
LV050-系统调用简介
这一部分简单了解下系统调用。
一、内核态与用户态
早期工程师们在操作系统上编写程序的时候,自己写个程序可以访问别人的程序地址,甚至是操作系统占用的地址,这样就很容易一不小心就直接把操作系统给搞挂了,所以那个时候的程序员编写程序都得小心翼翼的。
计算机核心的资源一般有:内存,I/O 端口,特殊机器指令等,这些资源必须得保护起来,规定哪些程序可以去访问,哪些程序不能去访问。所以引入了 特权级别 的概念,由硬件设备商直接来提供硬件级别的支持,最常见的就是给 CPU 指令集的权限分级 来控制 CPU 的访问权限。比如 Intel CPU 指令集操作的权限由高到低划为 4 级:Ring0、Ring1、Ring2、Ring3,其中 Ring0 权限最高,可以使用所有 CPU 指令集,Ring3 权限最低,仅能使用部分 CPU 指令,比如不能使用操作硬件资源的 CPU 指令:I/O 操作、内存分配等操作;另外 CPU 处于 Ring3 状态不能访问 Ring0 的地址空间,包括 代码和数据。
CPU 指令集,就是 CPU 中用来计算和控制计算机系统的一套指令的集合,实现软件指挥硬件执行的媒介,常见的 CPU 指令集有 X86、ARM、MIPS、Alpha、RISC 等。
那么 CPU 是如何记录这些特权级信息的?
我们这里以 80386CPU 为例,我们知道 CPU 里面有许多段寄存器(CS、DS、SS、ES、FS、GS 等)。这些段寄存器里面存放 段选择符(也叫段选择子):

段选择符中包含请求特权级 RPL(CPL)字段,通过段选择符可以去查找全局描述符表 GDT、局部描述符表 LDT 中对应的项,需要先进行 特权级检查;这些项中都包含 DPL 字段(规定访问该段的权限级别),只有 DPL >= max {CPL, RPL},才允许访问。
CPL 很特殊,跟踪当前 CPU 正在执行的代码所在段的描述符中 DPL 的值,总是等于 CPU 的当前特权级.
内核态与用户态 都是操作系统的层面的概念,和 CPU 硬件没有必然的联系;由于硬件已经提供了一套特权级使用的相关机制,Linux 操作系统没有必要重新 "造轮子",直接使用了硬件的 Ring0和Ring3 这两个级别的权限,也就是 使用 Ring3 作为用户态,Ring0 作为内核态。
那么为什么 Linux 系统仅使用了 Ring0和Ring3 这两个级别?
因为 CPU 给的权限管理细度不够,比如 Intel CPU 中 Ring2 和 Ring3 在操作系统里安全情况没有区别,Ring1 下的系统权限又需要经常调用 Ring0 特权指令,频繁切换特权级成本过高,操作系统不如将 Ring2 合并到 Ring3,将 Ring1 划入 Ring0 特权级。另一方面不是每种处理器都像 x86 一样支持 4 个权限级别,有些处理器可能只支持 2 个级别,更少的特权级别,便于移植其他处理器架构上。我们再来看下 linux 的体系架构图:
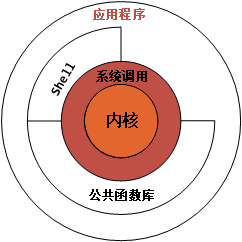
我们可以发现 Linux 系统从整体上看,被划分为 用户态和内核态:
- 内核态
内核态是处于操作系统的最核心处,Ring0 特权级,拥有操作系统的最高权限,能够控制所有的硬件资源,掌控各种核心数据,并且能够访问内存中的任意地址; 由内核态统一管理这些核心资源,减少有限资源的访问和使用冲突;在内核里发生的任何程序异常都是灾难性的,会导致整个操作系统的崩溃。
- 用户态
用户态,就是我们通常编写程序的地方,处于 Ring3 特权级,权限较低;这一层次的程序 没有对硬件的直接控制权限,也不能直接访问地址的内存。在这种模式下,即使程序发生崩溃也不会影响其他程序,可恢复。
二、什么是系统调用?
当计算机启动的时候,CPU 处于 Ring0 状态,这个时候所有的指令都可以执行,通过主引导程序将磁盘扇区中的操作系统程序加载到内存中,从而启动操作系统(需要注意一下,本文的操作系统 以 Linux0.12 为例子)。
当 Linux0.12 启动 的时候,是在权限最高级别的 内核态 运行的;同时对内存进行划分,划出一部分(内核区)专门给内核使用,这部分内存只能被内核使用;主内存区域给其他应用软件使用。

当操作系统启动完成后,CPU 就切换到 Ring3 级别上,操作系统同时进入用户态,之后的 应用程序代码 都运行在权限最低级别的 用户态 上,通常我们能编写的程序都运行在用户态上。
需要格外注意一下,CPU 特权级其实并不会对操作系统的用户造成什么影响!我们可能会和 Linux 的用户权限搞混淆,无论是根用户(root),管理员,访客还是一般用户,它们都属于用户;而所有的用户代码都在用户态 Ring3 上执行,所有的内核代码都在内核态 Ring0 上执行,和 Linux 用户的身份权限并没有关系!
因为我们编写的程序都运行在用户态上,是无法对内存和 I/O 端口的访问,可以说基本上无法与外部世界交互,但是我们平时工作的时候访问磁盘、写文件,这些都是必要的需求,怎么办?
那就需要通过执行 系统调用(system call),操作系统会切换到内核态,由内核去统一执行相关操作;当执行完操作系统再切换回用户态。这样方便集中管理,减少有限资源的访问和使用冲突。
系统调用 是操作系统专门为用户态运行的进程与硬件设备之间进行交互提供了一组接口(API),是用户态 主动 要求切换到内核态的一种方式, 是 Linux 应用层进入内核的入口。不止 Linux 系统,所有的操作系统都会向应用层提供系统调用,应用程序通过系统调用来使用操作系统提供的各种服务。
通过系统调用, Linux 应用程序可以请求内核以自己的名义执行某些事情,例如打开磁盘中的文件、读写文件、关闭文件以及控制其它硬件外设。通过系统调用 API,应用层可以实现与内核的交互,其关系可通过下图简单描述:

内核提供了一系列的服务、资源、支持一系列功能,应用程序通过调用系统调用 API 函数来使用内核提供的服务、资源以及各种各样的功能。
三、为什么要有系统调用?
其实前面学习系统调用概念的时候有提过,主要是计算机的各种 硬件资源是有限的,为了更好的管理这些资源,用户进程是不允许直接操作的,所有对这些资源的访问都必须由操作系统控制,也就是说操作系统是使用这些资源的唯一入口。为此 操作系统为用户态运行的进程与硬件设备之间进行交互提供了一组接口,这组接口就是所谓的系统调用。
在应用程序和硬件之间设置这样一个接口层有什么优点呢?
把用户从学习硬件设备的低级编程特性中解放出来。
系统调用保证了系统的稳定和安全。作为硬件设备和应用程序之间的中间环节,内核可以基于权限和其他一些规则对需要进行的访问进行裁决。比如这样就可以避免应用程序不正确地使用硬件设备,窃取其他进程的资源,或做出其他什么危害系统的事情。
最重要的是,这些接口使得程序更具有可移植性,因为只要不同操作系统所提供的一组接口相同,那么在这些操作系统上就可以正确的编译和执行相同的程序。
四、系统调用怎么实现的?
1. strace 命令
在 Linux 系统中,strace 命令是一个集诊断、调试、统计与一体的工具,可用来追踪调试程序,能够与其他命令搭配使用。Linux 系统管理员可以在不需要源代码的情况下即可跟踪系统的调用。官网在这里:strace
strace 命令会显示有关进程的系统调用的信息,这可以帮助确定一个程序使用的哪个函数,当然在系统出现问题时可以使用 strace 定位系统调用过程中失败的原因,这是定位系统问题的很好的方法。这里只是简单提一下,知道有这么个工具,后续排查问题可能会比较有效。
怎么安装移植?可以看这篇笔记:20-应用开发/90-第三方库移植/LV020-strace.md
2. 以库函数 write 为例
啊,没找到源码,参考下这个吧:linux-0.12/linux-0.12/lib/write.c at master · sumumm/linux-0.12 (github.com):
/*
* linux/lib/write.c
*
* (C) 1991 Linus Torvalds
*/
#define __LIBRARY__
#include <unistd.h>
_syscall3(int,write,int,fd,const char *,buf,off_t,count)write.c 这个文件主要是定义 write 的实现,_syscall3(*,write,*) 函数的主要功能是,向文件描述符 fd 指定的文件写入 count 个字节的数据到缓冲区 buf 中
需要注意一下 #define __LIBRARY__ 这个宏定义,这里定义 直接原因 是为了包括在 unistd.h 中的内嵌汇编代码。
3. 库函数扩展汇编宏
因为 _syscall3 这个函数定义在 /include/unistd.h 中,来看下源码(linux-0.12/linux-0.12/include/unistd.h at master · sumumm/linux-0.12 (github.com)):
// /include/unistd.h
#ifdef __LIBRARY__ # 若提前定义__LIBRARY__,则以后内容被包含
...
#define __NR_write 4 //系统调用号,用作系统调用函数表中索引值
...
//定义有 3 个參数的, 定义系统调用嵌入式汇编宏函数
//%0 - eax(__res),%1 - eax(__ NR_name),%2 - ebx(a),%3 - ecx(b),%4 - edx(c)。
#define _syscall3(type,name,atype,a,btype,b,ctype,c) \
type name(atype a,btype b,ctype c) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \ // 调用系统中断 0x80
: "=a" (__res) \ // 返回值 eax(__res)
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \ //输入为:系统中断调用号__NR_name, 还有另外 3 个参数
if (__res>=0) \ // 如果返回值 >= 0,则直接返回该值
return (type) __res; \
errno=-__res; \ // 否则置出错号,并返回-1
return -1; \
}
#endif /* __LIBRARY__ */
...
int write(int fildes, const char * buf, off_t count); //write 系统调用的函数原型定义
...只有在 lib/write.c 中先定义了 #define __LIBRARY__,那么才能在 /include/unistd.h 中,找到系统调用号和内嵌汇编 _syscall3();不然就代表它不需要进行系统调用,这样就可以忽略 unistd.h 中和系统调用相关的宏定义。其实我们可以把 write.c 中的 write 函数再重新整合一下:
int write(int fd,const char* buf,off_t count) \
{ \
long __res; \
__asm__ volatile ( "int $0x80" \
: "=a" (__res) \
: "" (__NR_write), "b" ((long)(fd)), "c" ((long)(buf)), "d" ((long)(count))); \
if (__res>=0) \
return (type) __res; \
errno=-__res; \
return -1; \
}这样就能更容易明白 #define __LIBRARY__ 的作用。上面 int $0x80" 表示调用 **系统中断 0x80 ** ,其实 系统调用的本质还是通过中断(0x80)去实现的!
另外由于程序处于用户态无法直接操作硬件资源,所以需要进行 系统调用,切换到内核态;也就是说用户程序如果使用库函数 write,会进行系统调用。而系统调用,其实就是去调用 int 0x80 中断,然后把三个参数 fd、buf、count 依次存入 ebx、ecx、edx 寄存器。还有 #define __NR_write 4 ,定义了 系统调用号;_NR_write 会被存入 eax 寄存器;当调用返回后,从 eax 取出返回值,存入 __res,建立了用户栈和内核栈的联系。至于 __NR_write 的作用后面再学习。
4. int 0x80 中断 调用对应的中断处理函数
我们来看下中断是调用对应的中断处理函数的流程图:
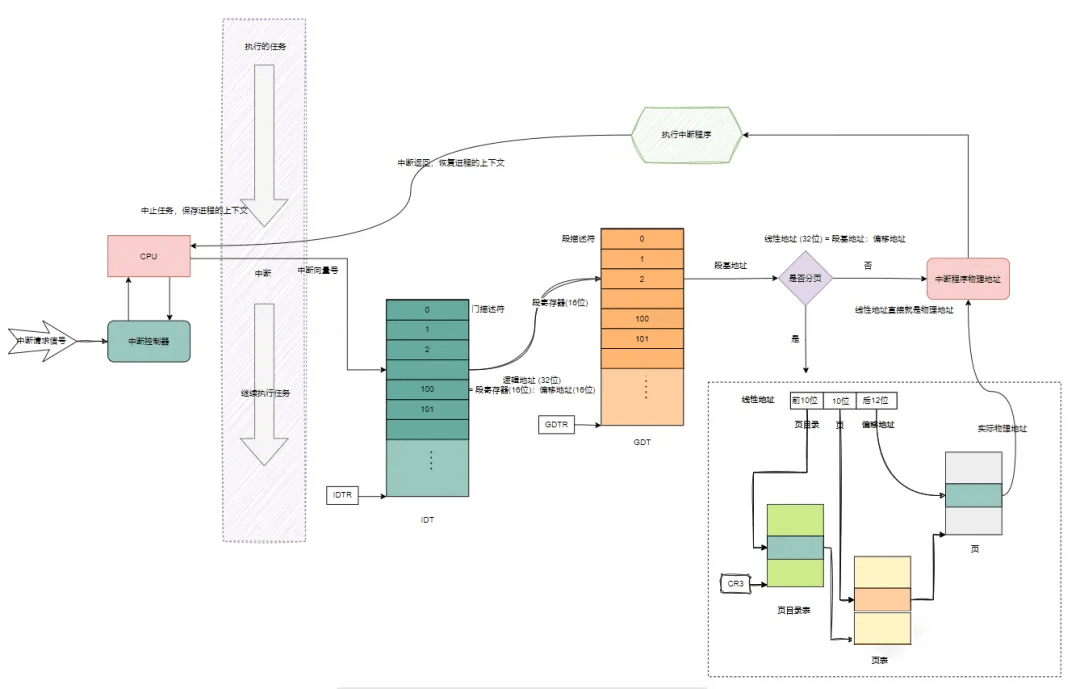
当发生中断的时候,CPU 获取到中断向量号后,通过 IDTR,去查找 IDT 中断描述符表,得到相应的中断描述符;然后根据描述符中的对应中断处理程序的入口地址,去执行中断处理程序.
早在 linux0.12 启动时,会进行调度程序初始化 main.c/sched_init(),其源码(linux-0.12/linux-0.12/kernel/sched.c at master · sumumm/linux-0.12 (github.com)):
// /kernel/sched.c
...
void sched_init(void)
{
...
set_system_gate(0x80,&system_call);//设置系统调用中断门
}
...需要注意的是:在用户态和内核态运行的进程使用的栈是不同的,分别叫做 用户栈和内核栈, 两者各自负责相应特权级别状态下的函数调用;所以当执行系统调用中断 int 0x80 从用户态进入内核态时,会 从用户栈切换到内核栈,系统调用返回时,还要切换回用户栈,继续完成用户态下的函数调用(这也叫做被中断进程上下文的保存与恢复)。
其中其关键作用的是,CPU 会可以自动通过 TR 寄存器找到当前进程的 TSS,然后根据里面 ss0 和 esp0 的值找到内核栈的位置,完成用户栈到内核栈的切换。
set_system_gate(0x80,&system_call) 这句整体作用是,设置系统调用中断门,将 0x80 中断和函数 system_call 绑定在一起,换句话说 system_call 就是 0x80 的中断处理函数。
5. 检索系统调用函数表
我们接着去看 system_call 函数的源码(linux-0.12/linux-0.12/kernel/sys_call.s at master · sumumm/linux-0.12 (github.com)):
// /kernel/sys_call.s
...
// int 0x80
_system_call:
push %ds # 压栈, 保存原段寄存器值
push %es
push %fs
pushl %eax # 保存eax原值
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call, ebx,ecx,edx 中放着系统调用对应的C语言函数的参数
movl $0x10,%edx # ds,es 指向内核数据段
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs 指向当前局部数据段(局部描述符表中数据段描述符)
mov %dx,%fs
cmpl _NR_syscalls,%eax # 判断eax是否超过了最大的系统调用号,调用号如果超出范围的话就跳转!
jae bad_sys_call
call _sys_call_table(,%eax,4) # 间接调用指定功能C函数!
pushl %eax # 把系统调用的返回值入栈!
...
ret_from_sys_call: #当系统调用执行完毕之后,会执行此处的汇编代码,从而返回用户态
movl _current,%eax # 取当前任务(进程)数据结构指针->eax
cmpl _task,%eax # task[0] cannot have signals
...其中 _sys_call_table(,%eax,4),这里的 eax 寄存器存放的就是 _NR_write 系统调用号,_sys_call_table 是 sys.h 中的一个 int (*)() 类型的数组,里面存的是所有的系统调用函数地址,也叫做 系统调用函数表,所以 __NR_write 也表示系统调用函数表中的索引值。
那为什么 %eax * 4 乘上 4 呢?这是因为 sys_call_table[] 指针每项 4 个字节,这样被调用处理函数的地址 = [_sys_call_table + %eax * 4]。
我们再来看下 sys_call_table 的定义(linux-0.12/linux-0.12/include/linux/sys.h at master · sumumm/linux-0.12 (github.com)):
// /include/linux/sys.h
...
extern int sys_write();
...
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid, sys_sigsuspend, sys_sigpending, sys_sethostname,
sys_setrlimit, sys_getrlimit, sys_getrusage, sys_gettimeofday,
sys_settimeofday, sys_getgroups, sys_setgroups, sys_select, sys_symlink,
sys_lstat, sys_readlink, sys_uselib };
//系统调用总数目, 注意一下:这里相较于 linux0.11 做了改进,新增系统调用不再需要手动调整该数目!
int NR_syscalls = sizeof(sys_call_table)/sizeof(fn_ptr);可以知晓这里的 call _sys_call_table(,%eax,4) 就是调用系统调用号所对应的内核系统调用函数 sys_write。
6. 最终执行 sys_write
sys_write 在 fs 下的 read_write.c(linux-0.12/linux-0.12/fs/read_write.c at master · sumumm/linux-0.12 (github.com)):
// /fs/read_write.c
// 写文件系统调用
int sys_write(unsigned int fd,char * buf,int count)
{
struct file * file;
struct m_inode * inode;
//判断函数参数的有效性
if (fd>=NR_OPEN || count <0 || !(file=current->filp[fd]))
return -EINVAL;
if (!count)
return 0;
// 取文件相应的 i 节点
inode=file->f_inode;
// 若是管道文件,并且是写管道文件模式,则进行写管道操作
if (inode->i_pipe)
return (file->f_mode&2)?write_pipe(inode,buf,count):-EIO;
//如果是字符设备文件,则进行写字符设备操作
if (S_ISCHR(inode->i_mode))
return rw_char(WRITE,inode->i_zone[0],buf,count,&file->f_pos);
// 如果是块设备文件,则进行块设备写操作
if (S_ISBLK(inode->i_mode))
return block_write(inode->i_zone[0],&file->f_pos,buf,count);
// 若是常规文件,则执行文件写操作
if (S_ISREG(inode->i_mode))
return file_write(inode,file,buf,count);
printk("(Write)inode->i_mode=%06o\n\r",inode->i_mode);
return -EINVAL;
}至此库函数 write,进行系统调用,最终调用了 sys_write 这个函数。
7. 总结
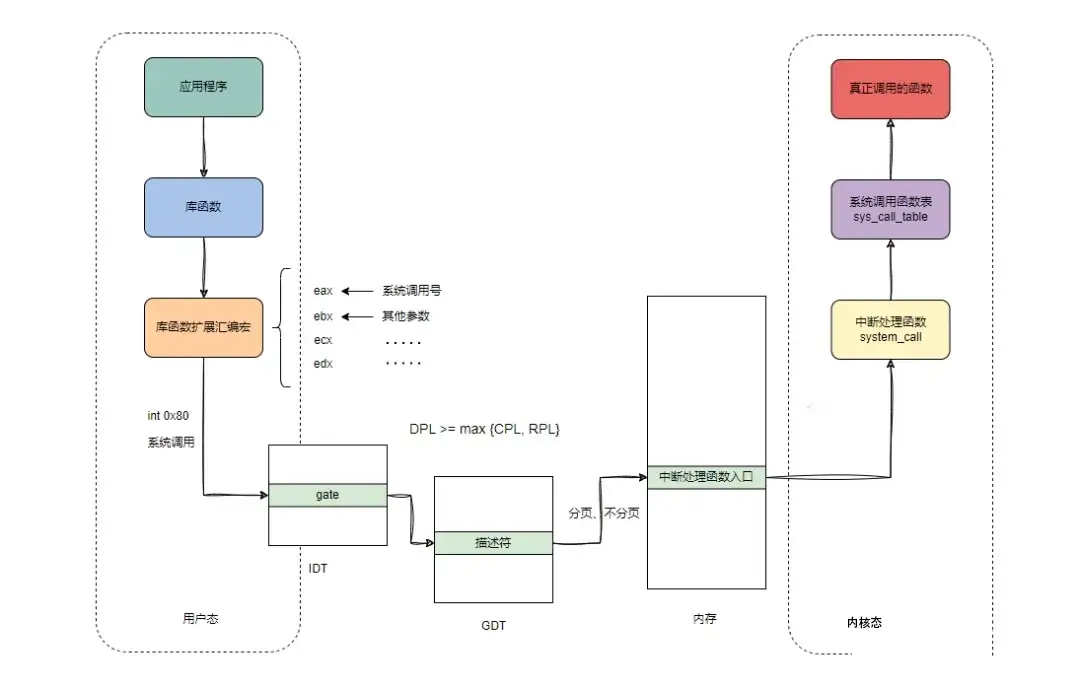
五、内核态与用户态数据交互
到这里我们已经了解了系统调用的过程,还遗留一个问题需要去解决一下,就是内核态与用户态如何进行数据交互?回顾系统调用过程中,我们可以发现 寄存器 在其中起到了不可或缺的作用,linus 在 linux0.12 中也是采用类似的方法来进行数据交互。
我们这里继续以 sys_write 函数为例,来看看里面的 file_write(inode,file,buf,count);,linux-0.12/linux-0.12/fs/file_dev.c at master · sumumm/linux-0.12 (github.com):
// /fs/file_dev.c
// 写文件函数 - 根据 i 节点和文件结构信息,将用户数据写入文件中
int file_write(struct m_inode * inode, struct file * filp, char * buf, int count)
{
off_t pos;
int block,c;
struct buffer_head * bh;
char * p;
int i=0;
/*
* ok, append may not work when many processes are writing at the same time
* but so what. That way leads to madness anyway.
*/
//如果设置了追加标记位,则更新当前位置指针到文件最后一个字节
if (filp->f_flags & O_APPEND)
pos = inode->i_size;
else
pos = filp->f_pos;
// i 为已经写入的长度,count 为需要写入的长度
while (i<count) {
// 先取文件数据块号,如果没有则创建一个块
if (!(block = create_block(inode,pos/BLOCK_SIZE)))
break;
if (!(bh=bread(inode->i_dev,block)))
break;
c = pos % BLOCK_SIZE;
p = c + bh->b_data;// 开始写入数据的位置
bh->b_dirt = 1; //标记数据需要回写硬盘
c = BLOCK_SIZE-c; //算出能写的长度
if (c > count-i) c = count-i;
pos += c;
if (pos > inode->i_size) {
inode->i_size = pos;
inode->i_dirt = 1;
}
i += c;
while (c-->0)
*(p++) = get_fs_byte(buf++);//从用户态拷贝一个字节的数据到内核态
brelse(bh);
}
//当数据已经全部写入文件或者在写操作过程中发生问题时就会退出循环
inode->i_mtime = CURRENT_TIME;
if (!(filp->f_flags & O_APPEND)) {
filp->f_pos = pos;
inode->i_ctime = CURRENT_TIME;
}
return (i?i:-1);
}我们这里不详细看了,把目光聚焦于 get_fs_byte 函数,我们来看下其源码(linux-0.12/linux-0.12/include/asm/segment.h at master · sumumm/linux-0.12 (github.com)):
// include/asm/segment.h
// 读取 fs 段中指定地址处的字节。
// 参数:addr - 指定的内存地址。
// %0 - (返回的字节_v);%1 - (内存地址 addr)。
// 返回:返回内存 fs: [addr] 处的字节。
// 第 3 行定义了一个寄存器变量_v,该变量将被保存在一个寄存器中,以便于高效访问和操作。
extern inline unsigned char get_fs_byte(const char * addr)
{
unsigned register char _v;
__asm__ ("movb %%fs:%1,%0":"=r" (_v):"m" (*addr));
return _v;
}
// 将一字节存放在 fs 段中指定内存地址处。
// 参数:val - 字节值;addr - 内存地址。
// %0 - 寄存器(字节值 val);%1 - (内存地址 addr)。
extern inline void put_fs_byte(char val,char *addr)
{
__asm__ ("movb %0,%%fs:%1"::"r" (val),"m" (*addr));
}get_fs_byte 函数是从用户态拷贝一个字节的数据到内核态,而 put_fs_byte 则恰恰相反,从内核态拷贝一个字节的数据到用户态。在系统调用运行整个过程中,DS 和 ES 段寄存器指向内核数据空间,而 FS 段寄存器被设置为指向用户数据空间,这为啥?我们来看在 /kernel/sys_call.s(linux-0.12/linux-0.12/kernel/sys_call.s at master · sumumm/linux-0.12 (github.com))中 _system_call 中的这段:
_system_call:
...
movl $0x10,%edx # ds,es 指向内核数据段
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs 指向当前局部数据段(局部描述符表中数据段描述符)
mov %dx,%fs
...0x10 是全局描述符表 GDT 中 内核数据段描述符 的段值,0x17 是 局部描述符表 LDT 中的任务的数据段描述符 的段值,所以 linux 这里利用 FS 寄存器来完成 内核数据空 间与 用户数据空间 之间的数据复制,当进程从中断调用中退出时,寄存器会自动从内核栈弹出,快捷高效。