
LV105-字符的编码
一、编码与字体
我的另一个文档库中会有一篇笔记说这个编码与字体,但是现在还没整理,后续再更新。在原来的文档中是《01 嵌入式开发/01HQ 课程体系/LV16-STM32 开发/LV16-26-LCD-05-字符编码.md》
二、指定编码格式
在 C 源文件中要是有中文的话,这个中文的编码方式是 GB2312 还是 UTF-8?编译出的可执行程序,其中的汉字编码方式是 GB2312 还是 UTF-8?
注意:一般不会使用 UTF-16 的编码方式,在这种方式下 ASCII 字符也是用 2 字节来表示,而其中一个字节是 0,但是在 C 语言中 0 表示字符串的结束符,会引起误会。
我们编写 C 程序时,可以使用 ANSI 编码,或是 UTF-8 编码;在编译程序时,可以使用以下的选项告诉编译器:
-finput-charset=GB2312
-finput-charset=UTF-8如果不指定“ -finput-charset”, GCC 就会默认 C 程序的编码方式为 UTF-8,即使我们是以 ANSI 格式保存,也会被当作 UTF-8 来对待。
对于编译出来的可执行程序,可以指定它里面的字符是以什么方式编码,可以使用以下的选项来告诉编译器:
-fexec-charset=GB2312
-fexec-charset=UTF-8如果不指定“ -fexec-charset”, GCC 就会默认编译出的可执行程序中字符的编码方式为 UTF-8。
如果“ -finput-charset”与“-fexec-charset”不一样,编译器会进行格式转换。
三、编码格式实验
1. 准备两个文件
我们准备两个文件,内容都是这样的:
#include <stdio.h>
#include <string.h>
int main(int argc, char **argv)
{
char *str = "A中";
int i;
printf("str's len = %d\n", (int)strlen(str));
printf("Hex code: ");
for (i = 0; i < strlen(str); i++)
{
printf("%02x ", (unsigned char)str[i]);
}
printf("\n");
return 0;
}一个名为 file_set_ansi.c,编码格式为 ANSI:
另一个命名为 file_set_utf8.c:
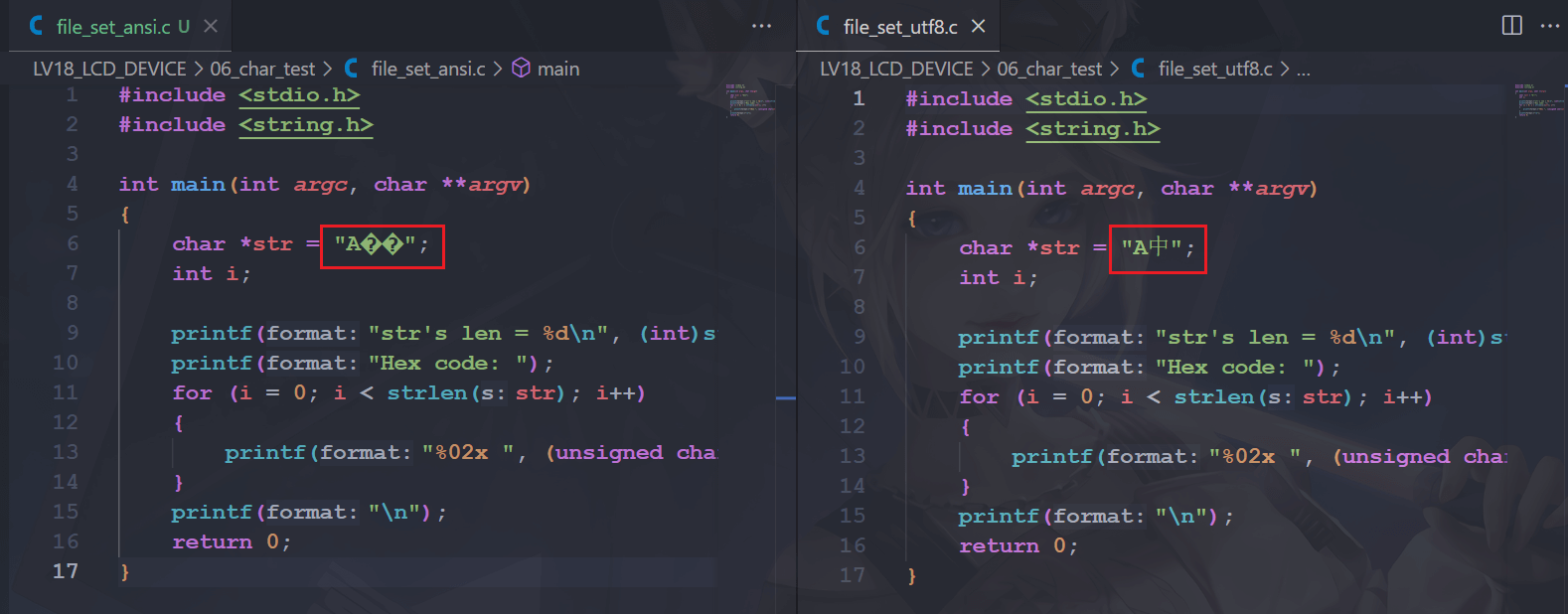
然后在 VScode 打开的时候是这样的:
2. 默认编码
我们不指定不指定“-finput-charset”与“ -fexec-charset”时, 编译上面两个文件并执行:
gcc -o file_set_ansi file_set_ansi.c
./file_set_ansi
gcc -o file_set_utf8 file_set_utf8.c
./file_set_utf8
由于 input-charset 和 exec-charset 默认都是 UTF-8,不会进行编码转换。即使 C 文件是 ANSI,也会被认为是 UTF-8,所以不会导致编码转换。
3. GB2312 转为 UTF-8
gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o file_set_ansi file_set_ansi.c
./file_set_ansi
gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o file_set_utf8 file_set_utf8.c
./file_set_utf8
从上面的输出信息可以看出来, GB2312 的“0xd6 0xd0”可以转换为 UTF-8 的“ 0xe4 0xb8 0xad”。而如果把原本就是 UTF-8 格式的 file_set_utf8.c 当作 GB2312 格式,会引起错误。
4. UTF-8 转为 GB2312
gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o file_set_ansi file_set_ansi.c
./file_set_ansi
gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o file_set_utf8 file_set_utf8.c
./file_set_utf8
从上面的输出信息可以看出来,如果把原本就是 GB2312 格式的 file_set_ansi.c 当作 UTF-8 格式,会引起错误。而 UTF-8 格式的“中”编码值为“ 0xe4 0xb8 0xad”,可以转换为 GB2312 的“0xd6 0xd0”。在代码中使用汉字这类非 ASCII 码时,要特别留意编码格式 。
四、C 语言中的 wchar_t 类型
要显示一个字符,首先要确定它的编码值。常用的是 UNICODE 编码,在程序里使用这样的语句定义字符串时, str 中保存的要么是 GB2312 编码值,要么是 UTF-8 格式的编码值,即使编译时使用“ -fexec-charset = UTF-8”, str 中保存的也不是直接能使用的 UNICODE 值:
char *str = “中”;如果想在代码中能直接使用 UNICODE 值,需要使用 wchar_t,宽字符类型:
#include <stdio.h>
#include <string.h>
#include <wchar.h>
int main( int argc, char** argv)
{
wchar_t *chinese_str = L"中 gif";
unsigned int *p = (wchar_t *)chinese_str;
int i;
printf("sizeof(wchar_t) = %d, str's Uniocde: \n", (int)sizeof(wchar_t));
for (i = 0; i < wcslen(chinese_str); i++)
{
printf("0x%x ", p[i]);
}
printf("\n");
return 0;
}我们编译运行一下:
gcc -o wchar wchar.c
每个 wchar_t 占据 4 字节,可执行程序里 wchar_t 中保存的就是字符的 UNICODE 值。
注意:如果 wchar.c 是以 ANSI(GB2312)格式保存,那么需要使用以下命令来编译:
gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o wchar wchar.c