
LV005-内存管理简介
本文主要是 C 语言基础——内存管理简介相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正 😃。
内存的使用是程序设计中需要考虑的重要因素之一,这不仅由于系统内存是有限的(尤其在嵌入式系统中),而且内存分配也会直接影响到程序的效率。
一、内存空间
1. 四个内存区间
在 C 语言中,定义四个内存区间:代码区、数据区、栈区和堆区。
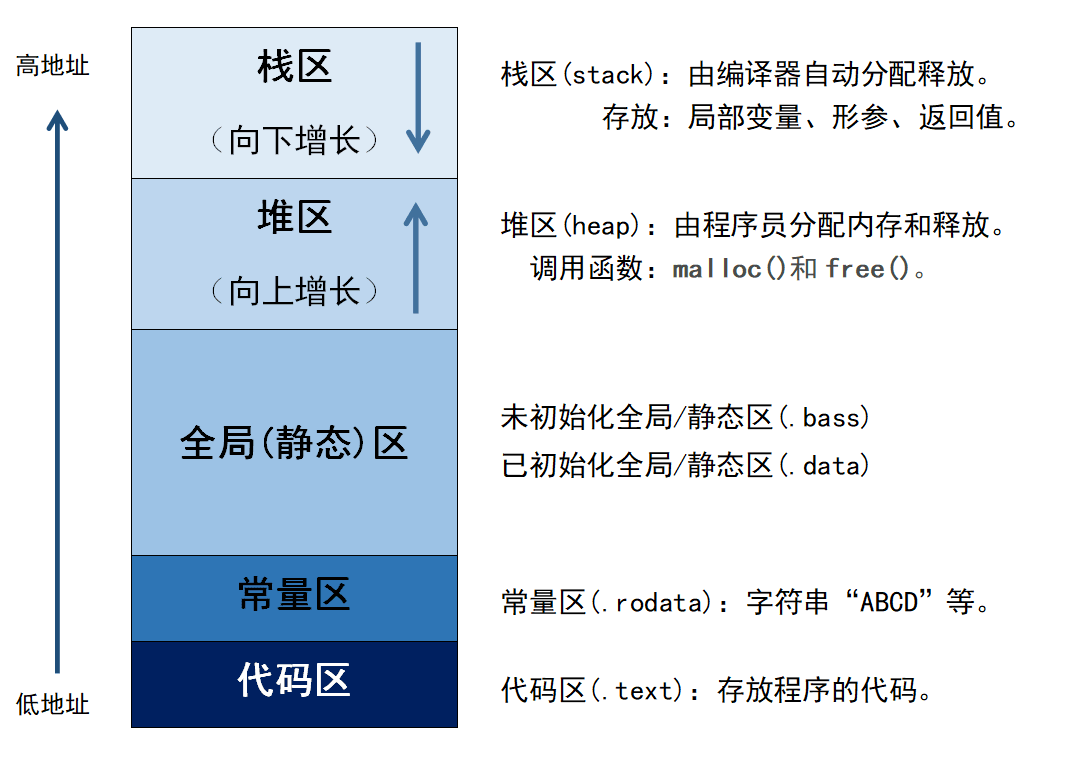
Tips:经典的教学模型常说是“四个区间”,但在现代操作系统(如 Linux 下的 ELF 文件格式)中,内存布局通常被更细致地划分为 5 段:代码段、数据段(.data)、BSS 段(.bss)、堆、栈。其中“数据段”和 " BSS 段”合起来对应上述四区间模型中的“数据段”或“全局/静态存储区”。
1.1 代码区
程序被操作系统加载到内存的时候,所有的可执行代码(程序代码指令、常量字符串等)都加载到代码区,这块内存在程序运行期间是不变的(属性是只读的)。
函数也是代码的一部分,故函数都被放在代码区,包括 main 函数。
Tips:int a = 0; 语句可拆分成 int a; 和 a = 0 ,定义变量 a 的 int a; 语句并不是代码,它在程序编译时就执行了,并没有放到代码区,放到代码区的只有 a = 0 这句。
1.2 全局/静态存储区
静态存储区存放的是全局变量与静态变量( static 修饰),也可以叫做全局变量与静态变量区。在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如:全局变量、静态变量和字符串常量。
分配在这个区域中的变量,当程序结束时,才释放内存。因此,经常利用这样的变量,在函数间传递信息。
1.3 栈区
栈区,也就是局部变量区。栈( stack )是一种 先进后出 的内存结构,所有的自动变量、函数形参都存储在栈中,这个动作由编译器自动完成,我们写程序时不需要考虑。
栈区在程序运行期间是可以随时修改的。当一个自动变量超出其作用域时,会自动从栈中弹出。
在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
在 linux 中,可以通过命令 ulimit -s 来查看栈的大小,执行完命令后,在终端会显示:
8192这说明我执行这条命令的系统中栈的容量为 8192kbytes ,也就是 8MB 。
【注意】
(1)不能将一个栈变量的地址通过函数的返回值返回。
(2)这种内存方式,变量内存的分配和释放都是自动进行,我们编写代码的时候不需要考虑内存管理的问题,很方便,但是栈的容量有限,且相应的范围结束时,局部变量就不能再使用。
1.4 堆区
堆区,也就是动态存储区。堆( heap )和栈一样,也是一种在程序运行过程中可以随时修改的内存区域。
有的操作对象只有在程序运行时才能确定,这样在编译器进行编译的时候就无法为他们预先分配空间,只能在程序运行时进行分配,所以称为动态分配内存。
而所有动态存储分配都在堆区中进行的。所以从堆上分配,亦称动态内存分配。l 程序在运行的时候用 malloc 申请任意多少的内存,我们自己负责在何时用 free 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
2. 堆与栈的区别
2.1 申请方式
栈( stack )是由系统自动分配的。例如我们声明了一个局部变量 int b; 那么系统会自动在栈区为 b 开辟空间。
堆( heap )需要我们自己去申请,并在申请时指定大小。
2.2 申请后系统响应
堆在操作系统中有一个记录空闲内存地址的链表。当系统收到程序的申请时,系统就会开始遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小。这样,代码中的删除语句才能正确地释放本内存空间。如果找到的堆节点的大小与申请的大小不相同,系统会自动地将多余的那部分重新放入空闲链表中。
只有栈的剩余空间大于所申请空间,系统才为程序提供内存,否则将报异常,提示栈溢出。
2.3 速度限制
堆是由 malloc 等函数分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来很方便。
栈由系统自动分配,速度较快,但我们一般无法控制。
2.4 大小限制
堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统用链表来存储的空闲内存地址,地址是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存,因此堆获得的空间比较灵活,也比较大。 栈是向低地址扩展的数据结构,是一块连续的内存区域。因此,栈顶的地址和栈的最大容量是系统预先规定好的,如果申请的空间超过栈的剩余空间时,将提示栈溢出,因此,能从栈获得的空间较小。
2.5 堆和栈中的存储内容
堆一般在堆的头部用一个字节存放堆的大小,堆中的具体内容由我们自己安排。
在调用函数时,第一个进栈的是函数调用语句的下一条可执行语句的地址,然后是函数的各个参数,在大多数的 C 语言编译器中,参数是由右往左入栈的,然后是函数中的局部变量。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始的存储地址,也就是调用该函数处的下一条指令,程序由该点继续运行。
3. 为什么分这么多段?
那么,代码和数据为什么是分开存放的?在 C 语言编译生成的可执行文件(如 Linux 下的 ELF 或 Windows 下的 PE 格式)中,代码(指令)和数据分开存放,主要是出于 安全性、内存效率、性能优化 以及 操作系统管理 的考虑。
3.1 内存保护与安全(Memory Protection & Security)
这是最重要的原因之一。不同的段拥有不同的 访问权限,防止程序出错或恶意攻击。
- 代码段只读:指令通常被标记为“只读”和“可执行”。这防止了程序意外修改自身的指令(导致崩溃),也增加了病毒或黑客修改程序逻辑的难度。
- 数据不可执行:现代操作系统通常支持 NX 位(No-Execute) 或 DEP(数据执行保护)。这意味着栈和堆中的数据段不能被当作代码执行。这能有效防止“缓冲区溢出攻击”(黑客无法将恶意代码注入栈中并诱骗 CPU 执行)。
- 隔离风险:如果栈溢出,它通常会向堆的方向增长,而不是覆盖代码段。分段增加了不同区域间的隔离性,减少了一个区域的错误导致整个程序立即崩溃的概率。
3.2 生命周期管理(Lifecycle Management)
不同类型的数据存在的时间长短不同,需要不同的管理策略。
- 栈(Stack):管理 临时数据。函数调用时自动分配,返回时自动释放。这种自动化管理效率极高,适合局部变量。
- 堆(Heap):管理 动态数据。程序员手动分配和释放,适合大小不确定或需要长期存活的数据(如动态数组、链表)。
- 全局/静态区(Data/BSS):管理 持久数据。程序启动时分配,结束时释放。适合全局配置、单例对象等。
- 分开的好处:如果所有数据都混在一起,编译器就无法自动回收局部变量内存,程序员也无法灵活控制大内存的生命周期。
3.3 资源复用与效率(Resource Sharing & Efficiency)
分段有利于操作系统优化物理内存的使用。
- 代码共享:如果多个进程运行同一个程序(例如打开了多个记事本窗口),操作系统可以让它们 共享同一个代码段 的物理内存。因为代码段是只读的,不会被某个进程修改而影响其他进程。这极大地节省了内存。
- BSS 段优化:未初始化的全局变量放在 BSS 段。它们在程序文件中不占实际空间(只记录大小),只有在程序运行时才分配内存并清零。这减小了可执行文件的体积,加快了加载速度。
3.4 内存空间利用最大化(Memory Utilization)
- 相对生长:在经典的内存模型中,栈向低地址增长,堆向高地址增长。这种“相向而行”的设计使得中间的空闲内存区域可以被灵活利用。如果堆用多了,栈就少用点;反之亦然。如果不分段,固定划分大小,很容易出现“一边内存耗尽,另一边却大量闲置”的浪费情况。
3.5 调试与维护(Debugging & Maintenance)
- 错误定位:当程序崩溃时,分段有助于定位问题。
- 如果是 栈溢出(Stack Overflow),通常是递归太深或局部数组太大。
- 如果是 段错误(Segmentation Fault),可能是访问了空指针或越界。
- 如果是 内存泄漏(Memory Leak),通常是堆内存忘了释放。
- 清晰的内存布局让开发者更容易理解程序的状态,也方便调试工具(如 Valgrind、GDB)进行分析。
4. 小结
其实我们知道,C 语言程序经过编译链接后形成的二进制映像文件由 栈,堆,数据段(由三部分部分组成:只读数据段,已经初始化读写数据段,未初始化数据段即 BBS)和 代码段 组成。前面已经说明了:
| 内存区域 | 管理方式 | 存放内容 | 详细说明 |
|---|---|---|---|
| 栈区 (stack) | 编译器自动分配释放 | 函数的参数值、局部变量等 | 又叫堆栈,先进后出,操作方式类似于数据结构中的栈 |
| 堆区 (heap) | 程序员分配释放(若不释放可能引起内存泄漏) | 动态分配的内存 | 与数据结构中的堆栈不一样,其类似于链表 |
| 程序代码区 | 系统管理 | 函数体的二进制代码 | 存放程序执行的指令 |
| 数据段 | 只读 | const 修饰的变量、文字常量 | 只读数据段,不会被更改,使用这些数据的方式类似查表式的操作,放置在只读存储器中 |
| 可读写 | 已初始化的全局变量、已初始化的静态局部变量 | 已初始化的读写数据段,在程序执行时它们需要位于可读写的内存区域内,并且有初值,以供程序运行时读写。 | |
| 可读写(运行初始化阶段产生) | 未初始化的全局变量、未初始化的静态局部变量 | 未初始化段(BSS),与读写数据段类似,它也属于静态数据区。但是该段中数据没有经过初始化。未初始化数据段只有在运行的初始化阶段才会产生,运行前不占用存储器空间,因此它的大小不会影响目标文件的大小。 |
二、动态内存分配
1. 堆内存的分配与释放
当程序运行到需要一个动态分配的变量或对象时,必须向系统申请取得堆中的一块所需大小的存储空间,用于存储该变量或对象。
当不再使用该变量或对象时,也就是它的生命结束时,要 显式释放它所占用的存储空间,这样系统就能对该堆空间进行再次分配,做到重复使用有限的资源。
【注意】 堆区是不会自动在分配时做初始化的(包括清零),所以必须用初始化式( initializer )来显式初始化。
2. 内存申请函数
2.1 malloc()
C 语言中使用 malloc 函数来申请内存,在 linux 中可以使用 man 3 malloc 命令查看该函数的手册,函数原型如下:
/* 头文件 */
#include <stdlib.h>
/* 函数声明 */
void *malloc(size_t size);;【函数说明】 动态申请 size 字节的内存空间。函数是如何完成分配的?后续学习操作系统相关知识会学习。
【函数参数】
- size : size_t 类型,表示需要动态申请的内存的字节数。
【返回值】 void * 类型,若内存申请成功,函数返回申请到的内存的起始地址;若申请失败,则返回 NULL 。
【注意】
(1)该函数只关注申请内存的大小,单位是字节。
(2)该函数申请到的内存区域是连续的,申请到的内存可能会比实际申请的大。也有可能会申请不到,所以一定要写一个申请是否成功的判断。
(3)返回值是 void *类型,不是某种具体类型的指针,也就是说,这个函数只负责申请内存,对在内存中存储什么类型的数据没有任何要求。所以一般使用的时候,需要根据实际情况将 void* 强制转换成所需要的指针类型。
(4)堆区不会自动在分配时做初始化(包括清零),也就是说内存空间在函数执行完成后不会被初始化,它们的值是未知的,所以 程序中一定要做显式的初始化。
2.2 calloc()
C 语言中的 calloc 函数也可以用于申请内存,在 linux 中可以使用 man 3 calloc 命令查看该函数的手册,函数原型如下:
/* 头文件 */
#include <stdlib.h>
/* 函数声明 */
void *calloc(size_t nmemb, size_t size);【函数说明】 在内存中动态地分配 nmemb 个长度为 size 的 连续空间,并将每一个字节都初始化为 0 。
【函数参数】
- nmemb : size_t 类型,表示需要申请多少个内存空间。
- size : size_t 类型,表示申请的内存空间的长度。
【返回值】 void * 类型,分配成功返回指向该内存的地址,失败则返回 NULL 。
【注意】
(1) calloc 与 malloc 的一个重要区别是: calloc 在动态分配完内存后,自动初始化该内存空间为零,而 malloc 不初始化,里边数据是未知的垃圾数据。下面的两种写法是等价的:
/* 1.calloc() 分配内存空间并初始化 */
char *str1 = (char *)calloc(10, 2);
/*2. malloc() 分配内存空间并用 memset() 初始化 */
char *str2 = (char *)malloc(20);
memset(str2, 0, 20);(2)同样是使用 free 函数来释放申请的内存。
2.3 realloc()
C 语言中的 realloc 函数用于重新分配内存空间,在 linux 中可以使用 man realloc 命令查看该函数的手册,函数原型如下:
/* 头文件 */
#include <stdlib.h>
/* 函数声明 */
void *realloc(void *ptr, size_t size);【函数说明】 尝试重新调整之前调用 malloc 或 calloc 所分配的 ptr 所指向的内存块的大小。
【函数参数】
- ptr : void * 类型,表示需要重新分配的内存空间指针。
- size : size_t 类型,表示新的内存空间的大小。
【返回值】 void * 类型,分配成功返回新的内存地址,可能与 ptr 相同,也可能不同;失败则返回 NULL 。
【注意】
(1)指针 ptr 必须是在动态内存空间分配成功的指针,形如如下的指针是不可以的: int *i; int a [2]; 会导致运行时错误,可以简单的这样记忆:用 malloc() 、 calloc() 、 realloc() 分配成功的指针才能被 realloc() 函数接受。
(2)成功分配内存后 ptr 将被系统回收,一定不可再对 ptr 指针做任何操作,包括 free(); ,相反的,可以对 realloc() 函数的返回值进行正常操作。
(3)如果是扩大内存操作,若当前内存段后面有需要的内存空间,则直接扩展这段内存空间, realloc() 将返回原指针(但 依旧不能对原指针进行任何操作)。若当前内存段后面的空闲字节不够,那么就使用堆中的第一个能够满足这一要求的内存块,会把 ptr 指向的内存中的数据复制到新地址;如果是缩小内存操作,原始据会被复制并截取新长度。
(4)如果分配失败,函数会返回 NULL ,但是 ptr 指向的内存不会被释放,它的内容也不会改变,依然可以正常使用。
(5)同样是使用 free 函数来释放申请的内存。
3.内存释放函数
3.1 free()
C 语言中使用 free 函数来释放申请的内存,在 linux 中可以使用 man 3 free 命令查看该函数的手册函数原型如下:
/* 头文件 */
#include <stdlib,h>
/* 函数声明 */
void free(void *ptr);【函数说明】 释放动态申请的内存区域,它时需要提供内存区域的起始地址就可以了,那他怎么知道要释放多少字节的内存空间?后面学习操作系统相关内容的时候会学习。
【函数参数】
- ptr :表示需要释放的内存的起始地址。
【返回值】 无
【注意】
(1)必须提供内存的起始地址,不能提供一个部分地址,释放内存中的一部分是不允许的。因此,我们必须保存好 malloc 函数返回的指针值,若丢失,则所分配的堆空间就无法被回收,这被称为 内存泄漏。
(2) malloc 和 free 成对使用,编译器不负责动态内存的释放,需要我们自己进行释放。
(3)释放内存时,不允许重复释放。同一空间的重复释放也是很危险的,如果该空间重新分配了,那将导致不可知的问题。
(4) free 只释放堆区空间,像代码区、全局变量与静态变量区以及栈区上的变量,都不需要我们显式的去释放,而且也不能通过 free 函数来释放,否则可能会出错。
(5)free(p) 并不能改变指针 p 的值,p 依然指向以前的内存,为了防止再次使用该内存,建议将 p 的值手动置为 NULL。
3. 内存分配实例
#include <stdio.h>
#include <stdlib.h>
int main(int argc, const char *argv[])
{
char *p;
p = (char *)malloc(10*sizeof(char));
if(p == NULL)
{
printf("malloc failed\n");
return 0;
}
printf("p = %p\n",p);
printf("Please input a string:");
scanf("%s",p);
printf("The string is: %s\n",p);
free(p);
return 0;
}在终端执行以下命令:
gcc test.c -Wall # 编译程序
./a.out # 执行可执行文件会看到有如下信息输出:
p = 0x559952fbb260
Please input a string:fanhua
The string is: fanhua三、内存布局
上边了解了堆和栈的相关知识,但是 C 语言程序在内存中究竟是怎样的呢?我们常在 linux 下进行 C 语言程序设计,那么接下来就看一看 Linux 下的一种经典内存布局吧。
1. 32 位 Linux
对于 32 位环境,理论上程序可以拥有 4GB 的虚拟地址空间,我们在 C 语言中使用到的变量、函数、字符串等都会对应内存中的一块区域。但是,在这 4GB 的地址空间中,有一部分是给操作系统内核使用的,应用程序无法直接访问这一段内存,这一部分内存地址被称为 内核空间( Kernel Space )。 Windows 在默认情况下会将高地址的 2GB 空间分配给内核(也可以配置为 1GB ),而 Linux 默认情况下会将高地址的 1GB 空间分配给内核。应用程序便只能使用剩下的 2GB 或 3GB 的地址空间,称为 用户空间( User Space )。
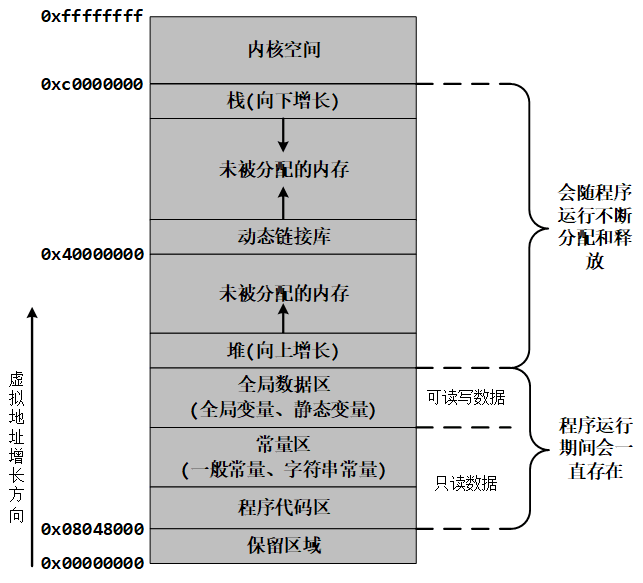
| 内存分区 | 说明 |
| 程序代码区 (code) | 存放函数体的二进制代码。 |
| 常量区 (constant) | 存放一般的常量、字符串常量等。这块内存只有读取权限,没有写入权限,因此它们的值在程序运行期间不能改变。 |
| 全局数据区 (global data) | 存放全局变量、静态变量等。这块内存有读写权限,因此它们的值在程序运行期间可以任意改变。 |
| 堆区 (heap) | 一般由我们自己分配和释放,若我们不释放,程序运行结束时由操作系统回收。malloc()、calloc()、free() 等函数操作的就是这块内存。注意:这里所说的堆区与数据结构中的堆不是一个概念,但是堆区的分配方式类似于链表。 |
| 动态链接库 | 用于在程序运行期间加载和卸载动态链接库。 |
| 栈区 (stack) | 存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。 |
2. 64 位 Linux
在 64 位环境下,虚拟地址空间大小为 256TB , Linux 将高 128TB 的空间分配给内核使用,而将低 128TB 的空间分配给用户程序使用。
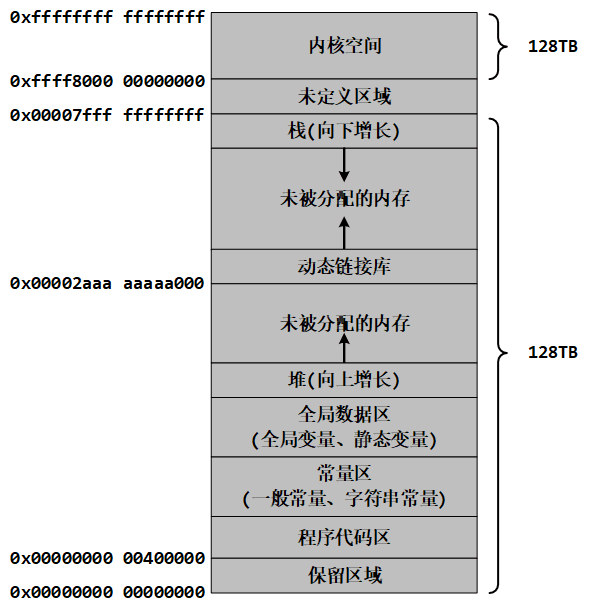
【说明】在 64 位环境下,虚拟地址虽然占用 64 位,但只有最低 48 位有效。任何虚拟地址的 48 位至 63 位必须与 47 位一致。在上图中,用户空间地址的 47 位是 0 ,所以高 16 位也是 0 ,换算成十六进制形式,最高的四个数都是 0 ;内核空间地址的 47 位是 1 ,所以高 16 位也是 1 ,换算成十六进制形式,最高的四个数都是 1 。这样中间的一部分地址正好空出来,也就是图中的“未定义区域”,这部分内存无论如何也访问不到。
四、一个易错点
1. 代码与现象
有这样一段代码,运行后会报段错误:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
void get_memory(char *p)
{
p = (char *)malloc(100);
strcpy(p, "hello world!");
printf("p = %s\n", p);
}
#include <stdio.h>
int main(int argc, char *argv[])
{
char *str = NULL;
get_memory(str);
printf("str = %s\n", str);
printf("%s\n", str);
free(str);
return 0;
}我们编译,然后运行程序,会的到下边的信息:
p = hello world!
str = (null)
段错误 (核心已转储)会发现,我们直打印 str 指向的数据的时候,直接报了一个段错误,但是这里其实还有一个疑问,就是 printf 使用 str = %s 来打印 str 指向的数据的时候就没有报段错误,自己没查到相关资料,暂时先记录一下,后边搞定了再补充笔记,本次的重点是段错误问题。
2. 错误分析
2.1 get_memory() 调用情况
在 main 函数中,我们穿建了一个指针变量 str ,并初始化为空,然后调用了一个 get_memory 函数,我们传入了 str ,我们传进去的地址嘛?还是说这是一个值传递,其实这里我是有点迷糊的,因为平时我们可以用函数形参中的指针来接收数组的地址,但是传入一个指针变量的时候,就有些迷了。(可以先看一下这篇笔记《01-编程语言/01-C语言/18-函数/LV007-参数传递.md》,里边有写字符串指针变量在传参的时候的赋值情况)
不过,我们可以打印出来看看啊,看一看进去的到底是个地址还是什么,前边我们知道 printf 直接打印空指针的话会报段错误,但是加上一些修饰的字符串的话,即便是空,我们也可以打印出来:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
void get_memory(char *p)
{
printf("&p=%p, p=%s, p=%p\n", &p, p, p);
p = (char *)malloc(100);
printf("开辟内存后:");
printf("&p=%p, p=%s, p=%p\n", &p, p, p);
strcpy(p, "hello world!");
printf("p = %s\n", p);
}
int main(int argc, char *argv[])
{
char *str = NULL;
printf("&str=%p, str=%s, str=%p\n", &str, str, str);
get_memory(str);
printf("str = %s\n", str);
printf("%s\n", str);
free(str);
return 0;
}编译运行的话,然后我们会得到以下输出:
&str=0x7ffd845d6140, str=(null), str=(nil)
&p=0x7ffd845d6118, p=(null), p=(nil)
开辟内存后:&p=0x7ffd845d6118, p=, p=0x23d2420
p = hello world!
str = (null)
段错误 (核心已转储)【说明】打印出来的 nil 表示地址为空。
会发现,我是我们是将 str 指向的值传递给了 p ,其实分析一下也就是这样的,传参的时候是这样的
char *p;
p = str;2.2 分配内存前
有上边的打印情况,我们分配内存之前的情况如下图:

这个时候 p 和 str 都是 null ,可以说是没有任何关系。
2.3 分配内存后
有上边的打印情况,我们分配内存之后的情况如下图:
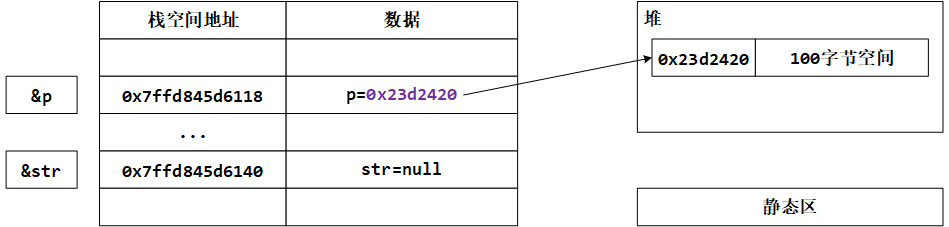
这个时候 p 和 str 都是 null ,可以说是没有任何关系。
2.4 get_memory() 调用结束
这个函数调用结束后, p 指针变量销毁,没有指针变量指向这片内存区域,就导致了内存泄漏。

而此时 str 依然是 null ,也就是说,整个程序运行期间, p 和 str 其实在传参后,就没有任何关系了, str 仅仅将自己的 null 传给了 p ,之后两者再无任何联系,所以 str 一直都是 null ,所以后边访问空地址才会发生段错误。
3. 程序修改
3.1 方式 1
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
void *get_memory(char *p)
{
p = (char *)malloc(100);
strcpy(p, "hello world!");
printf("p = %s\n", p);
return p;
}
int main(int argc, char *argv[])
{
char *str = NULL;
printf("&str=%p, str=%s, str=%p\n", &str, str, str);
str = get_memory(str);
printf("str = %s\n", str);
printf("%s\n", str);
free(str);
return 0;
}这样,编译运行之后,我们就会得到想要的结果啦:
&str=0x7ffea0ee9a90, str=(null), str=(nil)
p = hello world!
str = hello world!
hello world!3.2 方式 2
p 和 str 没有关系,我们创造关系,我们传一个二级指针进去:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
void get_memory(char **p)
{
printf("&p=%p,p=%p,*p=%p,*p=%s\n", &p, p, *p, *p);
*p = (char *)malloc(100);
printf("开辟内存后:\n");
printf("&p=%p,p=%p,*p=%p,*p=%s\n", &p, p, *p, *p);
strcpy(*p, "hello world!");
}
int main(int argc, char *argv[])
{
char *str = NULL;
printf("&str=%p, str=%s, str=%p\n", &str, str, str);
get_memory(&str);
printf("str = %s\n", str);
printf("%s\n", str);
free(str);
return 0;
}这一次二级指针变量 p 中存放的就是 str 的地址了,所以有:
*p = (char *)malloc(100);
// 等价于
str = (char *)malloc(100);我们会得到以下输出信息:
&str=0x7ffc1c5994a0, str=(null), str=(nil)
&p=0x7ffc1c599468,p=0x7ffc1c5994a0,*p=(nil),*p=(null)
开辟内存后:
&p=0x7ffc1c599468,p=0x7ffc1c5994a0,*p=0x20ed420,*p=
str = hello world!
hello world!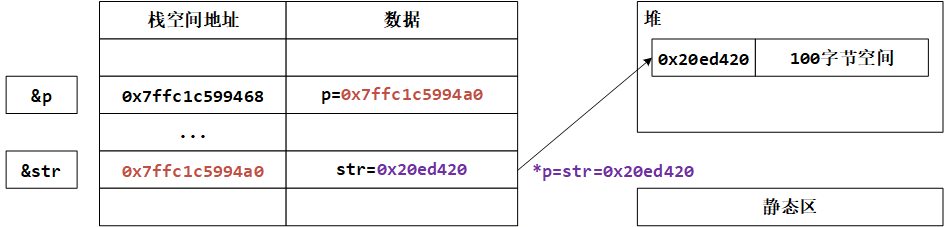
这样即使p在函数调用结束后被销毁,str依然指向从堆上申请的地址,这样就没问题了。要改变指针指向的地址,向函数传参的时候要传二级指针,也就是这个指针的地址进去,这样才能通过这个指针的地址访问到这个指针,然后让这个指针指向其他内存空间。
参考资料: