
LV090-工作队列-传参与并发管理
一、工作队列传参
前面学习的 tasklet 可以给中断下文传参, 如果我们使用工作队列来实现中断的下半部分, 那么如何用工作队列给中断下文传参呢?
1. 通过工作项
在 Linux 内核的工作队列中, 可以通过使用工作项的方式向工作队列传递参数。 工作项是一个抽象的结构, 可以用于封装需要执行的工作及其相关的参数。
- (1)首先我们定义工作项结构
如下所示, 在结构体 struct work_data 中定义了需要传递给工作项处理函数的参数 a 和 b, 然后定义一个类型为 struct work_data 的变量 test_workqueue_work。
struct work_data {
int a;
int b;
struct work_struct test_work;
};
struct work_data test_workqueue_work;- (2)接下来在模块初始化函数 interrupt_irq_init 中创建了一个工作队列 test_workqueue 和一个工作项 test_workqueue_work。
test_workqueue = create_workqueue("test_workqueue"); // 创建工作队列
INIT_WORK(&test_workqueue_work.test_work, test_work); // 初始化工作项- (3)然后在模块初始化函数中, 为工作项的参数 a 和 b 赋值。
test_workqueue_work.a = 1;
test_workqueue_work.b = 2;- (4)当中断触发时, 在中断处理函数 test_interrupt 中, 通过调用 queue_work 函数将工作项 test_workqueue_work.test_work 提交到工作队列 test_workqueue 中。
queue_work(test_workqueue, &test_workqueue_work.test_work);- (5)然后工作项处理函数 test_work 定义了一个指针 pdata, 将工作项转换为 struct work_data 结构, 并通过该结构访问参数 a 和 b。 如下所示:
void test_work(struct work_struct *work)
{
struct work_data *pdata;
pdata = container_of(work, struct work_data, test_work);
printk("a is %d\n", pdata->a);
printk("b is %d\n", pdata->b);
}这样, 当工作队列被调度执行时, 工作项处理函数 test_work 将能够访问到传递给工作项的参数 a 和 b, 并在内核日志中打印他们的值。
Tips:注意, 工作项处理函数中的 container_of 宏用于从工作项结构的指针获取整个 struct work_data 结构的指针。 这样可以通过指针偏移来访问工作项结构中的其他字段, 例如参数 a 和 b。
2. 工作队列传参 demo
2.1 demo 源码
demo 源码可以看这里:13_interrupt/10_nodts_workqueue_custom_param
2.2 开发板测试
我们拷贝驱动到开发板中,加载驱动:
insmod sdriver_demo.ko
然后按下按键再抬起,可以看到如下打印信息:

我这里是这样赋值的:
p_chrdev->irq_key.key_work.a = p_chrdev->irq_key.gpio;
p_chrdev->irq_key.key_work.b = p_chrdev->irq_key.irq_num;所以打印出来的就是 gpio 引脚号和中断号。
二、并发管理工作队列
在现代的软件开发中, 我们常常面临着需要同时处理多个任务的挑战。 这些任务可能是并行的、 独立的, 或者需要以某种顺序进行处理。 为了高效地管理这些并发任务, 我们需要一种有效的机制来协调它们的执行。 这就是并发管理工作队列发挥作用的地方。
1. 工作队列的实现
前面,我们学习了共享工作队列和自定义工作队列, 在使用工作队列时,我们首先定义一个 work 结构体, 然后将 work 添加到 workqueue(工作队列)中, 最后 worker thread 执行 workqueue。 当工作队列中有新 work 产生时, 工作线程(worker thread) 会执行工作队列中每个 work。 当执行完结束的时候, worker thread 会睡眠, 等到新的中断产生, work 再继续添加到工作队列, 然后工作线程执行每个工作, 周而复始。
在单核线程的系统中, 通常会为每个 CPU(核心) 初始化一个工作线程并关联一个工作队列。 这种默认设置确保每个 CPU 都有一个专门的线程来处理与其绑定的工作队列上的工作项。 如下图 :

在多核线程系统中, 工作队列的设计与单核线程系统有所不同。 在多核线程系统中, 通常会存在多个工作队列, 每个工作队列与一个工作线程(Worker Thread) 绑定。 这样可以充分利用多个核心的并行处理能力。 如下图 :

当有新的工作项产生时, 系统需要决定将其分配给哪个工作队列。 一种常见的策略是使用负载均衡算法, 根据工作队列的负载情况来平衡分配工作项, 以避免某个工作队列过载而导致性能下降。 每个工作队列独立管理自己的工作项。 当有新的工作项添加到工作队列时, 工作线程会从其关联的工作队列中获取待执行的工作项, 并执行相应的处理函数。 在多核线程系统中,多个工作线程可以同时执行各自绑定的工作队列中的工作项。 这样可以实现并行处理, 提高系统的整体性能和响应速度。
2. workqueue 队列弊端
了解了工作队列是如何实现的, 接下来我们看看传统的工作队列有什么弊端呢?假如说有三个 work 放到了同一个工作队列上, 接下来 CPU 会启动工作线程去执行这三个 work, 如下图 :
| TIME | EVENT |
| 0 | w0 starts and burns CPU |
| 5 | w0 sleeps |
| 15 | w0 wakes up and burns CPU |
| 20 | w0 finishes |
| 20 | w1 starts and burns CPU |
| 25 | w1 sleeps |
| 35 | w1 wakes up and finishes |
| 35 | w2 starts and burns CPU |
| 40 | w2 sleeps |
| 50 | w2 wakes up and finishes |
(1)在工作项 w0 工作甚至是睡眠时, 工作项 w1 w2 是排队等待的, 在繁忙的系统中, 工作队列可能会积累大量的待处理工作项, 导致任务调度的延迟, 这可能会影响系统的响应性能,并增加工作项的处理时间。
(2)在工作队列中, 不同的工作项可能具有不同的处理时间和资源需求。 如果工作项的处理时间差异很大, 一些工作线程可能会一直忙于处理长时间的工作项, 而其他工作线程则处于空闲状态, 导致资源利用不均衡。
(3)在多线程环境下, 多个工作线程同时访问和修改工作队列可能会导致竞争条件的发生。为了确保数据的一致性和正确性, 需要采用适当的同步机制, 如锁或原子操作, 来保护共享数据, 但这可能会引入额外的同步开销。
(4)工作队列通常按照先进先出(FIFO) 的方式处理工作项, 缺乏对工作项优先级的细粒度控制。 在某些场景下, 可能需要根据工作项的重要性或紧急程度进行优先级调度, 而工作队列本身无法提供这种级别的优先级控制。
(5)当工作线程从工作队列中获取工作项并执行时, 可能需要频繁地进行上下文切换, 将处理器的执行上下文从一个线程切换到另一个线程。 这种上下文切换开销可能会影响系统的性能和效率。
3. 什么是并发管理工作队列?
通过上面的了解,我们认识到传统的工作队列无论是单核系统还是多核系统上都是有缺陷的。 比如无法充分利用多核处理器的计算能力以及对于不同优先级的工作项无法提供公平的调度。 为了解决这些问题, Con Kolivas 提出了 CMWQ 调度算法。
CMWQ 全称是 concurrency Managed Workqueue, 意为并发管理工作队列。 并发管理工作队列是一种并发编程模式, 用于有效地管理和调度待执行的任务或工作项。 它通常用于多线程或多进程环境中, 以实现并发执行和提高系统的性能。 CMWQ 工作实现如下图 :
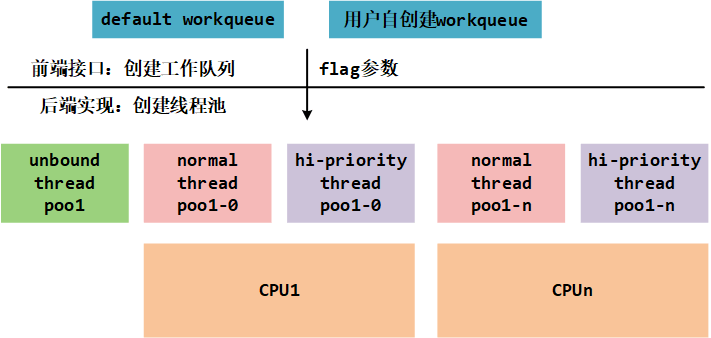
当我们需要在一个系统中同时处理多个任务或工作时, 使用并发管理工作队列是一种有效的方式。
想象一下, 我们是一个餐厅的服务员, 有很多顾客同时来到餐厅用餐。 为了提高效率, 我们需要将顾客的点菜请求放到一个队列中, 这就是工作队列。 然后, 我们和其他服务员可以从队列中获取顾客的点菜请求, 每个服务员独立地为顾客提供服务。 通过这种方式, 我们可以并发地处理多个顾客的点菜请求, 而不需要等待上一个顾客点完菜再去处理下一个顾客的请求。 每个服务员可以独立地从队列中获取任务, 并根据需要执行相应的服务。 这种独立获取任务的过程就是从工作队列中取出任务并执行的过程。
通过并发管理工作队列, 我们能够更高效地处理顾客的点菜请求, 提高服务的速度和质量。同时, 这种方式也能够更好地利用我们的工作能力, 因为每个服务员都可以独立处理任务, 而不会相互干扰或等待。
总的来说, 通过并发管理工作队列, 我们可以同时处理多个任务或工作, 提高系统的并发性和性能。 每个任务独立地从队列中获取并执行, 这种解耦使得整个系统更加高效、 灵活, 并且能够更好地应对多任务的需求。
4. 相关的 api
4.1 alloc_workqueue()
alloc_workqueue() 是 Linux 内核中的一个函数, 用于创建和分配一个工作队列。 工作队列是一种用于管理和调度工作项的机制, 可用于实现并发处理和异步任务处理。
#ifdef CONFIG_LOCKDEP
#define alloc_workqueue(fmt, flags, max_active, args...) \
({ \
static struct lock_class_key __key; \
const char *__lock_name; \
\
__lock_name = "(wq_completion)"#fmt#args; \
\
__alloc_workqueue_key((fmt), (flags), (max_active), \
&__key, __lock_name, ##args); \
})
#else
#define alloc_workqueue(fmt, flags, max_active, args...) \
__alloc_workqueue_key((fmt), (flags), (max_active), \
NULL, NULL, ##args)
#endif【参数说明】
- fmt: 指定工作队列的名称格式。
- flags: 指定工作队列的标志, 可以控制工作队列的行为和属性, 如 WQ_UNBOUND 表示无绑定的工作队列, WQ_HIGHPRI 表示高优先级的工作队列等。
- max_active: 指定工作队列中同时活跃的最大工作项数量。
【返回值】返回一个指向工作队列结构体(struct workqueue_struct) 的指针, 或者返回 NULL 表示创建失败。
5. 并发管理工作队列 demo
5.1 demo 源码
demo 源码可以看这里:13_interrupt/11_nodts_workqueue_custom_cmwq
5.2 开发板测试
这个 demo 的现象并不是很明显,这里先大概了解一下:

参考资料: