
LV020-工作机制
这一节我们来了解一下内核模块的工作机制。
一、ko 文件的格式
1. ELF 文件格式
ko 文件在数据组织形式上是 ELF(Excutable And Linking Format)格式,是一种普通的可重定位目标文件。 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。ELF 文件格式的可能布局如下图:
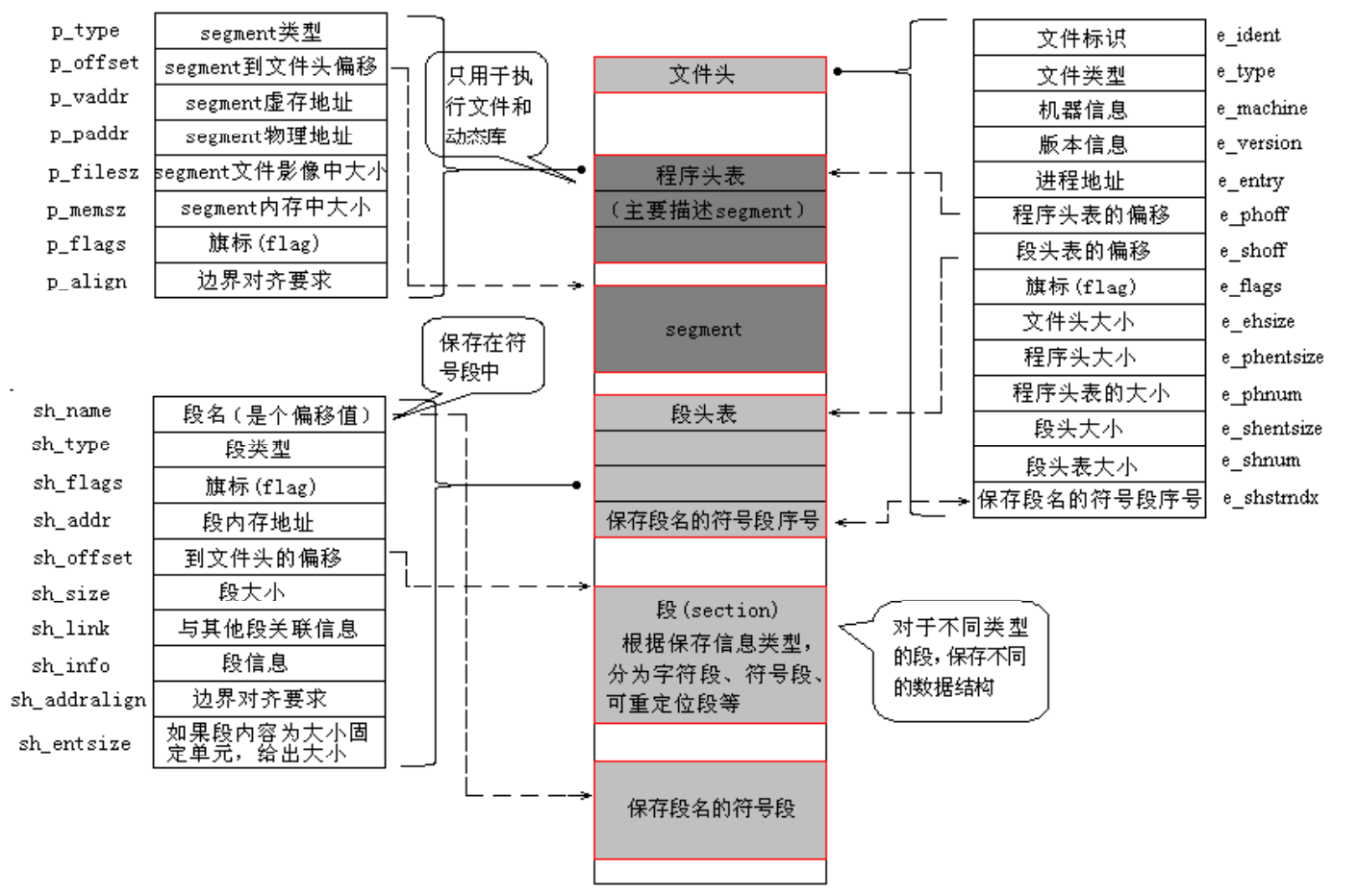
文件开始处是一个 ELF 头部(ELF Header),用来描述整个文件的组织,这些信息独立于处理器, 也独立于文件中的其余内容。详细分析可以看这里:ELF 文件格式分析 (gitee.com)
2. 头部信息
我们在 ubuntu 中可使用 readelf 工具查看 elf 文件的头部信息:
readelf -h hello_world_demo.ko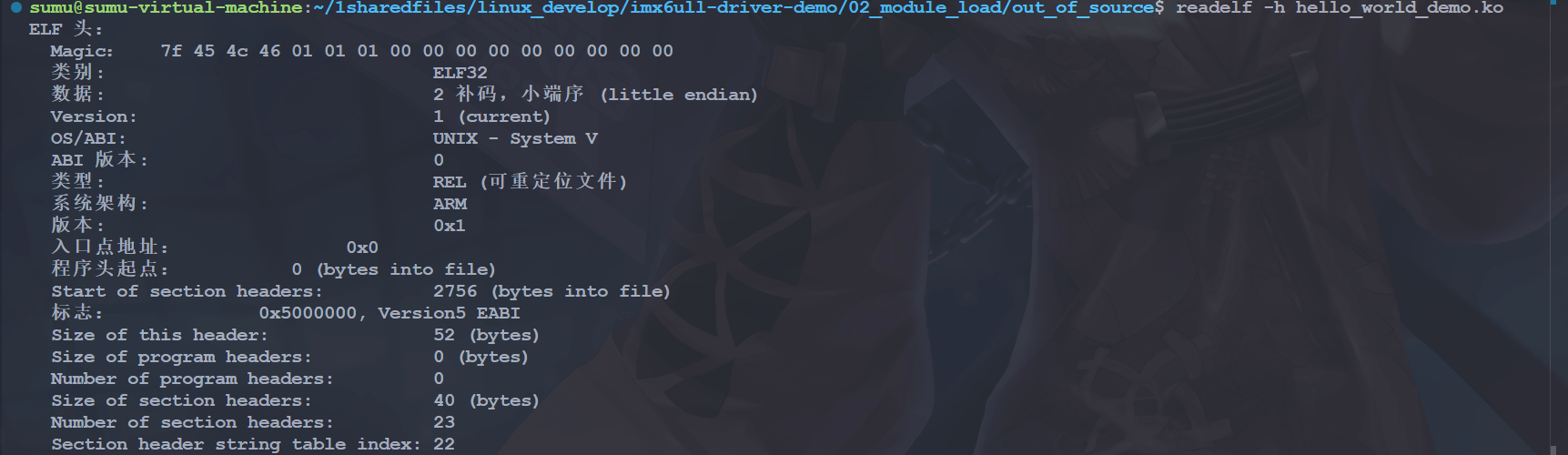
程序头部表(Program Header Table)是个数组结构,它的每一个元素的数据结构如下每个数组元素表示:
- 一个”段”:包含一个或者多个”节区”,程序头部仅对于可执行文件和共享目标文件有意义
- 其他信息:系统准备程序执行所必需的其它信息”
节区头部表/段表(Section Heade Table) ELF 文件中有很多各种各样的段,这个段表(Section Header Table)就是保存这些段的基本属性的结构, ELF 文件的段结构就是由段表决定的,编译器、链接器、装载器都是依靠段表来定位和访问各个段的属性的 包含了描述文件节区的信息。
ELF 头部中:
- e_shoff:给出从文件头到节区头部表格的偏移字节数,
- e_shnum:给出表格中条目数目,
- e_shentsize: 给出每个项目的字节数。
3. 节区
从上面哪些信息中可以确切地定位节区的具体位置、长度和程序头部表一样, 每一项节区在节区头部表格中都存在着一项元素与它对应,因此可知,这个节区头部表格为一连续的空间, 每一项元素为一结构体(思考这节开头的那张节区和节区头部的示意图)。我们可以加上-S 参数读取 elf 文件的节区头部表的详细信息。
readelf -S hello_world_demo.ko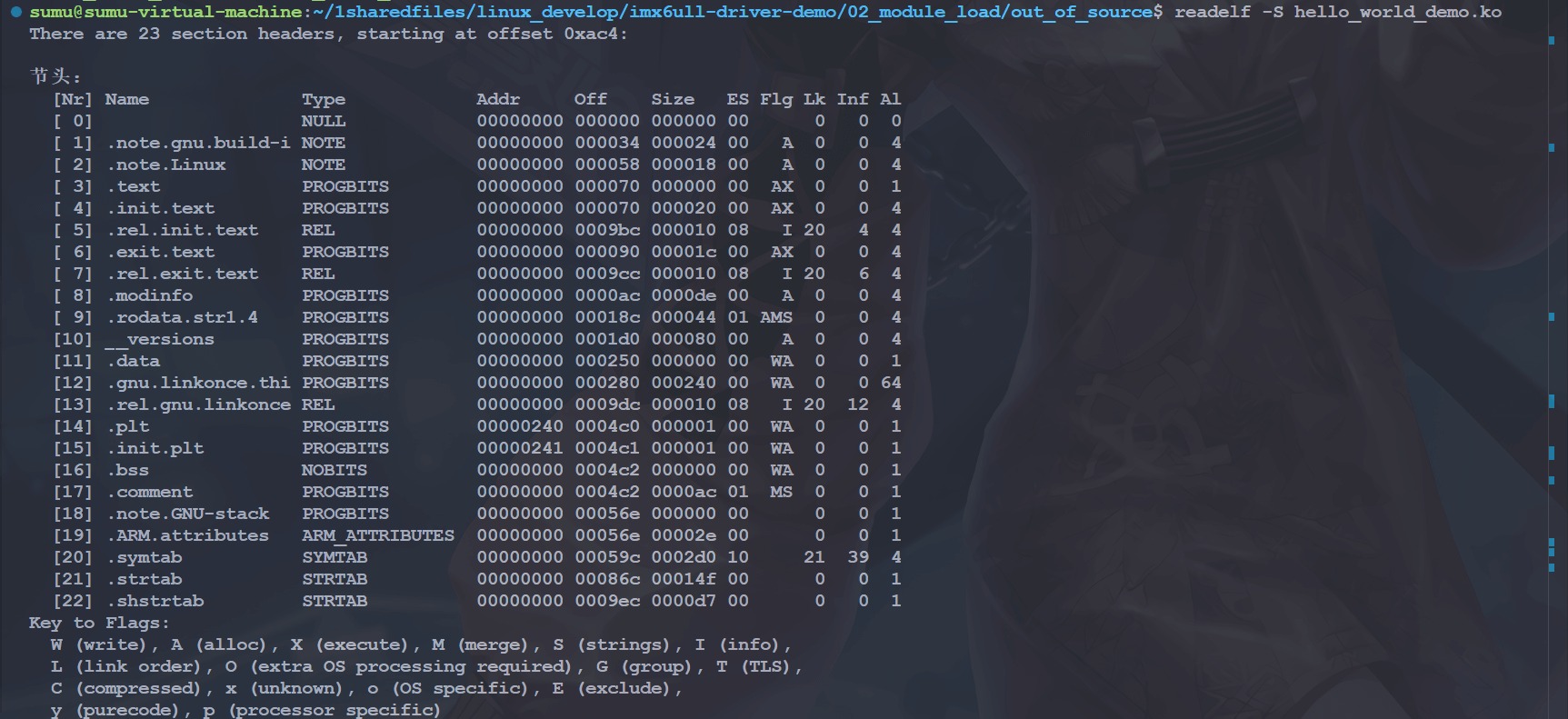
节区头部表中又包含了很多子表的信息,我们简单的来看两个。
3.1 重定位表
重定位表(“.rel.text”)位于段表之后,它的类型为(sh_type)为”SHT_REL”,即重定位表(Relocation Table) 链接器在处理目标文件时,必须要对目标文件中某些部位进行重定位,即代码段和数据段中那些对绝对地址的引用的位置, 这些重定位信息都记录在 ELF 文件的重定位表里面,对于每个须要重定位的代码段或者数据段,都会有一个相应的重定位表 一个重定位表同时也是 ELF 的一个段,这个段的类型(sh_type)就是”SHT_REL”:
readelf -r hello_world_demo.ko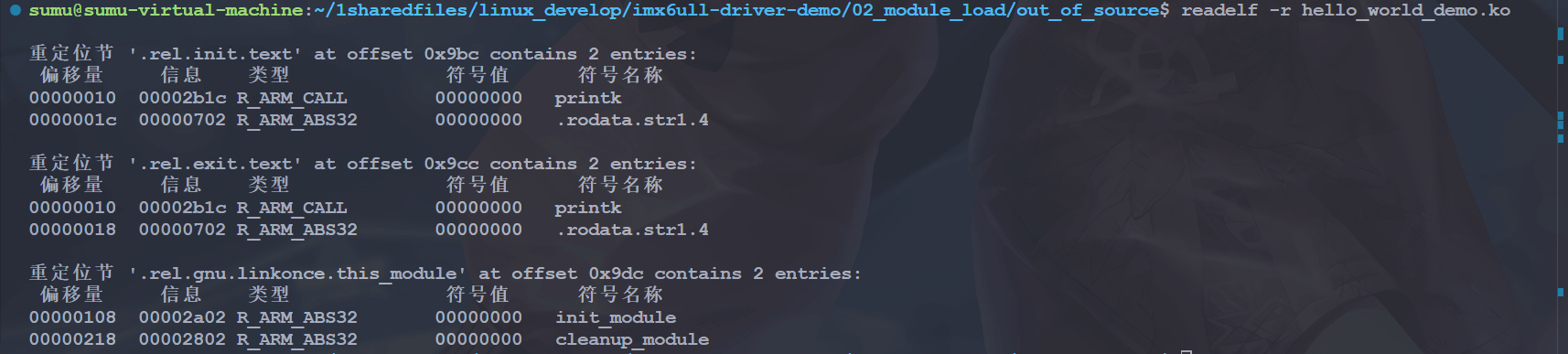
3.2 字符串表
ELF 文件中用到了很多字符串,比如段名、变量名等。因为字符串的长度往往是不定的, 所以用固定的结构来表示比较困难,一种常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。 一般字符串表在 ELF 文件中也以段的形式保存,常见的段名为”.strtab”(String Table 字符串表)或者”.shstrtab”(Section Header String Table 段字符串表)
readelf -p 21 hello_world_demo.ko # 前面.shstrtab 在节头中显示是 21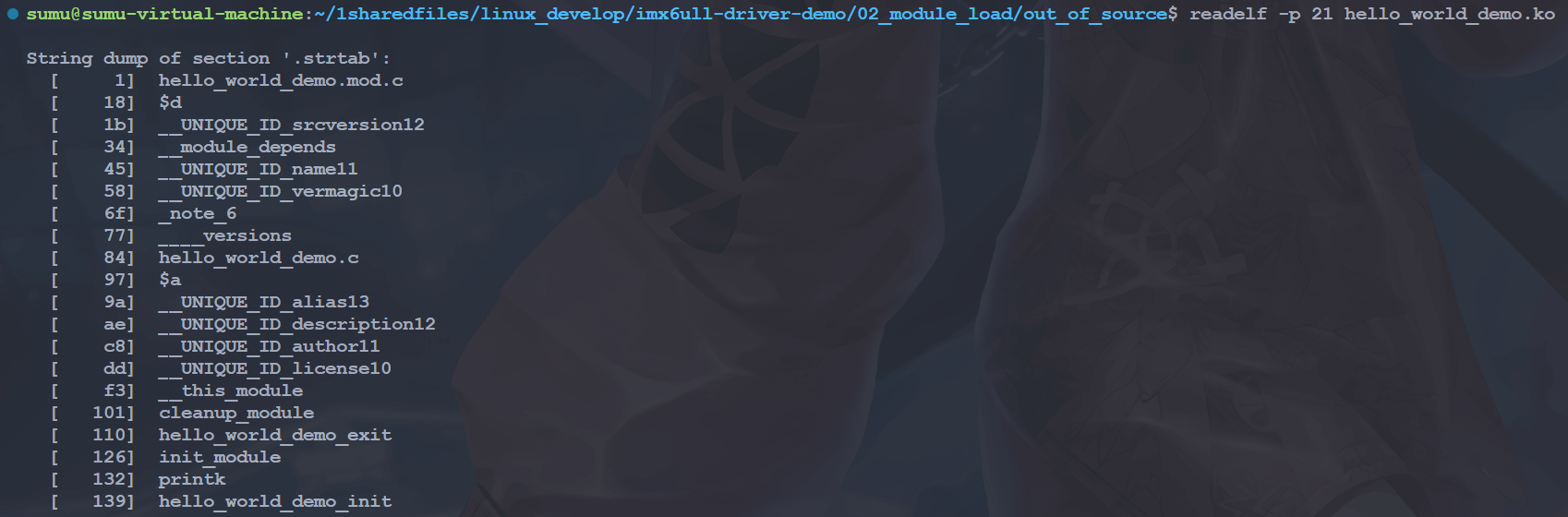
反正我是没咋看懂,就先这样吧,大概了解一下,详细的就看这篇文档:ELF 文件格式分析 (gitee.com)
二、内核模块加载与卸载
在前面我们了解了 ko 内核模块文件的一些格式内容之后, 我们可以知道内核模块其实也是一段经过特殊加工的代码, 那么既然是加工过的代码,内核就可以利用到加工时留在内核模块里的信息, 对内核模块进行利用。所以我们就可以接着了解内核模块的加载过程和卸载过程了。
1. 加载过程
1.1 sys_init_module()
首先 insmod 会通过文件系统将 .ko 模块读到用户空间的一块内存中, 然后执行系统调用 sys_init_module() 解析模组, 这时,内核在 vmalloc 区分配与 ko 文件大小相同的内存来暂存 ko 文件, 暂存好之后解析 ko 文件,将文件中的各个 section 分配到 init 段和 core 段,在 modules 区为 init 段和 core 段分配内存, 并把对应的 section copy 到 modules 区最终的运行地址,经过 relocate 函数地址等操作后,就可以执行 ko 的 init 操作了, 这样一个 ko 的加载流程就结束了。 同时,init 段会被释放掉,仅留下 core 段来运行。
sys_init_module() 函数定义在 module.c - kernel/module.c:
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}- 第 14 行:通过 vmalloc 在 vmalloc 区分配内存空间,将内核模块 copy 到此空间,info→ hdr 直接指向此空间首地址,也就是 ko 的 elf header 。
- 第 18 行:然后通过 load_module()进行模块加载的核心处理,在这里完成了模块的搬移,重定向等过程。
1.2 load_module()
load_module()函数定义在 module.c - kernel/module.c:
/* 分配并加载模块 */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
//...
err = setup_load_info(info, flags);
//...
mod = layout_and_allocate(info, flags);
//...
}- 第 9 行:setup_load_info()加载 struct load_info 和 struct module, rewrite_section_headers,将每个 section 的 sh_addr 修改为当前镜像所在的内存地址, section 名称字符串表地址的获取方式是从 ELF 头中的 e_shstrndx 获取到节区头部字符串表的标号,找到对应 section 在 ELF 文件中的偏移,再加上 ELF 文件起始地址就得到了字符串表在内存中的地址。
- 第 11 行:在 layout_and_allocate()中,layout_sections() 负责将 section 归类为 core 和 init 这两大类, 为 ko 的第二次搬移做准备。move_module()把 ko 搬移到最终的运行地址。内核模块加载代码搬运过程到此就结束了。
2. 卸载过程
卸载过程相对加载比较简单,我们输入指令 rmmod,最终在系统内核中需要调用 sys_delete_module 进行实现。这个函数定义在 module.c - kernel/module.c。
具体过程如下:先从用户空间传入需要卸载的模块名称,根据名称找到要卸载的模块指针, 确保我们要卸载的模块没有被其他模块依赖,然后找到模块本身的 exit 函数实现卸载。
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
audit_log_kern_module(name);
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
if (!list_empty(&mod->source_list)) {
/* Other modules depend on us: get rid of them first. */
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count damn the torpedoes */
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
/* If it has an init func, it must have an exit func to unload */
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
/* Stop the machine so refcounts can't move and disable module. */
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();
blocking_notifier_call_chain(&module_notify_list,
MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}- 第 8 行:确保有插入和删除模块不受限制的权利,并且模块没有被禁止插入或删除
- 第 11 行:获得模块名字。
- 第 20 行:找到要卸载的模块指针。
- 第 26 行:有依赖的模块,需要先卸载它们。
- 第 41 行:检查模块的退出函数。
- 第 51 行:停止机器,使参考计数不能移动并禁用模块。
- 第 59 行:告诉通知链 module_notify_list 上的监听者,模块状态 变为 MODULE_STATE_GOING。
- 第 64 行:等待所有异步函数调用完成。
三、内核是如何导出符号的
1. 模块层叠
符号是什么东西?我们为什么需要导出符号呢?内核模块如何导出符号呢?其他模块又是如何找到这些符号的呢?
实际上,符号指的就是内核模块中使用 EXPORT_SYMBOL 声明的函数和变量。 当模块被装入内核后,它所导出的符号都会记录在公共内核符号表中。 在使用命令 insmod 加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
通常情况下我们无需导出任何符号,但是如果其他模块想要从我们这个模块中获取某些方便的时候, 就可以考虑使用导出符号为其提供服务。这被称为 模块层叠技术。 例如 msdos 文件系统依赖于由 fat 模块导出的符号;USB 输入设备模块层叠在 usbcore 和 input 模块之上。 也就是我们可以将模块分为多个层,通过简化每一层来实现复杂的项目。
modprobe 是一个处理层叠模块的工具,它的功能相当于多次使用 insmod, 除了装入指定模块外还同时装入指定模块所依赖的其他模块。
2. 怎么导出符号?
当我们要导出模块的时候,可以使用下面的宏:
EXPORT_SYMBOL(name)
EXPORT_SYMBOL_GPL(name) //name 为我们要导出的标志符号必须在模块文件的全局部分导出,不能在函数中使用,_GPL 使得导出的模块只能被 GPL 许可的模块使用。 编译我们的模块时,这两个宏会被拓展为一个特殊变量的声明,存放在 ELF 文件中。 具体也就是存放在 ELF 文件的符号表中:
- st_name: 是符号名称在符号名称字符串表中的索引值
- st_value: 是符号所在的内存地址
- st_size: 是符号大小
- st_info: 是符号类型和绑定信息
- st_shndx: 表示符号所在 section
当 ELF 的符号表被加载到内核后,会执行 simplify_symbols 来遍历整个 ELF 文件符号表。 根据 st_shndx 找到符号所在的 section 和 st_value 中符号在 section 中的偏移得到真正的内存地址。 并最终将符号内存地址,符号名称指针存储到内核符号表中。simplify_symbols()函数定义在 module.c - kernel/module.c:
/* Change all symbols so that st_value encodes the pointer directly. */
static int simplify_symbols(struct module *mod, const struct load_info *info)
{
Elf_Shdr *symsec = &info->sechdrs[info->index.sym];
Elf_Sym *sym = (void *)symsec->sh_addr;
unsigned long secbase;
unsigned int i;
int ret = 0;
const struct kernel_symbol *ksym;
for (i = 1; i < symsec->sh_size / sizeof(Elf_Sym); i++) {
const char *name = info->strtab + sym[i].st_name;
switch (sym[i].st_shndx) {
//......
case SHN_UNDEF:
ksym = resolve_symbol_wait(mod, info, name);
/* Ok if resolved. */
if (ksym && !IS_ERR(ksym)) {
sym[i].st_value = kernel_symbol_value(ksym);
break;
}
/* Ok if weak. */
if (!ksym && ELF_ST_BIND(sym[i].st_info) == STB_WEAK)
break;
ret = PTR_ERR(ksym) ?: -ENOENT;
pr_warn("%s: Unknown symbol %s (err %d)\n",
mod->name, name, ret);
break;
default:
/* Divert to percpu allocation if a percpu var. */
if (sym[i].st_shndx == info->index.pcpu)
secbase = (unsigned long)mod_percpu(mod);
else
secbase = info->sechdrs[sym[i].st_shndx].sh_addr;
sym[i].st_value += secbase;
break;
}
}
return ret;
}内核导出的符号表结构有两个字段,一个是符号在内存中的地址,一个是符号名称指针, 符号名称被放在了__ksymtab_strings 这个 section 中, 以 EXPORT_SYMBOL 举例,符号会被放到名为__ksymtab 的 section 中。 这个结构体我们要注意,它构成的表是导出符号表而不是通常意义上的符号表 。
我们来看一下这个 kernel_symbol 结构体,它定义在 export.h - include/linux/export.h:
struct kernel_symbol {
unsigned long value; // 符号在内存中的地址
const char *name; // 符号名称
};其他的内核模块在寻找符号的时候会调用 resolve_symbol_wait 去内核和其他模块中通过符号名称寻址目标符号,resolve_symbol_wait 会调用 resolve_symbol,进而调用 find_symbol。 找到了符号之后,把符号的实际地址赋值给符号表 sym[i].st_value = ksym→ value。find_symbol()函数定义在 module.c - kernel/module.c:
/* Find a symbol and return it, along with, (optional) crc and
* (optional) module which owns it. Needs preempt disabled or module_mutex. */
/* 找到一个符号并将其连同(可选)crc 和(可选)拥有它的模块一起返回。需要禁用抢占或模块互斥。 */
const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const s32 **crc,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
if (each_symbol_section(find_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
EXPORT_SYMBOL_GPL(find_symbol);- 第 16 行:在 each_symbol_section 中,去查找了两个地方,一个是内核的导出符号表,即我们在将内核符号是如何导出的时候定义的全局变量,一个是遍历已经加载的内核模块,查找动作是在 each_symbol_in_section 中完成的。
- 第 27 行:导出符号标志.
至此符号查找完毕,最后将所有 section 借助 ELF 文件的重定向表进行重定向,就能使用该符号了。
参考资料