这部分代码就可以直接被计算机执行。
3.3 汇编的结果
汇编的结果是产生目标文件,这个文件是二进制文件。它在 GCC 下的后缀为 .o ,在 其他编译器下的后缀可能为 .obj。可以看这个文件:LV01_GCC_COMPILE/00_compile/01_monofile/test.o
*.o 是为了让计算机阅读的,所以不像前面生成的 *.i 和*.s 文件直接使用字符串来记录, 如果直接使用编辑器打开,只会看到乱码。Linux 下生成的*.o 目标文件、*.so 动态库文件以及链接阶段生成最终的可执行文件都是 elf 格式的, 可以使用“readelf”工具来查看它们的内容。
readelf -a test.o然后我们可以看到如下内容:LV01_GCC_COMPILE/00_compile/01_monofile/test.o.txt:

从 readelf 的工具输出的信息,可以了解到目标文件包含 ELF 头、程序头、节等内容, 对于*.o 目标文件或*.so 库文件,编译器在链接阶段利用这些信息把多个文件组织起来, 对于可执行文件,系统在运行时根据这些信息加载程序运行。
4. 链接( Linking )
目标文件已经是二进制文件,与可执行文件的组织形式类似,但是有些函数和全局变量的地址还未找到,程序此时还不能直接执行。链接的作用就是找到那些目标地址,将 所有的目标文件组织成一个可以执行的二进制文件。
4.1 链接的命令
gcc test.o -o test最后将每个源文件对应的.o 文件以及各种库链接起来,生成一个可执行程序文件,得到最终的可执行文件。
4.2 链接做了什么?
这里只有一个 test.c 文件,但它调用了 C 标准代码库的 printf 函数, 所以链接器会把它和 printf 函数链接起来,生成最终的可执行文件。
还会有多个文件的情况,例如一个工程里包含了 A 和 B 两个代码文件,编译后生成了各自的 A.o 和 B.o 目标文件, 如果在代码 A 中调用了 B 中的某个函数 fun,那么在 A 的代码中只要包含了 fun 的函数声明, 编译就会通过,而不管 B 中是否真的定义了 fun 函数(当然,如果函数声明都没有,编译也会报错)。 也就是说 A.o 和 B.o 目标文件在编译阶段是独立的,而在链接阶段, 链接过程需要把 A 和 B 之间的函数调用关系理顺,也就是说要告诉 A 在哪里能够调用到 fun 函数, 建立映射关系,所以称之为 链接。若链接过程中找不到 fun 函数的具体定义,则会链接报错。
Tips:链接(Link)其实就是一个“打包”的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker)。
4.3 链接的结果
链接的结果是产生可执行文件,这个文件是二进制文件。它在 GCC 下默认的名称为 a.out ,在其他编译器下的后缀可能为 .exe 。
4.4 链接的分类
链接分为两种:
- 动态链接,GCC 编译时的默认选项。动态是指在应用程序运行时才去加载外部的代码库, 例如 printf 函数的 C 标准代码库*.so 文件存储在 Linux 系统的某个位置, hello 程序执行时调用库文件*.so 中的内容,不同的程序可以共用代码库。 所以动态链接生成的程序比较小,占用较少的内存。
- 静态链接,链接时使用选项“–static”,它在编译阶段就会把所有用到的库打包到自己的可执行程序中。 所以静态链接的优点是具有较好的兼容性,不依赖外部环境,但是生成的程序比较大。
我们可以看一下两者的区别:
# test.o 所在的目录执行如下命令
# 动态链接,生成名为 test 的可执行文件
gcc test.c -o test_dynamic # 直接使用 C 文件一步生成,与上面的命令等价
# 静态链接,使用--static 参数,生成名为 hello_static 的可执行文件
gcc test.c -o test_static --static # 也可以直接使用 C 文件一步生成,与上面的命令等价
从图中可以看到,使用动态链接生成的程序才 12KB, 而使用静态链接生成的程序则高达 828KB。在 Ubuntu 下,可以使用 ldd 工具查看动态文件的库依赖,尝试执行如下命令:
# 在 test 所在的目录执行如下命令
ldd test_dynamic
ldd test_static
可以看到,动态链接生成的 test_dynamic 程序依赖于库文件 linux-vdso.so.1、libc.so.6 以及 ld-linux-x86-64.so.2,其中的 libc.so.6 就是我们常说的 C 标准代码库, 我们的程序中调用了它的 printf 库函数。静态链接生成的 test_static 没有依赖外部库文件。
三、目标文件和可执行文件
上边我们看到最后生成的有目标文件和可执行文件,它们都是二进制文件,那么它们的组织形式是怎样的呢?
1. 文件格式
现在 PC 平台上流行的可执行文件格式主要有两种,一种是 Windows 下的 PE ( Portable Executable )和,另一种是 Linux 下的 ELF ( Executable Linkable Format ),它们都是 COFF ( Common File Format )格式的变种。
COFF 是 Unix V3 首先提出的规范,微软在此基础上制定了 PE 格式标准,并将它用于 Windows。后来 Unix V4 又在 COFF 的基础上引入了 ELF 格式,被 Linux 广泛使用。所以 Windows 和 Linux 上的可执行文件非常相似。
其中目标文件与可执行文件的存储格式几乎是一样的,我们可以将它们看成是同一种类型的文件,在 Windows 下,它们统称为 PE 文件,在 Linux 下,将它们统称为 ELF 文件。
2. 目标文件
整体上看,编译生成的目标文件被划分成了多个部分,每个部分叫做一个 段( Section )。在 Linux 中 GCC 生成的目标文件的格式如下:

【说明】
(1)段名大都以 . 作为前缀,表示这些名字是系统保留的。
(2)除了上边系统保留的段名,应用程序也可以使用其它名字定义自己的段,应用程序自定义的的段不建议使用 . 作为前缀,否则容易和系统保留段发生冲突。例如,在在 ELF 文件中插入一个名为 music 的段来保存 MP3 音频数据。
(3)图中仅列出一些关键的段名称,还有一些隐藏在 Other Data 也就是其他数据中。下表是各部分说明:
| 段名 | 说明 |
| ELF Header | 文件头,描述了整个目标文件的属性,包括是否可执行、是动态链接还是静态链接、入口地址、目标硬件、目标操作系统、段表偏移等信息。 |
| .text | 代码段,存放编译后的机器指令,也即各个函数的二进制代码。 |
| .data | 数据段,存放全局变量和静态变量。 |
| .rodata | 只读数据段,存放一般的常量、字符串常量等。 |
| .rel.text .rel.data | 重定位段,包含了目标文件中需要重定位的全局符号以及重定位入口。 |
| .comment | 注释信息段,存放的是编译器的版本信息,比如 GCC:(GUN) 4.2.0 。 |
| .debug | 调试信息。 |
| .line | 调试时的行号表,就是源代码行号与编译后指令的对应表。 |
| Section Table | 段表,描述了 ELF 文件包含的所有段的信息,比如段的名字、段的长度、在文件中的偏移、读写权限以及其他属性。可以说,ELF 文件的段结构是由段表来决定的,编译器、链接器和装载器都是依靠段表来定位和访问各个段的。 |
| .strtab | 字符串表,保存了 ELF 文件用到的字符串,比如变量名、函数名、段名等。因为字符串的长度往往是不定的,所以用固定的结构来表示它比较困难,常见的做法就是把字符串集中起来存放到一个表中,然后使用字符串在表中的偏移来引用字符串。 |
| .symtab | 符号表,保存了全局变量名、局部变量名、函数名等在字符串表中的偏移。 |
3. 可执行文件
可执行文件与目标文件的组织形式非常类似,在 Linux 中 GCC 生成的目标文件的格式如下:

【说明】
(1)图中仅列出一些关键的段名称,还有一些隐藏在 Other Data 也就是其他数据中。
(2)红色字体为相对于目标文件,可执行文件新增的一些段,画有删除线的是可执行文件删除的一些段。
(3)右侧为 32 位环境的 Linux 内存模型。
(4)可执行文件在加载时实际上是被映射的虚拟地址空间,所以可执行文件很多时候又被叫做 映像文件( Image )。
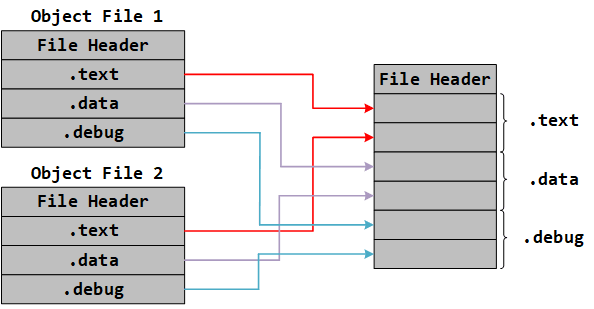
4. 段合并
编译器生成的是目标文件,而我们最终需要的是可执行文件,链接( Linking )的作用就是将多个目标文件合并成一个可执行文件。在链接过程中,链接器会将多个目标文件中的代码段、数据段、调试信息等合并成可执行文件中的一个段,链接器还会删除多余的段(例如重定位段、段表等),增加其他段(例如程序头表等)。
段的合并仅仅是一个简单的叠加过程,如下图所示。